PyTorchで学習したAIモデルをKV260で動かすまでの手順

みなさん、こんにちは!
今回は、AMD社が提供しているVitis AI Tutorialをベースに、PyTorchでMNIST(手書き数字認識)モデルを学習させてみた内容を紹介します!
実際にKV260上で動作確認も行いました。
使用したチュートリアルはこちら↓
Vitis-AI-Tutorials / 09-mnist_pyt at 1.4 · Xilinx / Vitis-AI-Tutorials · GitHub
MNISTとは、0~9の数字が格納されている手書き数字の画像データセットになります。
1. 作業概要
以下の手順でモデル変換を実行します。

- 環境構築
AIモデルを変換・実行するための環境構築(ツールインストール)を行います。
ツールはVitis AI 3.0とVitis AI Tutorials 1.4になります。 - ハードウェアデザイン設計
FPGA領域にDPU(一般的なNPUコアと同機能)を組み込む必要がありますが、今回はVitis AI GitHubに公開している「KV260のサンプルデザイン」を活用するため省略します。 - AIモデル変換
GPUのDocker Imageを起動し学習済みAIモデルとキャリブレーションデータの準備をします。
Vitis AIでは公開されている学習済みモデルにキャリブレーションデータもセットで提供されているため、サンプルモデルを利用する場合はキャリブレーションデータの準備を省略することができます。
準備ができた後、量子化とコンパイルを行います。 - アプリケーション作成
Vitis AI Tutorialに公開している「KV260サンプルデザイン」を活用するため省略します。
通常はユーザーガイドを参照しながら専用APIを用いてC++またはPythonでコーディングします。 - 実機確認
KV260を起動した後、必要なファイルをHost PCからKV260へ転送し推論を実行します。
2. 環境構築
この章ではAIモデルを動かすことができるようVitis AIの開発環境を構築していきます。
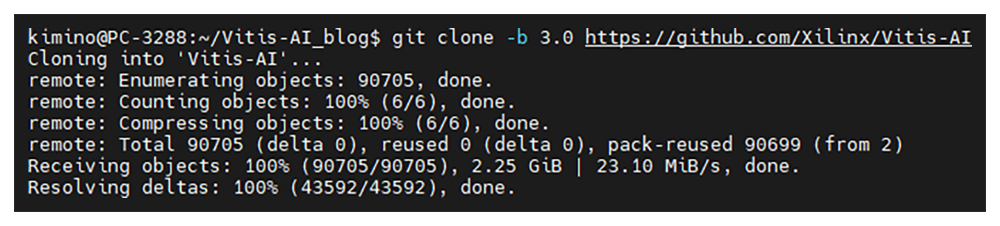
まず初めにVitis AI 3.0のプロジェクトをGitHubから自分のPCにクローンして取得します。
Gitを使って公式のソースコードやサンプルを丸ごとダウンロードし、自分の環境で使用可能にします。
実行コマンド
$ cd ~/[any folder] # 任意のディレクトリへ移動
$ git clone -b 3.0 https://github.com/Xilinx/Vitis-AI成功すると以下のような画面になります。
次にVitis AI Tutorials 1.4のリポジトリを自分のHost PCにクローンします。
これにより、指定したバージョンのチュートリアルやサンプルコードを手元で確認・実行・編集できます。
実行コマンド
$ cd Vitis-AI # Vitis AIディレクトリへ移動
$ git clone -b 1.4 https://github.com/Xilinx/Vitis-AI-Tutorials成功すると以下のような画面になります。

最後にDocker Imageビルドを行います。
今回はGPU3.5を使用します。
実行コマンド
$ cd ~/[any folder]/Vitis-AI/docker # dockerディレクトリへ移動
$ ./docker_build.sh -t gpu -f pytorchこの工程はGPU版を使用する場合のみ実行が必要となり、CPU版では不要となります。
CPU版でDocker Imageが不要な理由は、すでに必要なツールやライブラリが揃った状態で公式イメージとして提供されているためです。
3. ハードウェアデザイン設計
今回はVitis AI GitHubで公開されているサンプルを活用するため不要になります。
KV260に搭載しているZynq™ UltraScale+™ MPSoCはARM CPUを搭載したFPGAとなり、AI推論処理を行うDPU(一般的なNPUコアと同機能)をFPGA側に実装します。
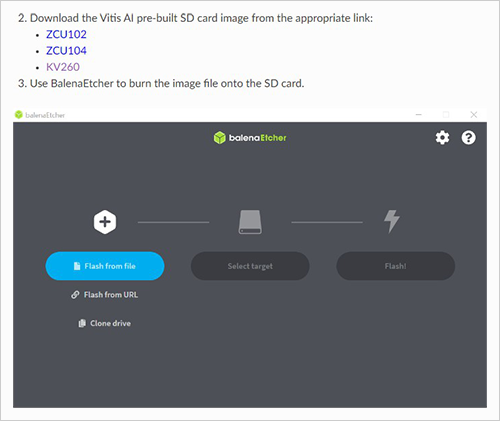
URLから以下のような画面が開きますので、KV260の部分をクリックしデザインをダウンロードした後にBalenaEtcherを使用して、画像ファイルをSDカードに書き込みます。
4. AIモデル変換

この章ではAIモデルを変換していきます。
最初に、変換するために学習済みAIモデルとキャリブレーションデータを準備します。
次に、学習済みAIモデルに対して量子化とコンパイルを実行します。
量子化により計算量とメモリ使用量を削減し、コンパイルによりハードウェアが直接実行できる形式に変換します。
① 学習済みAIモデル準備
最初に学習済みAIモデルを準備します。GPUのDockerを以下コマンドで起動します。
"docker image ls"コマンドで起動したいDockerのREPOSITORYとTAGを確認しDockerを起動します。
実行コマンド
$ ./docker_run.sh xilinx/vitis-ai-pytorch-gpu:3.5.0.001-1eed93cde正しくDockerが起動されると以下のような画面になります。

Dockerを起動すると、最初に入るディレクトリはイメージや設定によって異なります。
そのディレクトリにtrain.pyがない場合は、train.pyがあるディレクトリまで移動してから実行します。
逆に、起動直後のディレクトリにすでにtrain.pyがある場合は、移動せずにそのまま実行できます。
train.py実行時に、ターミナルに出力を表示しながら、同じ内容をログファイルに保存するコマンドを実行します。
ログを残すことで、後から精度推移を分析することやエラー解析や再現性の確保ができます。
実行コマンド
$ export BUILD=./build # 環境変数BUILDに./buildという値を設定
$ export LOG=${BUILD}/logs # 環境変数 LOG に ${BUILD}/logs という値を設定
$ mkdir -p ${LOG} # ${LOG} で指定されているパスにディレクトリを作成
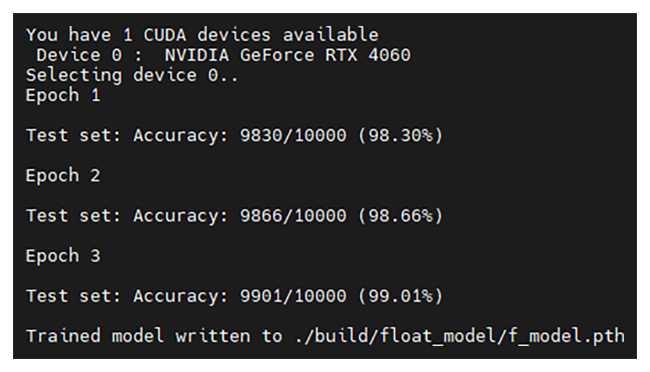
$ python -u train.py -d ${BUILD} 2>&1 | tee ${LOG}/train.log # train.py を実行し、その出力をログとして残しながら、画面にも表示train.pyをそのまま実行すると、学習データを取得する部分でエラーになるためファイルの修正が必要になります。L40-L45を以下のように修正します。
修正前のコード

修正後のコード

成功すると以下のような画面になります。3回学習が実行され、学習済みAIモデルが生成されます。
② キャリブレーションデータ準備
学習済みAIモデル準備した際にダウンロードされるため今回は省かせていただきます。
③ 量子化
学習済みモデルを最適化するために量子化を行います。
量子化は、浮動小数点を固定小数点に変換し、推論時の処理を高速化・省電力化する工程です。
この量子化を正しく行うためには、キャリブレーションと精度テストの2つが必要になります。
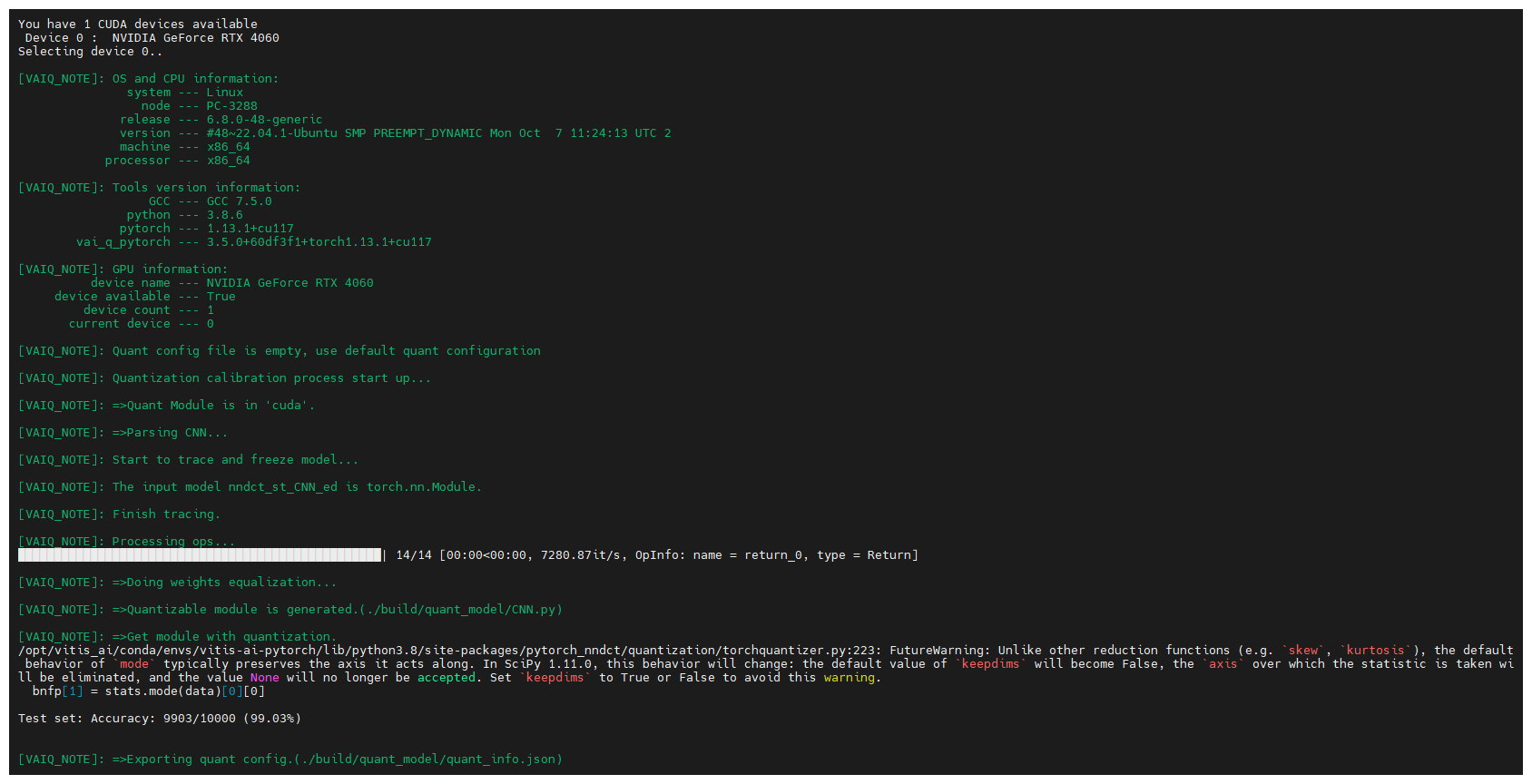
実行コマンド(キャリブレーション)
$ python -u quantize.py -d ${BUILD} --quant_mode calib 2>&1 | tee ${LOG}/quant_calib.log # quantize.pyを実行し量子化を行いつつ、その出力をリアルタイム表示しながらログに保存成功すると以下のような画面になります。
実行コマンド(精度テスト)
$ python -u quantize.py -d ${BUILD} --quant_mode test 2>&1 | tee ${LOG}/quant_test.log # quantize.py をテストモードで実行し、その出力をリアルタイム表示しながらログとして記録成功すると以下のような画面になります。

④ コンパイル
最後にコンパイルを実行します。
TutorialにはKV260の記載がないためcompile.shに追記する必要があります。

実行コマンド
$ source compile.sh KV260 ${BUILD} ${LOG} # compile.shを実行し環境設定やビルド処理を行う成功すると以下のような画面になります。コンパイル済みモデル(xmodel)が生成されます。

5. アプリケーション作成
Tutorialにある作成済みのアプリケーションを活用します。
以下URLのGitHubにある作成済みのアプリケーションをapp_mt.pyとして格納して完了となります。
Vitis-AI-Tutorials/Design_Tutorials/09-mnist_pyt/files/application/app_mt.py at 1.4 · Xilinx/Vitis-AI-Tutorials · GitHub


通常は、ユーザーガイドを参照しながら専用APIを用いC++もしくはPythonでコーディングしていきます。
6. 実機確認
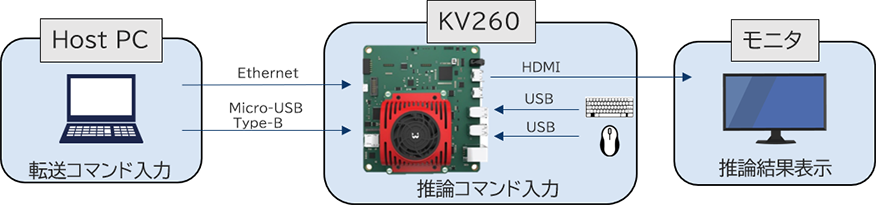
最後に実機確認をします。
KV260を起動した後、必要なファイルをHost PCからKV260へ転送し推論を実行します。
今回は、MNISTの画像1万枚を使って学習したモデルを推論します。
実行するとcompile.shがモデルをKV260用にコンパイルし、target_KV260フォルダが生成されます。
KV260へ転送
Host PCとKV260間で転送を行うときは同じネットワーク経由で転送する必要があります。
入力画像はimgファイルの中に格納されています。
実行に必要なファイルをフォルダとしてまとめ、KV260へ転送します。
Host PCでの実行コマンド
$ cd [any folder]/files/build # buildディレクトリへ移動
$ source compile.sh KV260 ${BUILD} ${LOG} # compile.shを、現在のシェル環境に反映しながら実行
$ scp -r target_KV260 root@[KV260 IPv4]:/home/root/ # Host PCからKV260へ転送推論実行
KV260での実行コマンド
$ cd ~/target_KV260 # target_KV260ディレクトリへ移動
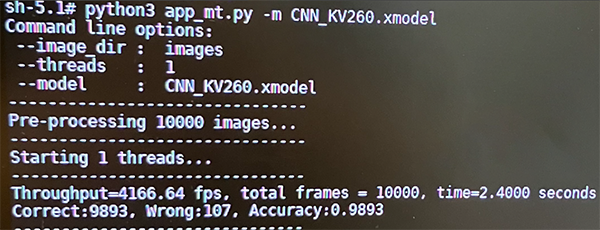
$ python3 app_mt.py -m CNN_KV260.xmodel # app_mt.pyを実行し、CNN_KV260.xmodel という学習済みモデルを指定してアプリケーションを動かす成功すると以下のような画面になり処理速度と認識率が表示されます。
結果としては一万枚の画像の推論に2.4秒かかり認識率は98%となっています。
1秒当たり4000枚以上の推論を実行していることがわかります。
7. まとめ
| ステップ | 使用ツール・環境 | 作業内容 |
|---|---|---|
| 環境構築 | Vitis AI 3.0 Vitis AI Tutorials 1.4 |
開発環境の構築 必要なパッケージとツールを準備 |
| ハードウェアデザイン設計 | KV260サンプルデザイン使用 | 作業不要 |
| AIモデル変換 | GPU3.5のDocker | 学習済みAIモデル準備 キャリブレーションデータ準備 量子化/コンパイル |
| アプリケーション作成 | Vitis AIから出力される API・サンプルを活用 |
作業不要 |
| 実機確認 | KV260 | Host PCからKV260へのデータ転送 推論実行 |
ぜひ本記事の内容を参考に、AIモデルの変換に挑戦してみてください。
実際に手を動かすことで、モデル変換の流れやKV260での推論の仕組みをより深く理解いただけます。
ご不明点やご相談がございましたら、お気軽にお問い合わせください。











