業界最安値のGPUaaS「GPUSOROBAN」を実際に試してみた(1)~Dockerコンテナを使用し機械学習プロト環境を作る~【イントロ】

皆さん、こんにちは。
本ブログは最新のGPUが使える上に、とても安いと噂の「GPUSOROBAN」がどんな感じのものなのか、Dockerコンテナを使用し機械学習プロト環境を作成し、最終的にはオンプレ環境とクラウド環境でリアルタイムに顔検出を行う工程を実際に試してみたブログです。
少々長い記事になるので6回に分けて紹介します。
| 第一回: | イントロ |
| プロトのシステム構成と背景の説明 | |
| 第二回: | 環境構築 その1 |
| 使用する機材やソフトウェアの定義とubuntu 18.04へのCUDAのインストール | |
| 第三回: | 環境構築 その2 |
| Dockerのインストールとコンテナの作成 | |
| 第四回: | オンプレで リアルタイム顔検出 |
| Raspberry PIのカメラ映像をネットワーク経由で取得し、OpenCVで顔検出 | |
| 第五回: | GPUSOROBANの ベアメタルの導入 |
| ベアメタルの試用の申し込みからCUDA環境の整備、Dockerのインストールまで | |
| 第六回: | クラウドで リアルタイム顔検出 |
| オンプレで使ったコンテナをそのまま使ってクラウドで顔検出 |
それでは始めましょう。
今回はイントロ回として、実際に作成するシステムの構成について紹介します。
目次
はじめに
「GPUSOROBAN」は、株式会社ハイレゾが運営するAI開発や高解像度映像のレンダリングや交通インフラ、医療などのシミュレーションなどに活用されるGPUリソースを、低コスト・定額料金で利用できる業界最安値のGPUクラウドサービスです。
Windowsでのインスタンスの作成から接続までの手順は「GPUSOROBAN」公式Webサイトの「SOROBANで仮想インスタンスを作成するには~WINDOWS10の場合~」にも掲載されています。
これまで製品やサービスを提供することを生業としているところに馴染みのない機械学習を取り込もうとすると、これまで扱ったことのない言語、プラットフォーム、考え方等が必要になってなかなか手を付けにくいと思います。
まずは動かしてみようと思って試してみるも、依存するソフトウェアが非常に多いためバージョンの不整合が起こりやすく、進化中のソフトウェアが多いことやバージョンによってAPIが違う、バグがある等の問題もあり、はじめての挑戦でテンプレ通りにやっても動かすまでの道のりはとても長いと感じます。
そこでサービスのプロトや実験ができるように図1のようなシステムを想定した環境を(ほぼ)0から作ってみます。
サービスを想定するのでリアルタイムであることを重視し、できるだけ機器やプラットフォーム、モデル、通信プロトコル等の構成要素を入れ替えやすいものにします。作った環境は維持しやすく、共同開発者等に簡単に展開できるようにDockerを使います。
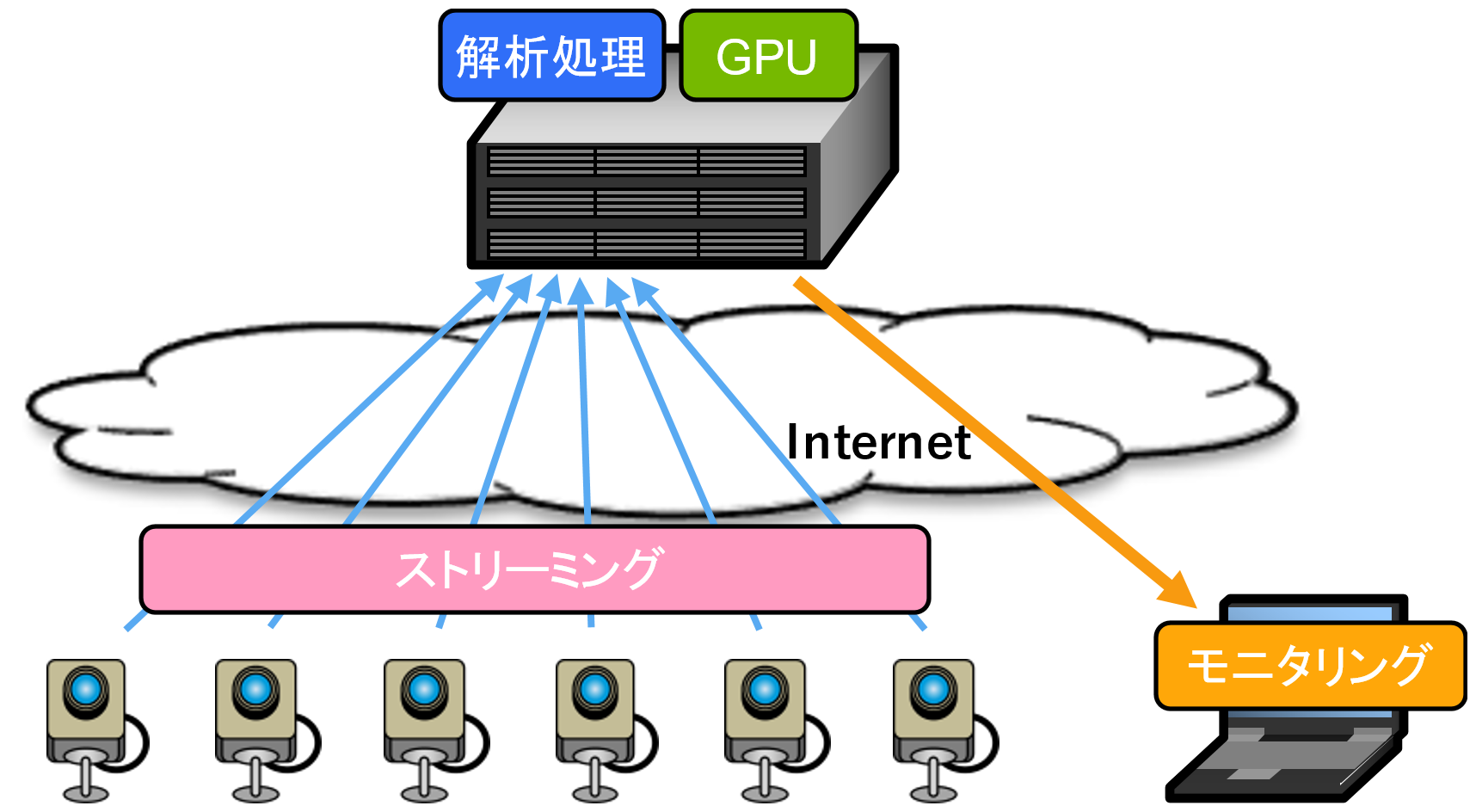
図1 サービスシステム構成図
GPUSOROBANをどんなサービスで効果的に使えるのか試してみる環境を作りたくて始めたのですが、私自身も久しぶりの機械学習、はじめてのCUDAで結構てこずりました。
GPUだけではサービスを実現できないケースもあるので、少々の変更で他のクラウドでも動かせるものにします。
カメラ映像の分析が必要となるケースは従来から多々ありますが、対象台数が数百台をはるかに超えて、桁が大きく変わってきているようです。このようなケースではクラウドでスケーラブルにGPUを調達するメリットは大きくなりそうです。
作った環境をクラウドにも持って行くことを想定していますが、はじめてのCUDAとGPUSOROBANなので以下を確認します。
・GPUSOROBANのベアメタルインスタンスをスムーズに導入できるか
・クラウドのCUDAのバージョンをオンプレと合わせることができるか
・CUDAを使うDockerコンテナがクラウド(異なるGPU)でそのまま動くか
Python、OpenCVに不慣れなことによる私の課題です。
・映像ストリームの受信、デコード方法
・映像ストリームのエンコード、送信方法
・映像ストリームのファイル保存
・推論のCPUとGPU処理の切り替え方法
クラウドに使用するGPUSOROBANのインスタンスがアクセスサーバという踏み台で隔離されているので以下の課題も解決します。
・インスタンスでの映像ストリームの受信
・インスタンスからの映像ストリームの送信
一部、ネットワーク環境等に合わせて変更が必要ですが、本シリーズでは基本的には文中のオレンジの太字をコピペすることで同じ環境を作れるように書いていきます。
機械学習自体に言及すると話が長くなってしまうので、OpenCVに用意されているHaar-like特徴分類器を使った顔検出を行い、検出方式や検出精度については言及しません。
さらに学習済みモデルを使った推論を行い、学習については触れません。
今回使用したCPUとGPUです。No.1はGPUSOROBANを使用しました。
No.2、3はオンプレです。
表1-1 機械学習に使用したCPU/GPU
| No. | CPU | GPU | |
|---|---|---|---|
| No.1 | 1 |
AMD EPYC 7232P |
nVidia A100 40GB x1枚 |
| No.2 | 2 |
intel I7-8700 |
nVidia GeForce GTX |
| No.3 | 3 |
intel XEON E3-1280 v3 |
nVidia GeForce GTX |
その他の機材はraspberry PI 4とカメラを使用しました。
実際に作るシステムの構成
システムによって1台のカメラからの映像は1秒に1枚のケースもあれば1時間に1枚のケースもあるでしょう。受け取る側の推論性能は、カメラの台数に関係なく、時間当たりに処理する画像の枚数と見ることができます。多数のカメラを扱うには配慮すべきことが増えてしまうので、今回は図2のようにカメラの台数を1台にして、実験においては仮想的に映像のフレームレートを上げることで複数台のカメラから受け取った状況を作り出すことにします。数台であればカメラを増やすことはそれほど難しくはないと思います。
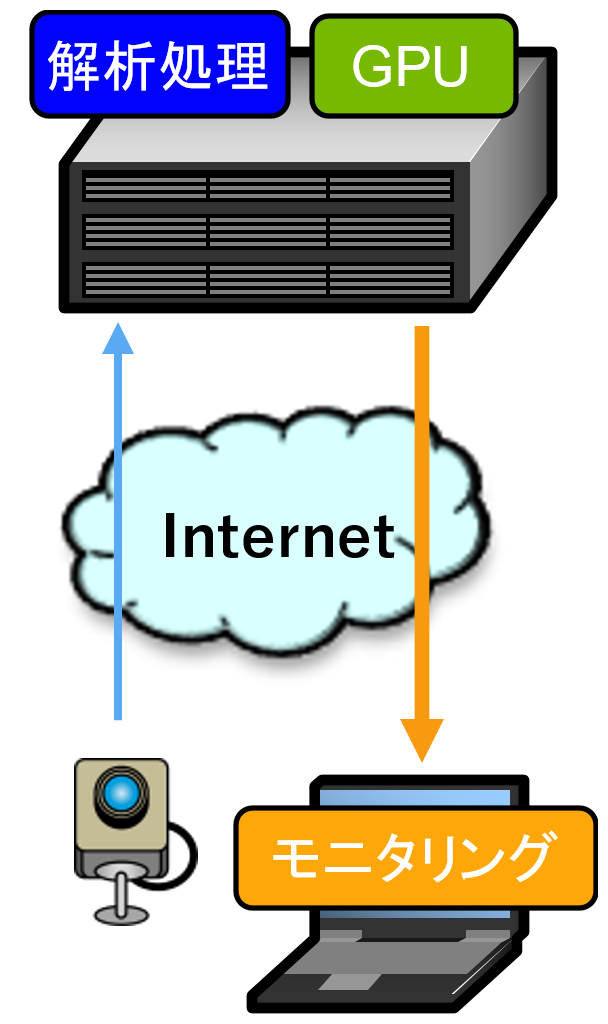
図2 実際に作る機械学習システム構成図
最初に図3のようなオンプレの1台のPCで動く環境を作り、そのシステムをそのままクラウドに持って行きます。
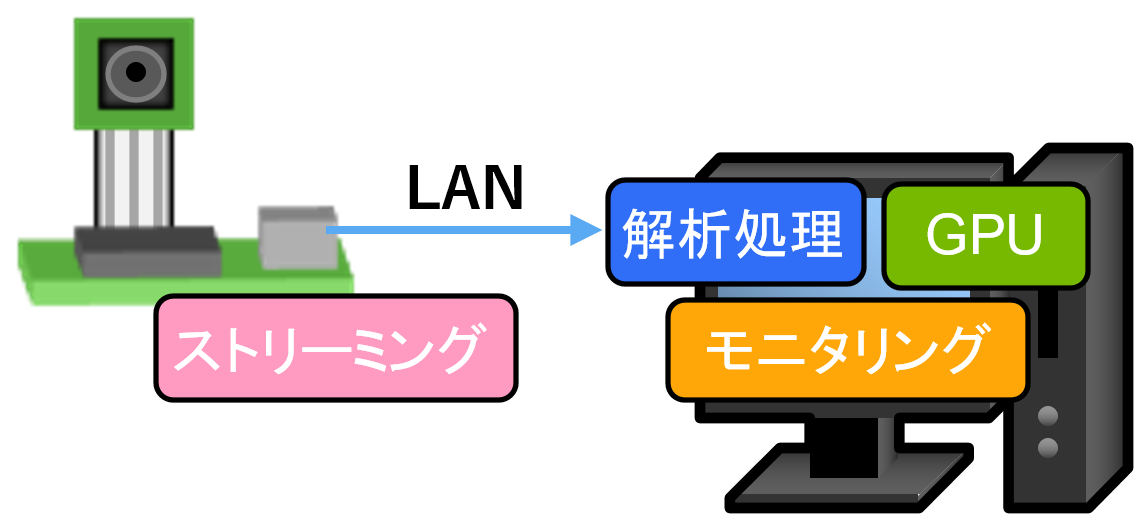
図3 オンプレの機械学習システム構成図
IPカメラの手持ちがなかったので、替わりにRaspberry PIに接続したカメラからmotion JPEGでストリーミングします。カメラはRaspberry PI用のMIPI I/Fのカメラ、USBカメラのどちらでも使えます。
Raspberry PIやカメラがない場合もMP4等の動画ファイルを入力にすることができるので他の部分を動かすことができます。
図4は全体をブレークダウンした図です。
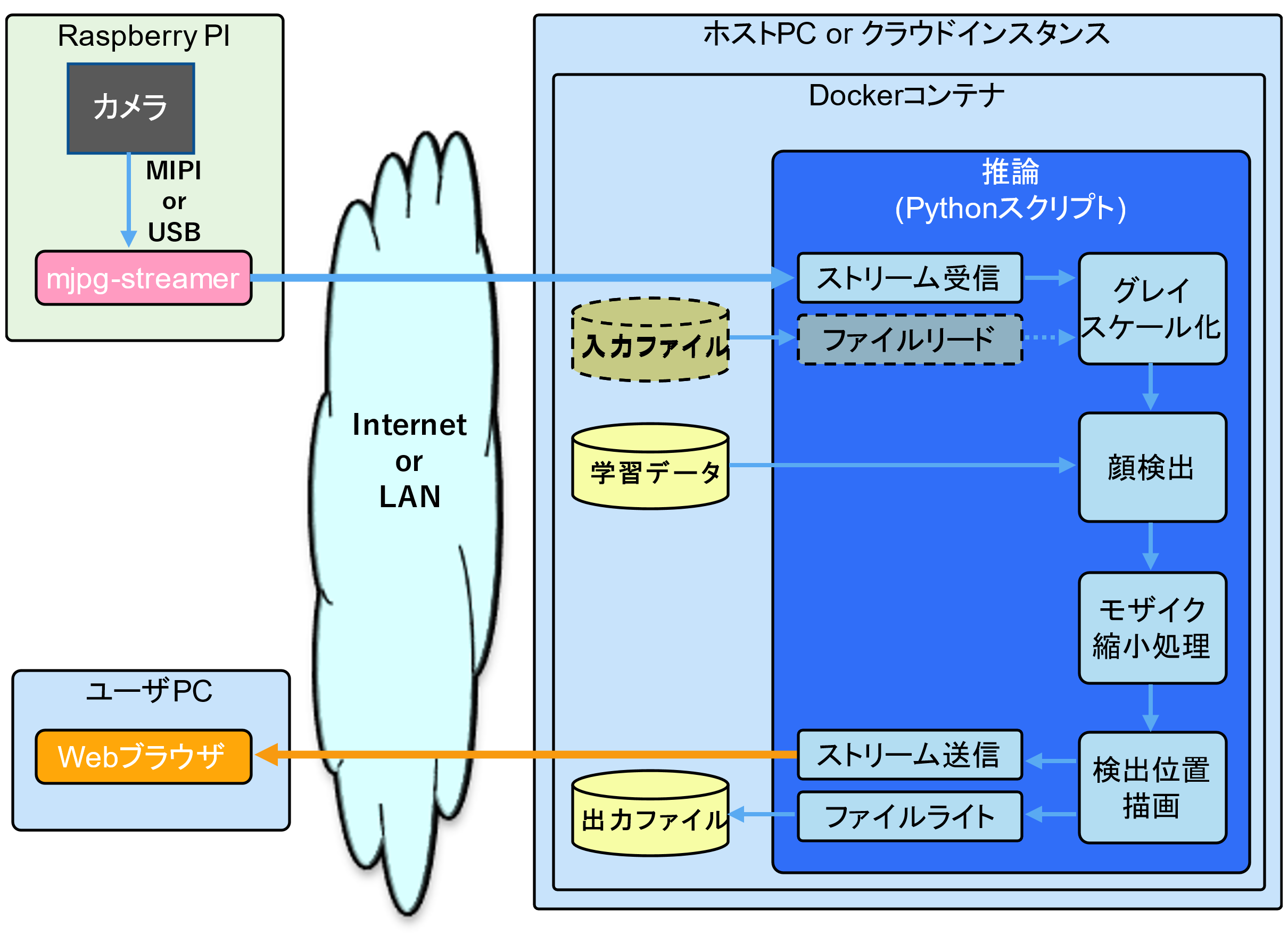
図4 OpenCVを使用した学習システムの
ソフトウェアの構成
Raspberry PIはmjpg-streamerでストリーミングします。このストリームはhttpで送信するのでWebブラウザ等で送信状態を確認することができます。
今回はシステム全体を組み上げることを優先するので手軽なhttpで送信しますが、後々必要に応じてMQTT、RTMP、RTSPやUDPを使った独自実装等に置き換えます。
推論内の「ファイルリード」は、カメラがない場合や解析処理の性能評価を行う上でカメラやネットワークの制約を排除するために使用します。
顔検出は学習済データを用いてCPU、GPUそれぞれで行います。
モザイク/縮小処理は、ストリームの帯域や出力ファイルのデータ量を抑えるためのものです。昨今取り上げられるカメラ映像のプライバシーの問題を回避する簡易策にも使えるのかもしれません。
検出位置描画では、顔と認識した箇所を示す緑の枠を描画します。一緒に、検出処理のフレームレートの瞬時値(左の値)、平均フレームレート(右の値)を描画します。
検出位置描画の出力はhttpで送信するとともにファイルにも保存し、結果を後で確認できるようにします。図5の画像は検出位置描画の例です。

図5 検出結果映像例
非常に長い前置きでしたが、次回から実際に環境を作っていきます。
いろいろと苦労はありましたがこれを使っていろんな実験をしてみたいと思います。
最後までご覧いただきありがとうございました!
次回もよろしくお願いします。











