業界最安値のGPUaaS「GPUSOROBAN」を実際に試してみた(6)~Dockerコンテナを使用し機械学習プロト環境を作る~【クラウドでリアルタイム顔検出編】

皆さん、こんにちは。
本ブログは最新の GPU が使える上に、とても安いと噂の「GPUSOROBAN」がどんな感じのものなのか、Dockerコンテナを使用し機械学習プロト環境を作成し、最終的にはオンプレ環境とクラウド環境でリアルタイムに顔検出を行う工程を実際に試してみたブログです。
今回は、これまでのシリーズ最終回で、クラウドを使用してオンプレと同じものを動かしたいと思います。ご参考になれば幸いです。
それでは、始めましょう。
目次
クラウドでリアルタイム顔検出
やっとクラウドを使ってオンプレと同じものを動かしはじめます。
とは言えトラブルがなければ、ここまでOSのインストールから2、3時間もあれば到達できると思います。
オンプレで作ったdockerイメージをクラウドに上げる
インスタンスにイメージを受け取るディレクトリを作成します。
sudo mkdir -p $WORK_DIR/docker_images
sudo chown $BARE_USER.$BARE_GROUP $WORK_DIR/docker_images
# sudo chmod 777 $WORK_DIR/docker_imagesホストPCからインスタンスにイメージを転送します。
CUDAを使用するコンテナの場合(ファイルサイズが大きいので10分程かかりました)
cd $WORK_DIR/docker_images
time scp -P $SSH_PORT -i $KEY_PRIVATE kirin_cuda11_4_ubuntu18.04__$REVISION.tar.gz \
$BARE_USER@localhost:$WORK_DIR/docker_imagesCUDAを使用しないコンテナの場合(CUDA版よりサイズが小さいので4分程度で転送できました)
cd $WORK_DIR/docker_images
time scp -P $SSH_PORT -i $KEY_PRIVATE kirin_cpu_ubuntu18.04__$REVISION.tar.gz \
$BARE_USER@localhost:$WORK_DIR/docker_imagesインスタンスのDockerにイメージを取り込みます。
CUDAを使用するコンテナの場合
buser@gpu55:/work$ cd $WORK_DIR/docker_images
buser@gpu55:/work/docker_images$ time docker load -i kirin_cuda11_4_ubuntu18.04__$REVISION.tar.gz
3e549931e024: Loading layer [==================================================>] 65.53MB/65.53MB
a9c5be614fd8: Loading layer [==================================================>] 17.1MB/17.1MB
1d3e7c6b4794: Loading layer [==================================================>] 34.72MB/34.72MB
5d8e4fac6f11: Loading layer [==================================================>] 3.072kB/3.072kB
3c24041dd117: Loading layer [==================================================>] 17.92kB/17.92kB
2a74b5323c13: Loading layer [==================================================>] 2.02GB/2.02GB
ff5d69fb134b: Loading layer [==================================================>] 264.7kB/264.7kB
caf03ff00bd7: Loading layer [==================================================>] 2.92GB/2.92GB
5965f8ca39c3: Loading layer [==================================================>] 377.3kB/377.3kB
283631d4df4d: Loading layer [==================================================>] 3.927GB/3.927GB
b9c17203f4b2: Loading layer [==================================================>] 6.974GB/6.974GB
Loaded image: kirin/cuda11_4_ubuntu18.04__01:latest
real 3m10.611s
user 0m1.261s
sys 0m4.956sイメージを確認します。
buser@gpu55:/work/docker_images$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
kirin/cuda11_4_ubuntu18.04__01 latest fc1438ab4dd6 11 hours ago 15.9GBCUDAを使用しないコンテナの場合
cd $WORK_DIR/docker_images
time docker load -i kirin_cpu_ubuntu18.04__$REVISION.tar.gz細かい説明は省きますが、オンプレでセーブしたファイルは、単一のイメージになっています。インスタンスでこのイメージからコンテナを生成します。生成されたコンテナの内容はセーブしたものと同じになります。
ではコンテナを生成します。
オプションはオンプレと同じです。違いは最後の行のイメージがload(save)したイメージ名に変わっているだけです。使用中に何にログインしているターミナルなのか分かりやすくするためにhostnameを「docker_*_CLOUD」に変更しました。
CUDAを使用する場合
docker run -p 40090:9090 -p 8080:80 -p 40022:22 \
-it -d \
--gpus all \
--hostname " docker_CUDA_CLOUD" \
--name kirin_cuda_test01 \
kirin/cuda11_4_ubuntu18.04__01CUDAを使用しない場合
docker run -p 40090:9090 -p 8080:80 -p 40022:22 \
-it -d \
--hostname "docker_CPU_CLOUD" \
--name kirin_cpu_test01 \
kirin/cpu_ubuntu18.04__01コンテナにログインしてみます。オンプレのときと同じコマンドでログインできます。
# CUDAを使用するコンテナの場合
buser@gpu55:~$ docker exec -it kirin_cuda_test01 /bin/bash
root@ docker_CUDA_CLOUD:/#
# CUDAを使用しないコンテナの場合
buser@gpu55:~$ docker exec -it kirin_cpu_test01 /bin/bash
root@ docker_CPU_CLOUD:/#GPUクラウドでリアルタイム顔検出
まずは、クラウドとローカルネットワーク間のアクセスを可能にするためにローカルネットワークのポートフォワード設定を行います。
具体的にはルータやファイアウォール機器に以下のNATの設定を行うことになります。IPアドレスは環境に合わせて読み替えてください。
表1-1 ルータのNAT設定
| No. | WAN側ポート | LAN側ポート | プロトコル | 転送先IPアドレス | 目的 | |
|---|---|---|---|---|---|---|
| No.1 | 1 |
40080 |
40080 |
http |
192.168.0.143 |
インスタンスから |
| No.2 | 2 |
60022 |
22 |
ssh |
192.168.0.90 |
インスタンスから |
| No.3 | 3 |
40090 |
40090 |
http |
192.168.0.90 |
ホストPCから |
No.1は一般的によくある設定ですが、No.2、3はクラウド側に踏み台があるがための設定です。
まずは入力にカメラでなく動画ファイルを使った顔検出をやってみます。
コンテナで以下のコマンドを実行します。
export OPENCV_VER=4.5.5
export PYTHONPATH=/usr/local/lib/opencv$OPENCV_VER/lib/python3.6/site-packages/cv2/python-3.6:$PYTHONPATH
cd /work/soroban3
# CUDAを使用するコンテナの場合
python3 detectMultiScale_cuda.py
# CUDAを使用しないコンテナの場合
python3 detectMultiScale_cpu.pyPythonのパスの設定を忘れたり、間違えたりすると以下のエラーが発生します。
root@ docker_CUDA_CLOUD:/work/soroban3# python3 detectMultiScale_cuda.py
play input.mp4
Traceback (most recent call last):
File "detectMultiScale_cuda.py", line 21, in <module>
classifier = cv2.cuda.CascadeClassifier_create(cascPath)
AttributeError: module 'cv2.cuda' has no attribute 'CascadeClassifier_create'うまく動くと以下のようになって待ち状態になります。
root@ docker_CUDA_CLOUD:/work/soroban3# python3 detectMultiScale_cuda.py
play input.mp4
play input.mp4
Bottle v0.12.23 server starting up (using WSGIRefServer())...
Listening on http://0.0.0.0:9090/
Hit Ctrl-C to quit.次にインスタンスで以下を実行して、インスタンスのポート40090をホストPCのポート40090に接続して、ホストPCからコンテナにアクセスできるようにトンネルで繋ぎます。
buser@gpu55:~$ ssh -R 40090:$BARE_ADR:40090 -p 60022 kirin@$HOME_GLOBAL_IP
kirin@220.100.45.33's password:
Welcome to Ubuntu 18.04.6 LTS (GNU/Linux 5.4.0-124-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
209 updates can be applied immediately.
187 of these updates are standard security updates.
To see these additional updates run: apt list --upgradable
New release '20.04.4 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Your Hardware Enablement Stack (HWE) is supported until April 2023.
Last login: Tue Aug 16 14:40:02 2022 from 202.122.50.210
kirin@xeon-e3:~$上記のシェルはこのままにしておきます。
少しややこしいのでポートの経路を説明します。
図1の①でコンテナのポート9090はインスタンスのポート40090に繋がっています。これはコンテナのポートフォワードに設定されています。
図1の②でインスタンスのポート40090をホストPCのポート40090に接続します。これはsshコマンドの以下の部分に相当します。
40090:$BARE_ADR:40090
以上の2つによって間接的にホストPCのポート40090とコンテナのポート9090が接続されます。
②のトンネルに実態は、自宅のWAN側の60022から入り、NATを経由してホストPCのポート22に繋がるssh内を通っています。これはsshコマンドの以下の部分に相当します。
-p 60022 kirin@$HOME_GLOBAL_IP
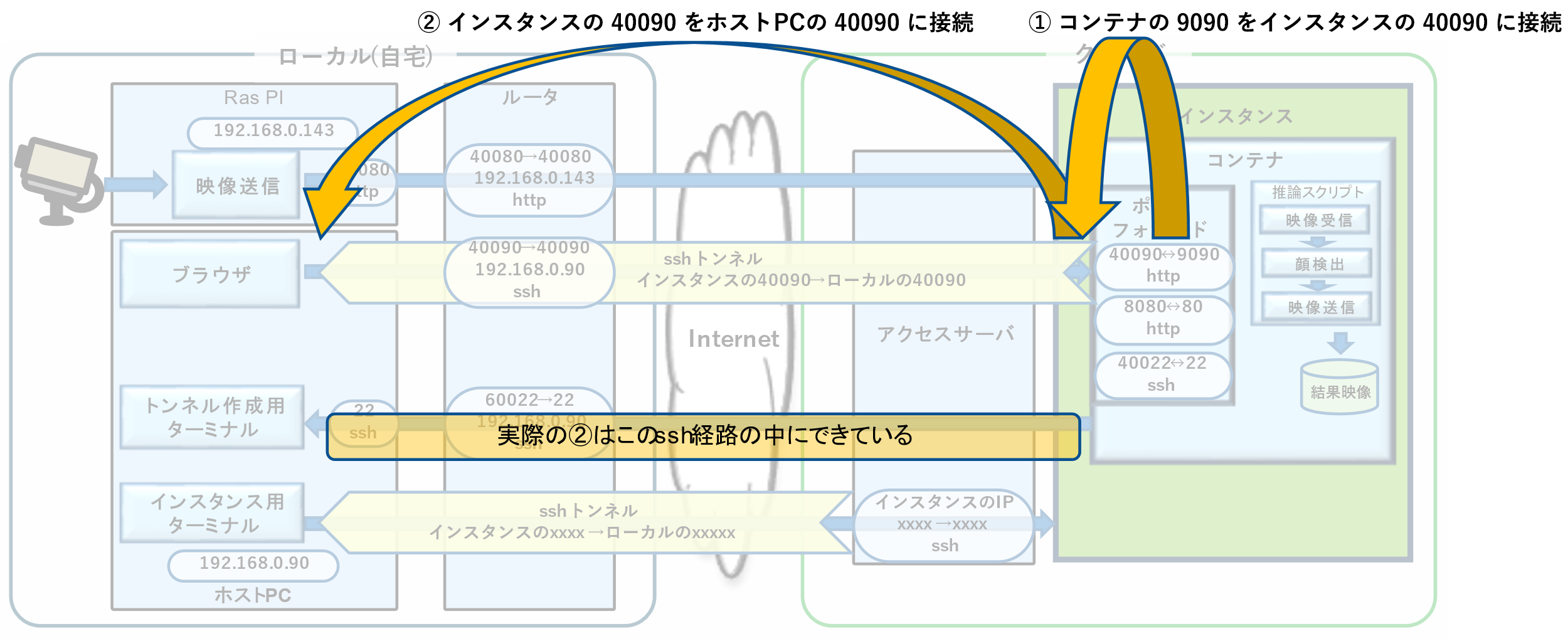
図1 ポートフォワードとsshトンネルによるポート9090の経路
ログインできても以下のワーニングが発生しているとホストPCからアクセスできません。
buser@gpu55:~$ ssh -R 40090:$BARE_ADR:40090 -p 60022 kirin@$HOME_GLOBAL_IP
kirin@220.100.45.33's password:
Warning: remote port forwarding failed for listen port 40090
Welcome to Ubuntu 18.04.6 LTS (GNU/Linux 5.4.0-124-generic x86_64)
:省略上記はホストPCのポート40090が使用中の場合に発生します。ホストPCでコンテナが起動しているとコンテナがポート40090を使用しているのでホストPCのコンテナを停止して再度実行します。
# CUDAを使用するコンテナを停止する場合
docker stop kirin_cuda_test01
# CUDAを使用しないコンテナを停止場合
docker stop kirin_cpu_test01ホストPCのポート40090にインスタンス上のコンテナのポート9090が接続されているので、ホストPCのブラウザ(firefox等)で以下URLにアクセスすると顔検出を開始します。
localhost:40090CUDAを使って動画ファイルから顔検出したときのブラウザの表示です。
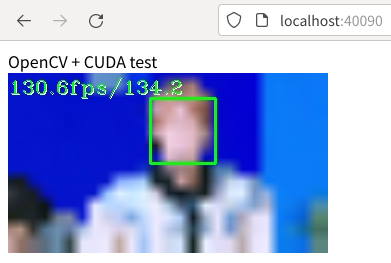
CUDAを使わすに動画ファイルから顔検出したときのブラウザの表示です。
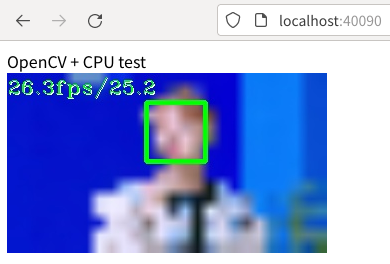
まれにブラウザからアクセスしたときにsshのトンネルを掘ったターミナルに以下のメッセージが出て検出が始まらないことがありました。原因は追究していませんが、ブラウザの再読み込みを実行すると検出を開始しました。
buser@gpu55:/work/docker_images$ ssh -R 40090:$BARE_ADR:40090 -p 60022 kirin@$HOME_GLOBAL_IP
kirin@220.100.45.33's password:
Welcome to Ubuntu 18.04.6 LTS (GNU/Linux 5.4.0-124-generic x86_64)
:省略
Your Hardware Enablement Stack (HWE) is supported until April 2023.
Last login: Wed Aug 17 16:17:22 2022 from 202.122.50.210
kirin@xeon-e3:~$
connect_to 172.20.11.115 port 40090: failed.
connect_to 172.20.11.115 port 40090: failed.
connect_to 172.20.11.115 port 40090: failed.次にRas PIのカメラ映像から顔検出してみます。
一旦、実行していたPythonをCTRL-cで停止し、sshもCTRL-dで抜けます。
Ras PIで配信を開始します。
mjpg_streamer -i "input_uvc.so -n -fps 30 -r 640x480 -u -q 80" \
-o "output_http.so -w www -p 40080"あらためてコンテナで以下を実行します。Ras PIのIPアドレスはローカルネットワークのグローバルIPを指定します。ルータまたはファイアウォールのNAT設定によってRas PIのポート40080に接続されます。
Pythonのスクリプトは引数にhttpを追加します。
export OPENCV_VER=4.5.5
export PYTHONPATH=/usr/local/lib/opencv$OPENCV_VER/lib/python3.6/site-packages/cv2/python-3.6:$PYTHONPATH
cd /work/soroban3
export RASPI_IP= [自宅のグローバルIP]
# CUDAを使用するコンテナの場合
python3 detectMultiScale_cuda.py http
# CUDAを使用しないコンテナの場合
python3 detectMultiScale_cpu.py httpうまく動くと以下のようになって待ち状態になります。
root@ docker_CUDA_CLOUD:/work/soroban3# python3 detectMultiScale_cuda.py http
play http://[自宅のグローバルIP]/?action=stream #
play http://[自宅のグローバルIP]:40080/?action=stream #
Bottle v0.12.23 server starting up (using WSGIRefServer())...
Listening on http://0.0.0.0:9090/
Hit Ctrl-C to quit.次にファイルからの検出と同様にインスタンスで以下を実行して、ホストPCからインスタンスにアクセスできるようにトンネルで繋ぎます。
ssh -R 40090:$BARE_ADR:40090 -p 60022 kirin@$HOME_GLOBAL_IP上記のシェルはこのままにしておきます。
ファイルからの検出同様に、ホストPCのfirefoxで以下URLにアクセスすると顔検出を開始します。
localhost:40090CUDAを使ってカメラ映像から顔検出したときのブラウザの表示です。
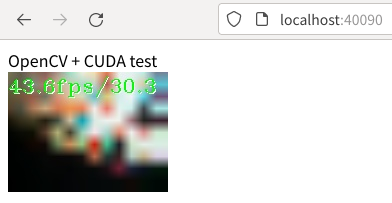
CUDAを使わずにカメラ映像から顔検出したときのブラウザの表示です。
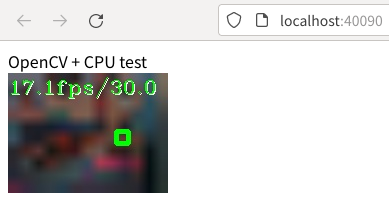
表示されない場合は、インスタンスで以下のコマンドを実行してみます。
http://[ローカルネットワークのグローバルIP]:40080/?action=stream以下のようにダウンロードが継続すれば映像がRas PIからインスタンスまで到達しています。
buser@gpu55:~$ wget http://220.100.45.33:40080/?action=stream -O tmp.mp4
--2022-08-16 17:20:35-- http://220.100.45.33:40080/?action=stream
Connecting to 220.100.45.33:40080... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [multipart/x-mixed-replace]
Saving to: ‘tmp.mp4’
tmp.mp4 [ <=> ] 4.84M 1.42MB/s映像がインスタンスに到達していてうまく動かない場合は、sshのトンネルにワーニングが出ていないか、ルータもしくはファイアウォールの設定が間違ってないかを確認します。
以上で当初想定していた環境がすべてでき、課題と考えていた以下の2点もクリアできました。
- ・
- インスタンスでの映像ストリームの受信
- ・
- インスタンスからの映像ストリームの送信
まとめ
環境作りに関しては、インスタンスがアクセスサーバで隔離されているために外部との接続がかなり煩雑になってしまいました。それでも比較的構成要素を入れ替えやすい形で映像の入出力までできるようになったのでいろいろな実験に使えるのではないかと思います。
当初気になっていた以下のベアメタルインスタンスに関する確認事項にも問題がないことが分かりました。
- ・
- GPUSOROBANのベアメタルインスタンスをスムーズに導入できるか
メールのやり取りだけで手間なく進んだ。
- ・
- クラウドのCUDAのバージョンをオンプレと合わせることができるか
アンインストールに関わるバージョン不整合が気になっていたが問題は起こらなかった。
GPUSOROBANのベアメタルは自力ではOSの初期化ができないので、CUDAの入れ替えで失敗したらどうなるか不安でしたが、nVidiaの公表している手順でトラブルなく入れ替えることができました。
- ・
- CUDAを使うDockerコンテナがクラウド(異なるGPU)でそのまま動くか
コンテナには一切手を加えることなく動いた。
いろいろなサービスのアイデアを試す上で、オンプレでGPUも使わずにちょっと試せる環境からGPU性能が求められるケースでGPUSOROBANのA100を使える環境までできました。
今回作ったものにFPGAを使ったAIを組み込むことも難しくはなさそうです。
Dockerを採用することでPC毎、インスタンス毎に毎回環境を作る必要がなくなり、時間経過による再現性の低下も防げる状態にできました。再現性がないことや、関係者に展開できない評価、開発環境程始末の悪いものはありません。
いろいろと苦労はありましたがこれを使っていろんな実験をしてみたいと思います。
おわりに
いかがでしたでしょうか。6回にわたり、業界最安値のGPUaaS「GPUSOROBAN」を実際に試しDockerコンテナを使用して機械学習プロト環境を作成しました。
本ブログに関するご質問や不明点がありましたらぜひ以下問合せフォームよりお問い合わせください。
最後までご覧いただきありがとうございました!











