FPGA置き換え時のデバイス変更で困らないコーディングノウハウ

こんにちは。
本ブログは、弊社が開催している「FPGA置き換えソリューショウェビナー」に関する内容をベースに執筆しており、「デバイス変更の際に困らないコーディングのノウハウ」についてお伝えします。FPGAを置き換える際に、HDLで有効な記述について紹介しています。
今回紹介するコーディングは、FPGAの置き換えが発生したときに既に適用されていないと有効活用することは難しいですが、今後FPGAの置き換えが必要なデザインにおいて採用いただくことで効果的に活用いただけるものになっています。
それでは始めましょう。
目次
デバイス変更に伴う課題
事前アンケート結果
「FPGA置き換えソリューションウェビナー」にて「FPGAの置き換え時の主な課題は何ですか?」という質問をウェビナー登録者131名に事前アンケートで行ったところ、以下のような結果となりました。
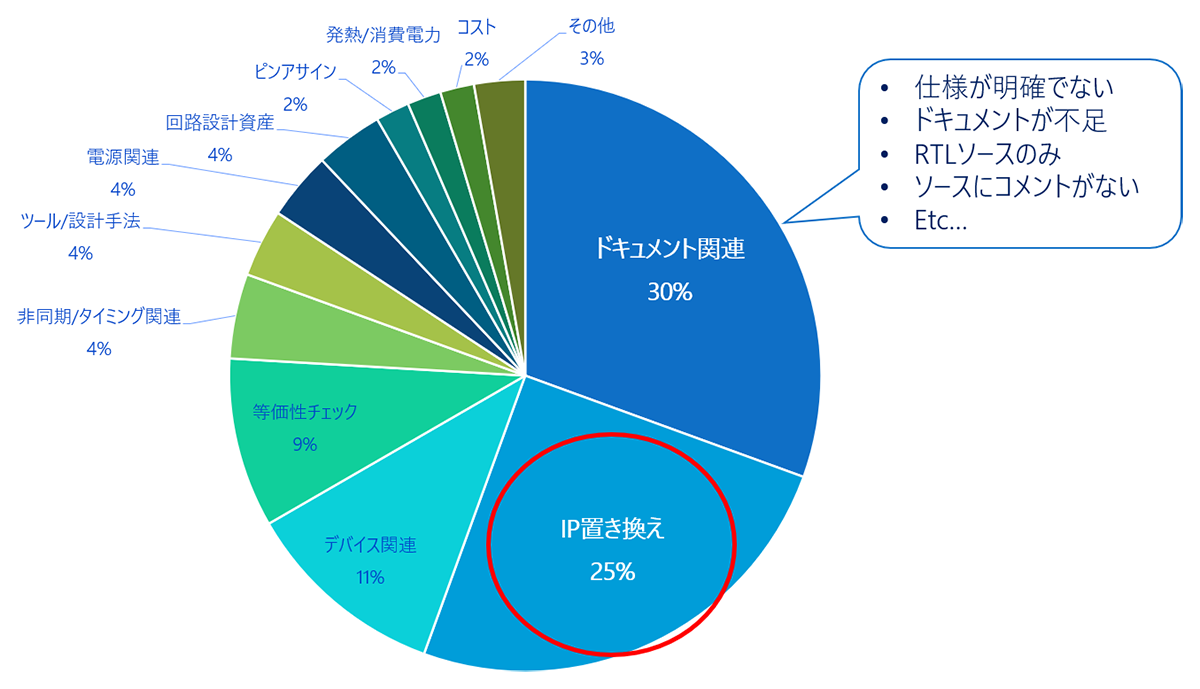
質問回答の上位には、ドキュメント関連(30%)、IPの置き換え(25%)、デバイス関連(11%)、等価性チェック(9%)などが挙がりました。
その他の課題としては、非同期やタイミング関連、ツールの使い方や設計手法、電源関連、回路設計資産(ゲートレベル)、またピンアサインや発熱/消費電力、コストなどの課題が挙がりました。
驚くべきことに、回答者の半数以上がドキュメントやIPの置き換えに関する課題を抱えていました。そこで、ここでは2番目に多かった「IPの置き換え」に焦点を当てていきます。
IPの置き換えにおけるお客様の声
IPの置き換えが困難な理由として、以下のような声が挙がっていました。
- IPの互換性を取るのが困難
- 汎用的な置き換えガイドが用意できない
- メーカーやデバイスの違いでそのまま使用できない
- IPに対してタイミングなどの仕様調査が必要
- メーカーやツールのバージョンが異なるとIPの作成、使用方法も変わる
- 等価なIPがない
- 代替IPがない(特に3rdパーティーのIP)
IP関連の課題考察
この「IPを置き換える」という作業の中で、手順と具体的な課題を見ていきます。
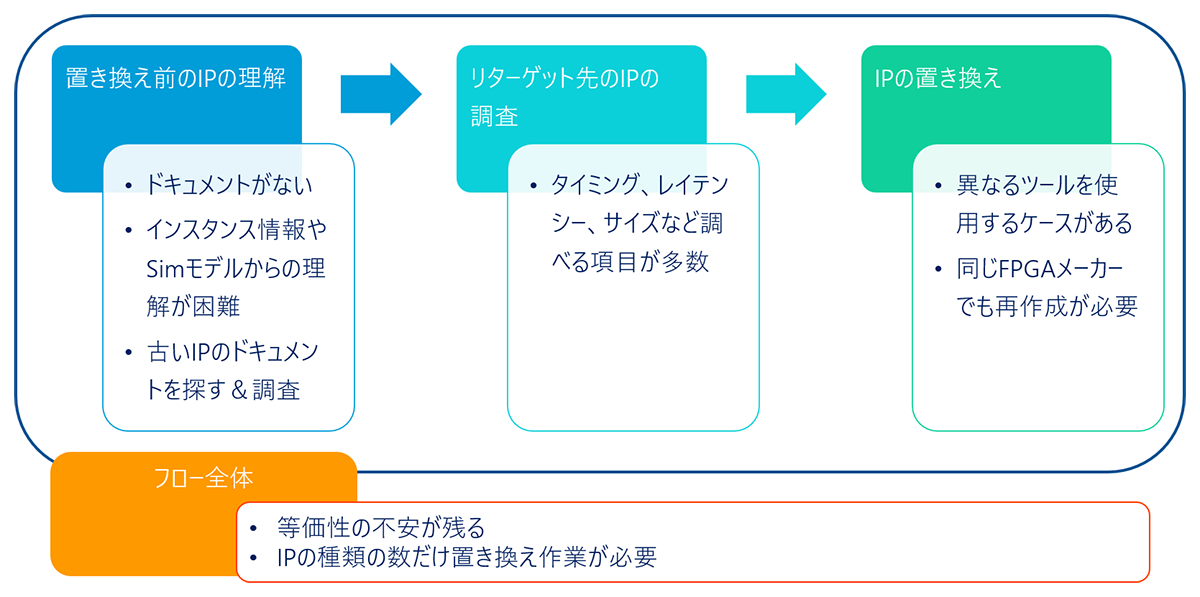
- IPの仕様の確認
置き換え前のIPに関しては、まず仕様がどうなっているかを理解しなければなりません。
ところが、FPGAベンダーツールで生成したIPはインスタンシエーションのみで、ブラックボックスとして扱われているものが多々あります。インスタンス情報からでは何も理解することはできないうえに、同時に生成されたシミュレーションモデルから論理を理解しようというのはかなり難しいです。また古いIPであることからドキュメントがないことや探すのが大変といったことも挙げられるでしょう。 - 代替IPの調査
置き換え前のIPがどういうものか理解できた場合、リターゲットする先のIPで該当するものがあるか調査する必要があります。このときのタイミングやレイテンシー、サイズなどを確認し、各種設定や仕様の細かい部分が合うかどうかも調査する必要があります。
また、実際に置き換えるとなると、使用方法が異なるツールを使うケースや同じFPGAメーカーであってもデバイスが変更されれば当然再作成が必要になり、その分作業工数も増えます。
- 代替IPの等価性の検証
フロー全体で見ますと、等価のものに置き換えたつもりでもやはり等価性に不安が残り、正常に動かなかった場合は置き換えたIPを疑わざるを得ないといったことが出てきます。
また、非常に多くの種類のIPを使うことでその種類だけ置き換え作業が必要になってくるといったところが挙げられます。
コーディングによる解決策
再利用向きなRTLコーディング手法
前章では、IP関連の課題を考察しました。
これらの課題に対して、「再利用向きなRTLコーディング手法」の具体的な提案を3つお伝えします。
- 一般的なコーディングルールの適用
日本ではSTARCルールやHDLスタイルガイドとよばれるものがあります。海外ではRMM(リユースメソドロジーマニュアル)というものがあり、その中で定義されているネーミングルールを適用することが解決に繋がります。
合成ツールやシミュレーションが誤解しそうな曖昧な記述は控えるなどルールに従って記述することをおすすめします。 - リントチェックの活用
リントチェッカーは、記述したコードの中の潜在的なバグを特定することが可能です。
例えば、ステートマシンのデッドロジックや未使用の回路などを事前にチェックできます。
また、CDCと呼ばれる非同期クロックの乗せ換えの部分回路が含まれているかなどのチェックも、この段階で行えるツールがあります。そのため、リントチェッカーを有効活用すべきといえます。 - 推定可能なコーディング
推論可能なコーディングとは、汎用的なRTLコードから論理合成ツールがIPとして認識できる記述方法です。
IPとして認識されたブロックは配置時に専用の配線領域に置かれますので、タイミング的にもエリア的にも非常にパフォーマンスの良いものとして扱われることになります。このコーディング手法はVHDL、Verilog、SystemVerilogいずれでも記述することができます。
もう少し詳しくお伝えします。
推定可能なコーディング
この手法には以下のような利点があります。
- ①
- ベンダー・デバイス依存がない
- ②
- リターゲットしても論理が変わらない
汎用的なコードを書いていますので、それによって合成ツールにバグがない限り、論理は変わりません。つまりこの①・②の理由から置き換えが不要になるということがいえます。
また、その他の利点としては、ブラックボックスをインスタンシエーションするようなものではないので、中の論理が理解可能という点や設定されているパラメーターの意味もコード中から理解できる点が挙げられます。
推定可能なコーディングに関しては、AMD社/Intel社の両方にマニュアルが用意されています。
AMD社であれば【Vivado Design Suite ユーザー ガイド: 合成 (UG901)】内の「HDL コーディング手法」という章に具体的な技術例も含めて記載されています。
Intel社であれば【インテル® Quartus® Prime プロ・エディションのユーザーガイド】内の「1. 推奨 HDL コーディング・スタイル」という章の中に記述例とともにどのようなコードを書けば良いか記載されています。
推定可能なコーディングはすべてのIPで記述できるとは限りません。
対象となるのは、RAM/ROM、DSPブロック、シフトレジスタ、FIRフィルターなどです。
DDRやPCI Express、PLLなどの複雑な論理やアナログ要素を含むIPは対象外となります。
推定可能なコードとIP使用の比較
いずれもVerilogですがVHDLでもポイントは同じです。
レジスタ部分をreg宣言し、それをループで回しています。この時にレジスタの要素部分をインクリメントしてシフトすれば、シフトレジスタであることを論理合成ツールが認識します。
module shift_registers_1 (clk, clken, SI, SO);
parameter WIDTH = 32;
input clk, clken, SI;
output SO;
reg [WIDTH-1:0] shreg;
integer i;
always @(posedge clk)
begin
if (clken)
begin
for (i = 0; i < WIDTH-1; i = i+1)
shreg[i+1] <= shreg[i];
shreg[0] <= SI;
end
end
assign SO = shreg[WIDTH-1];
endmodule
こちらもreg宣言で二次元配列を定義し、この二次元配列に対して読み書きを行います。ここで興味深いのは、we信号が有効時にライトが先に行われ、リードがその後になる点です。つまり、この記述を見ればどちらの操作の優先順位が高いかが分かります。リードファーストなのかライトファーストなのかを、記述から即座に理解できます。
module rams_sp_rf (clk, en, we, addr, di, dout);
input clk, we, en;
input [9:0] addr;
input [15:0] di;
output [15:0] dout;
reg [15:0] RAM [1023:0];二次元配列の定義
reg [15:0] dout;
always @(posedge clk)
begin
if (en)
begin
if (we)
RAM[addr]<=di;
dout <= RAM[addr];リード/ライトの優先順位を決定
end
end
endmodule
このシングルポートRAMに関してもう少し具体的に見ていきたいと思います。
ブロックRAMの比較例
Vivado IP Catalogを使用した場合
FPGAの新規設計において、専用IPの利用は非常に効果的です。専用ウィザードを使用することで、シングルポートRAMやデュアルポートRAMなどのメモリータイプを選択し、データ幅、ワード数、アドレス幅を設定できます。さらに、ライトファーストかリードファーストかといったオペレーティングモードを選択するだけで、プロジェクト作成時に決定したデバイスに対応した専用IPを生成することができます。
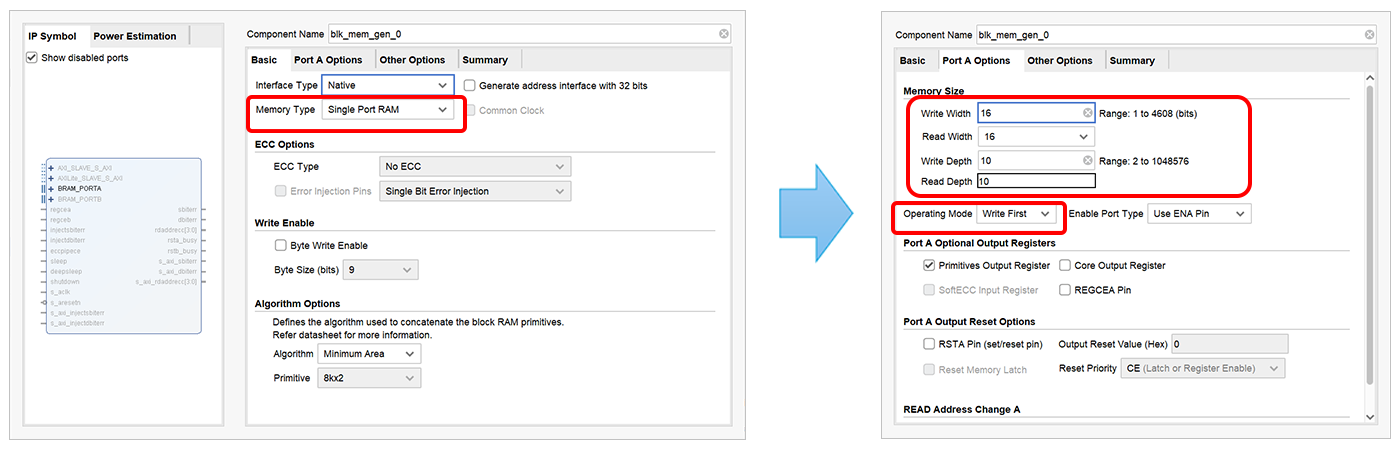
しかし、このアプローチにはいくつかの課題があります。まず、デバイスが固定されるため、FPGA置き換えが発生した場合に再作成が必要になります。また、生成されたインスタンスの情報やシミュレーションモデルから仕様を理解することが困難です。ビット幅やメモリーの種類は分かりますが、リードファーストなのかライトファーストなのかといった詳細は、シミュレーションモデルを詳細に調査しなければ把握できません。
|
インスタンシエーション用の記述 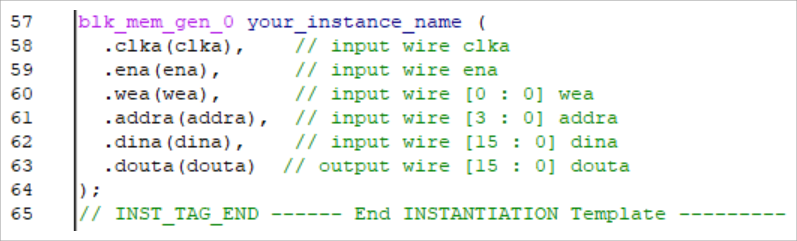 |
シミュレーション用モデル 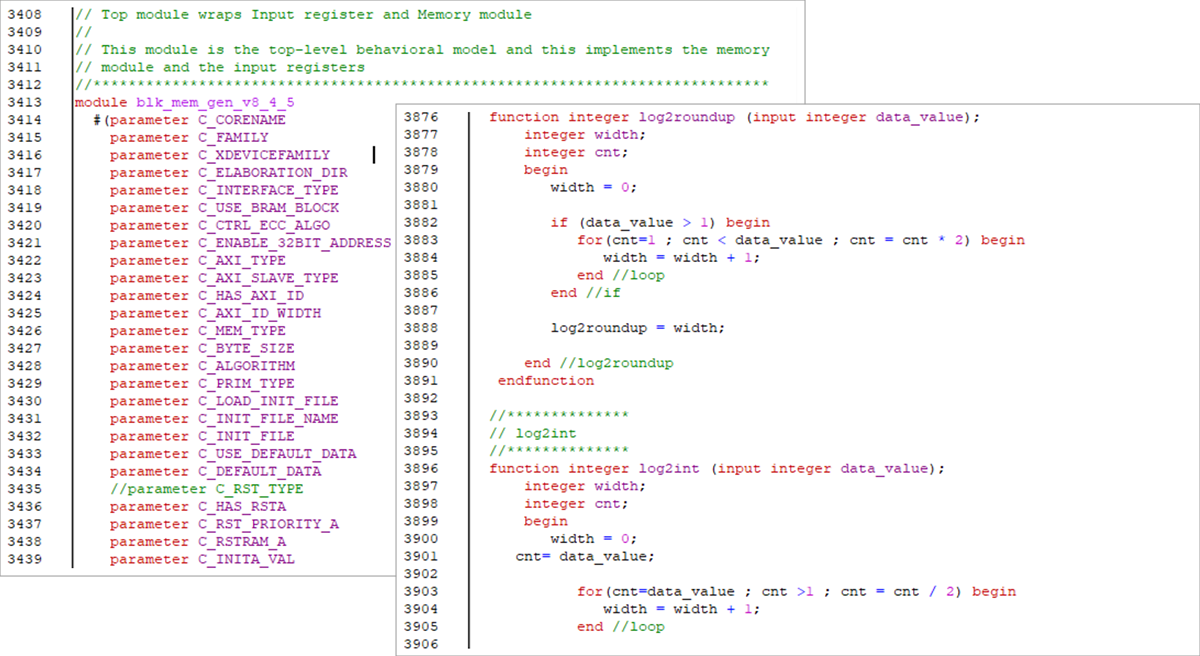 |
推定可能なコーディングを使用した場合の合成結果
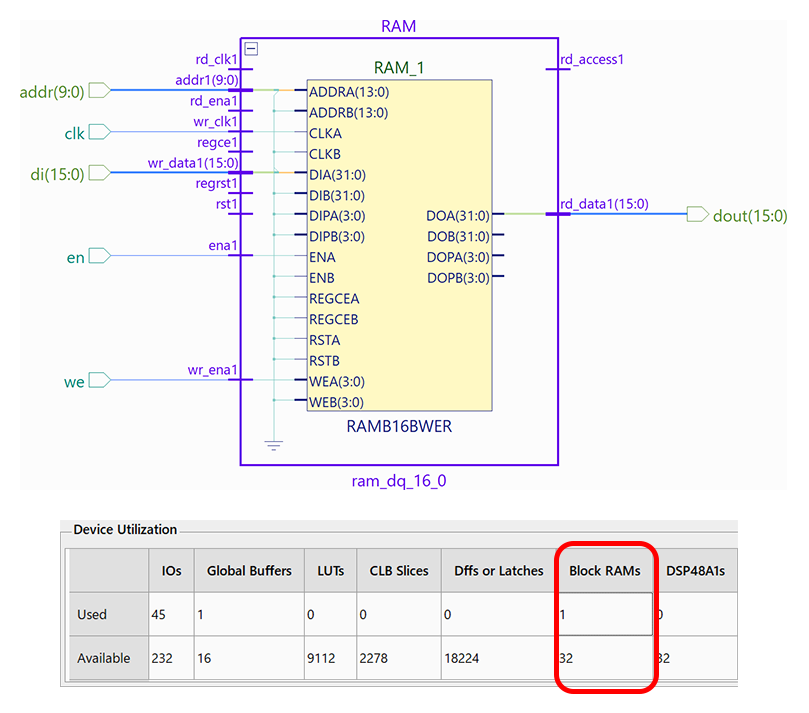
一方、推論可能な記述を使用して合成を行った場合、同じコードで異なるデバイスへのマッピングが可能です。しかしデバイスの種類によって論理は変わらず異なる結果が得られます。例えば、AMD社のSpartan-6でシングルポートRAMを推論させると、ブロックRAMとして認識されます。これは、メモリーとして正しく認識されていることを示しています。エリアレポートでも、ブロックRAMカテゴリで使用状況が報告されます。
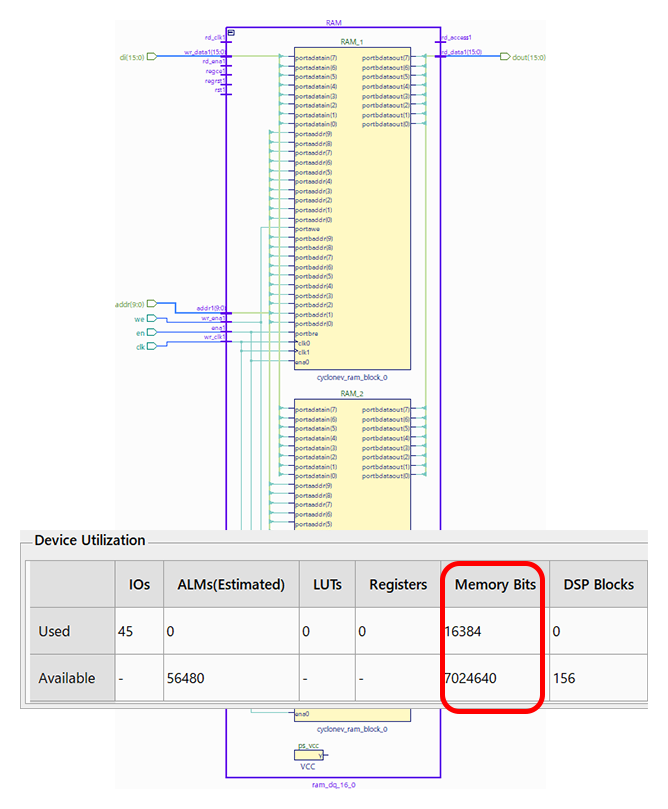
興味深いことに、同じコードをIntel Cyclone Vで構成し直しても、メモリーとして正しく推定されます。ただし、メモリーサイズが1つのブロックRAMに収まりきらない場合、論理合成ツールが自動的に2つに分割して構成します。このように、同じ記述でも論理合成ツールがデバイスに応じて適切にIPを構成してくれます。
AMD Spartan6
Intel Cyclone V
まとめ
FPGA置き換えにおいて、IPの置き換えは大きな課題です。メーカーやデバイスの違いにより、そのまま使用することができず、仕様の確認に多大な時間がかかり、IPの数だけ置き換えが必要になります。
この問題の解決策として、推論可能なコーディングが有効です。特に、DSP、メモリー、シフトレジスタなど複雑な論理を持たないものに適しています。VivadoやQuartusのマニュアルには、このコーディング手法に関する記載例が掲載されているので参考にすることができます。
皆様のFPGA開発がよりスムーズになることを願っています!




