無償化したAIモデル最適化ツール「Vitis™ AI Optimizer」を試してみた(準備編)


-
皆さまこんにちは!TEPPE-AIです!
今回ご紹介するものは
『無償化したAIモデル最適化ツール
「Vitis™ AI Optimizer」を試してみた(準備編)』です。
Vitis™ AI Optimizer(以降、AI Optimizer)とは、AIモデルの軽量化を行うツールで、現在の最新バージョンではプルーニング(枝刈り)を活用しています。
Vitis™ AI最新バージョンである3.5で無償化かつオープンソース化され、注目度の高いツールになっています。
AI Optimizerの操作感を確認し、どの程度の性能がでるのか試してみたいと思います。本シリーズは、「準備編」、「検証編」の2部構成になっており、本記事は「準備編」になります。
是非最後までお付き合いいただけると嬉しいです。
それでは参りましょう。
目次
AI Optimizerについて
AI Optimizerは、Deep Learningモデルを最適化するツールで、現時点ではプルーナーというプルーニングを採用した手法が存在します。
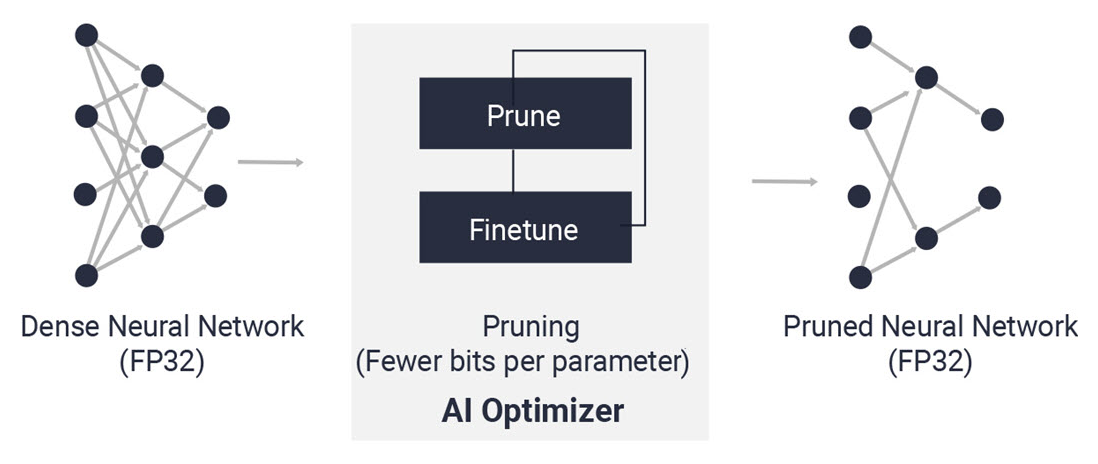
図1. AI Optimizerについて
AI Optimizerを活用することで、Deep Learningモデルの精度を担保しながら、サイズ圧縮することが可能で、量子化と併せて活用することでより高速に処理することが可能になります。
TensorFlowとPyTorchに対応しており、それぞれツールの名称が定義されています。
表1. AI Optimizerツール名

プルーニングには複数種類があり、ここでは「細粒度プルーニング」、「粗粒度プルーニング」で分類します。
- 細粒度プルーニング:小さなレベル(個々の重み)でプルーニングを実施
- 粗粒度プルーニング:大きなレベル(フィルタやチャネルなど)でプルーニングを実施
AI Optimizerでは、粗粒度プルーニングに対応しています。以下がユーザーガイドにある対応表で、DPUのIP(MPSoC、Versal、Alveo)ごとに対応しているか否かが記載していますが、細粒度はいずれも非対応になっています。
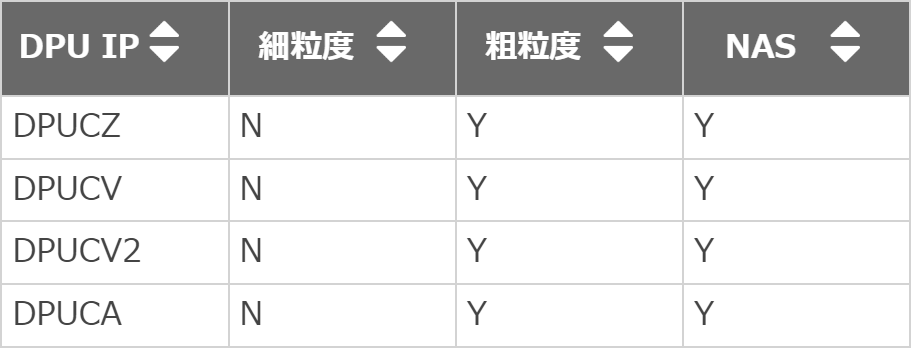
図2. DPU IP毎のプルーニング対応表
その他にNAS(Neural Architecture Search)という手法と掛け合わせてtaskに応じて最適なアーキテクチャ(レイヤー、ハイパーパラメータ、モジュール等)を見つけ、サイズを抑えつつ精度を担保する方法もありますが、今回はプルーニングにフォーカスしていきます。
プルーニングとは
プルーニングとは、前述した通り、Deep Learningモデルのサイズを圧縮し演算コストを削減する手法です。
細粒度プルーニングと粗粒度プルーニングのイメージが以下の通りです。
- 細粒度プルーニング:重み(〇をつなぐ矢印)をプルーニング
- 粗粒度プルーニング:フィルタ、ノード等(〇)をプルーニング
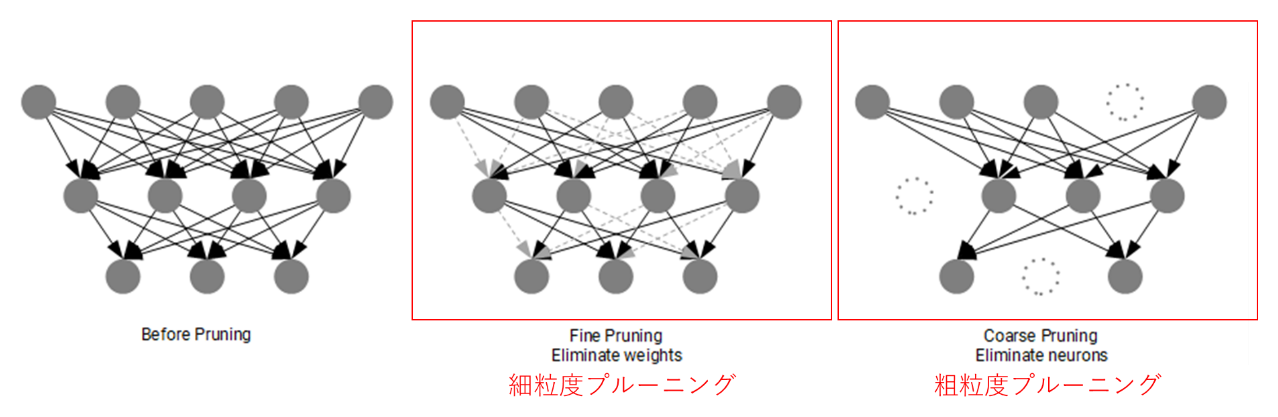
図3. 細粒度プルーニングと粗粒度プルーニングについて
プルーニングの処理フローの種類として、反復プルーニングとワンステッププルーニングの大きく2種類存在します。
反復プルーニング
反復プルーニングでは、徐々にプルーニングを行います。「分析」、「プルーニング」、「微調整(ファインチューニング)」、「変換」の工程で構成され、分析を行ったのち、精度とモデルサイズのベストなバランスがとれるまでプルーニングと微調整を繰り返し行います。
最後にAI Quantizerで量子化できる形に変換し、完了となります。
以下が、反復プルーニングの工程イメージで、プルーニングと微調整を繰り返して、サイズ減少に伴う精度劣化を回復させていることが分かります。
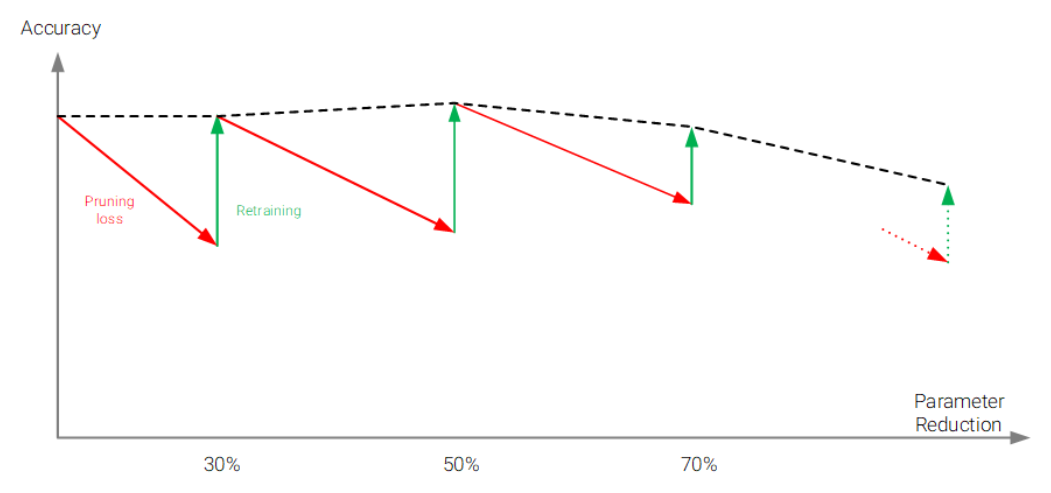
図4. 反復プルーニングの繰り返し工程について
ワンステッププルーニング
一気に対象をプルーニングします。工程としては、反復プルーニングと変わりませんが、プルーニングと微調整は1度で終了します。
表2が、反復プルーニングとワンステッププルーニングの比較がこちらになります。
表2. 反復プルーニングとワンステッププルーニングの比較

どれも一長一短な感じですね。今回は、反復プルーニングを用いていきます。
作業概要
今回は、Vitis™ AI Tutorialにある チュートリアルに沿って作業を進めていきます。
作業の流れは以下の通りで、KV260上でAIモデルを動作させていきます。
実際にプルーニング処理を実施するのは作業(host PC)なのですが、終わったらすぐに動かせるように、KV260用のSDカードの作成を今回ご案内しちゃいます!

図5. 作業概要
以下が今回用いたチュートリアルで、vai_p_tensorflow2を用いたフローになります。
Target boardにKria KV260が含まれていませんが、今回の検証で動作確認済みですのでご安心ください。
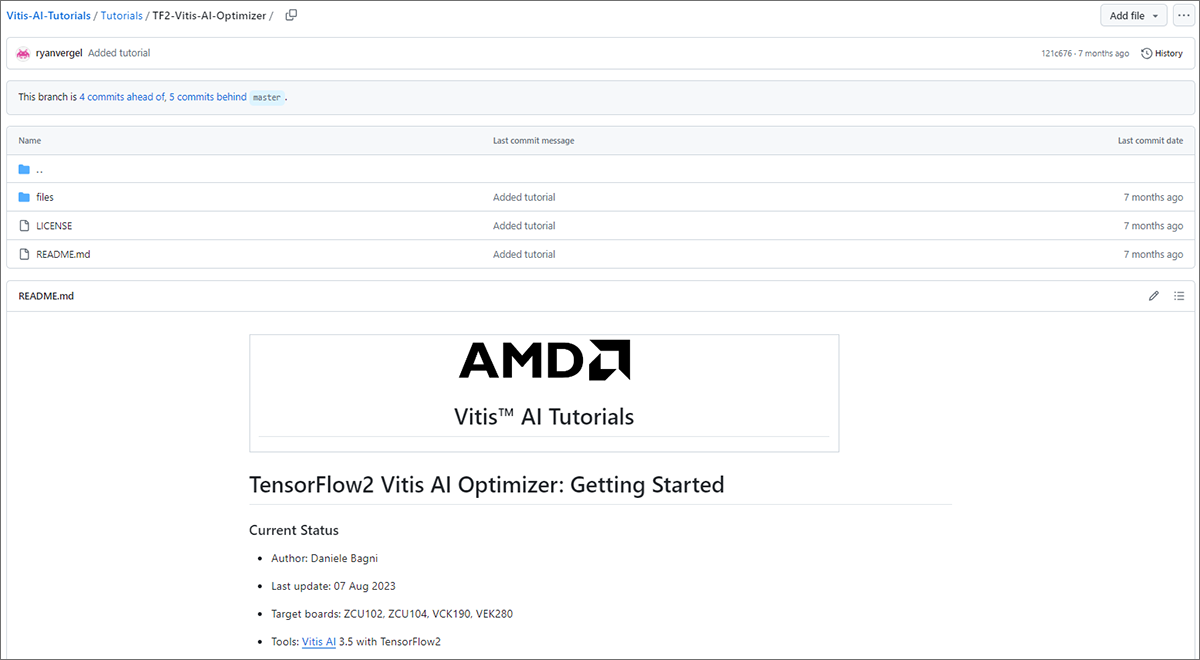
図6. Vitis™ AI Tutorial(TensorFlow2 Vitis AI Optimizer)
用いる環境は、表3の通りです。
表3. 使用デバイス環境
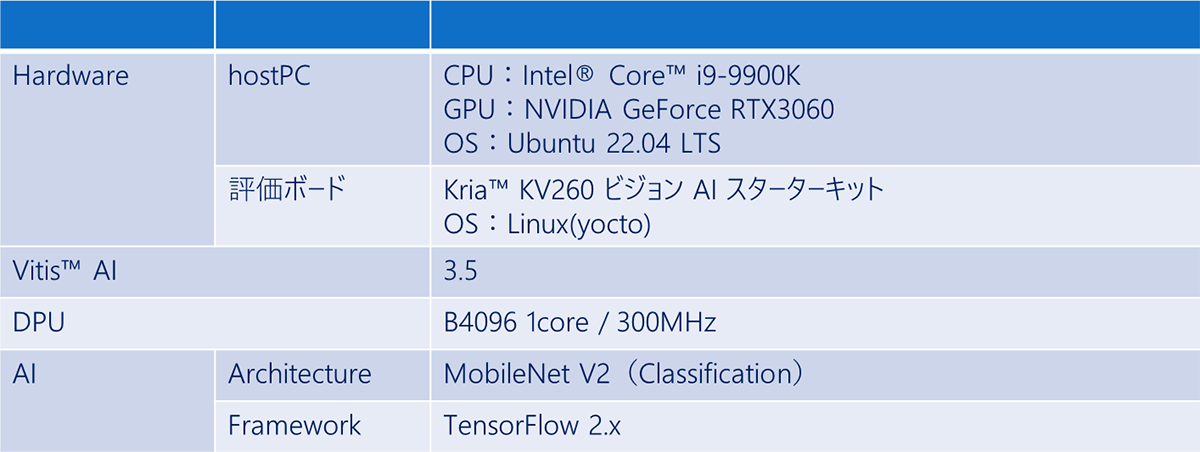
使用機材
| hostPC | OS | Ubuntu 22.04 LTS | Linux環境が必須となりますのでご注意ください。 今回はGPUがあると便利です。 |
|
|---|---|---|---|---|
| 作業項目 | ②学習済みモデル作成、③プルーニング、④量子化/コンパイル | |||
| Kria™ KV260 ビジョン AI スターターキット | Linux(yocto) | 今回はリファレンスデザインを用いて検証を行います。 | ||
| 作業項目 | ⑤実機確認 | |||
| KV260操作用PC | Windows10 | USB-UARTでKV260を操作しますので、操作用のソフト、ドライバのインストールをお願いします。 | ||
| 作業項目 | KV260操作 | |||
| microSDカード | Micron製 産業用 micro SDカード 32GB | リファレンスデザインはSD IMGのため、起動用として用意します。 PALTEKで取り扱っておりますので、気になる方はこちらからご確認お願いします。 |
||
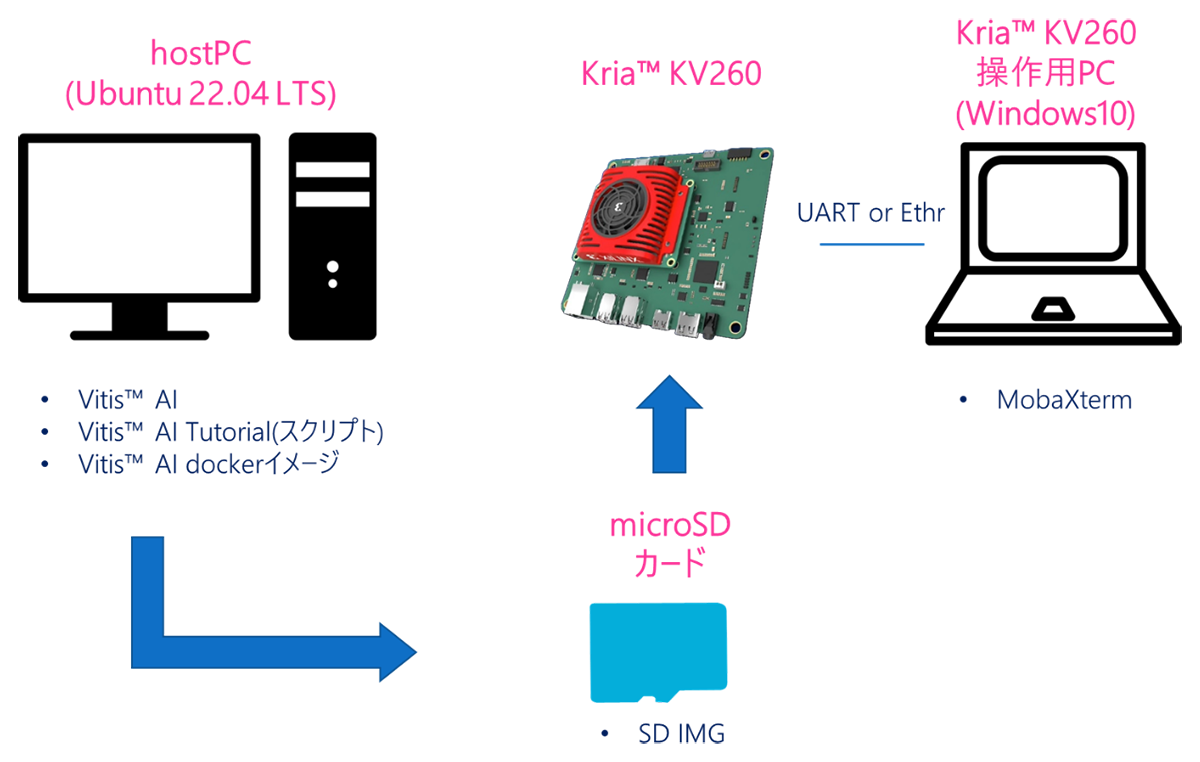
図7. 接続イメージ
デバイス環境構築
hostPC
Vitis™ AIダウンロード
以下コマンドでダウンロードします。
$ cd ~/Vitis/vitis_r3.5
$ git clone -b 3.5 https://github.com/Xilinx/Vitis-AIVitis™ AI Tutorialダウンロード
以下コマンドでダウンロードします。
$ cd ~/Vitis/vitis_r3.5
$ mkdir Vitis-AI-Tutorial
$ git clone -b 3.5 https://github.com/Xilinx/Vitis-AI-Tutorials/Vitis™ AI dockerビルド
変換環境として、dockerを用います。
前回の記事でCPU版とGPU版があると記述しましたが、今回はGPU版を推奨します。
学習工程を含むことと、反復プルーニングを用いるため、CPU版の場合かなりの処理時間がかかってしまうためです。
<CPUの場合>
Docker hubからビルド済みのイメージをダウンロードします。
こちらからアクセスし、Vitis AI 3.5、TensorFlow2版を選択します。
図8の「xilinx/vitis-ai-tensorflow2-cpu」をクリックします。
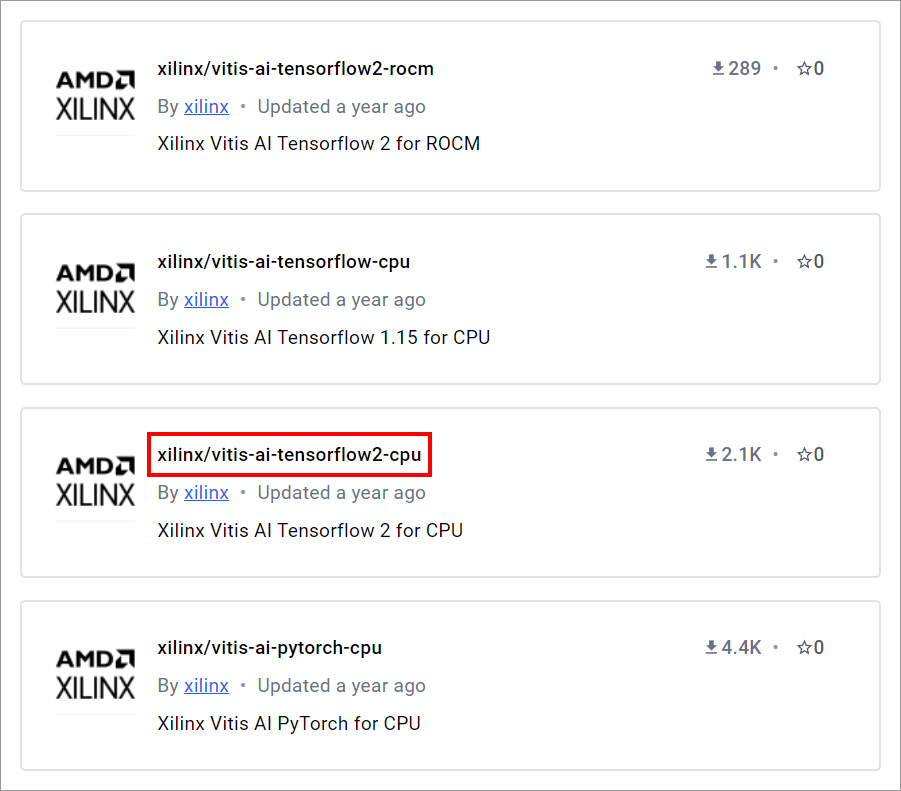
図8. Docker hub AMD(xilinx)提供Docker imageページ
「Tags」を選択すると、Vitis AIのバージョンごとにコマンドが記述されています。
今回は、図9赤枠「TAG:ubuntu2004-3.5.0.300」のコマンドを用います。
- ※
- 開発マシン(hostPC)のOSはUbuntu22.04ですが、Docker上ではUbuntu20.04になります。
作業にあたっての支障はないのでご安心ください。
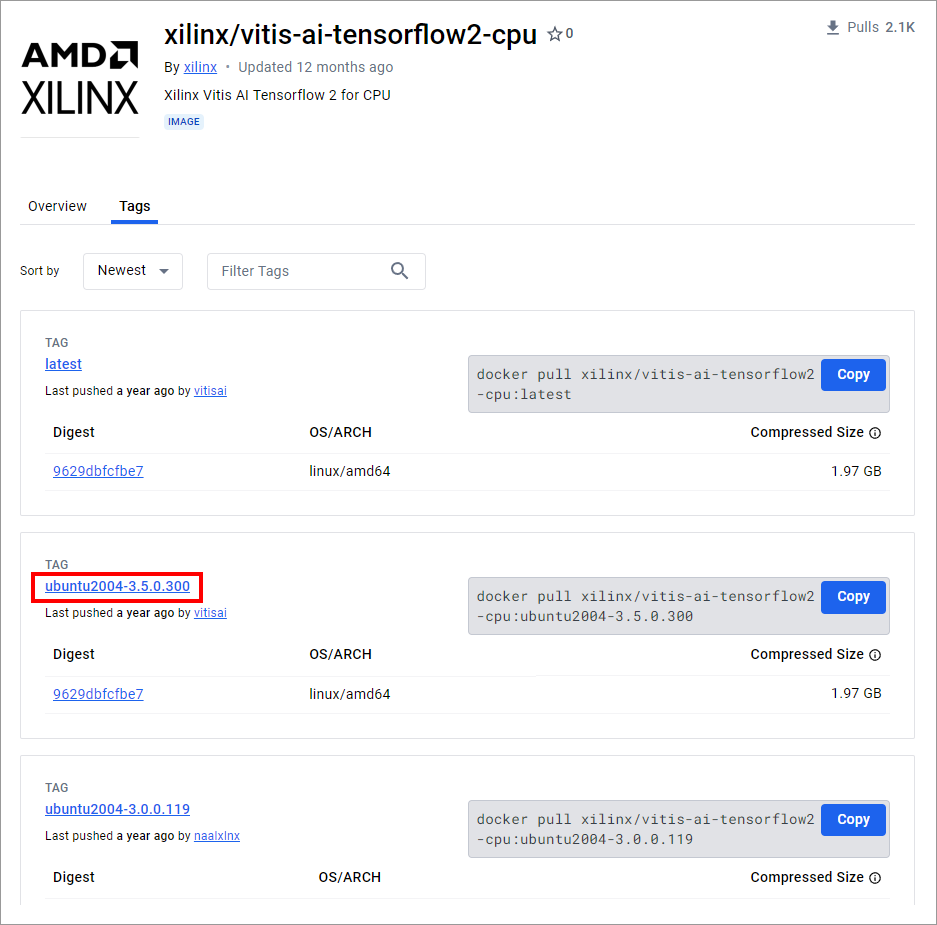
図9. Docker hub TensorFlow2版Docker image一覧
出典:dockerhub,xilinx/vitis-ai-tensorflow2-cpu
CPU版dockerイメージのインストールコマンドが以下となります。
$ docker pull xilinx/vitis-ai-tensorflow2-cpu:ubuntu2004-3.5.0.300実行完了後、ビルド完了しているか確認します。
REPOSITORY:xilinx/vitis-ai-tensorflow2-cpuが表示されていれば、ビルド完了です。
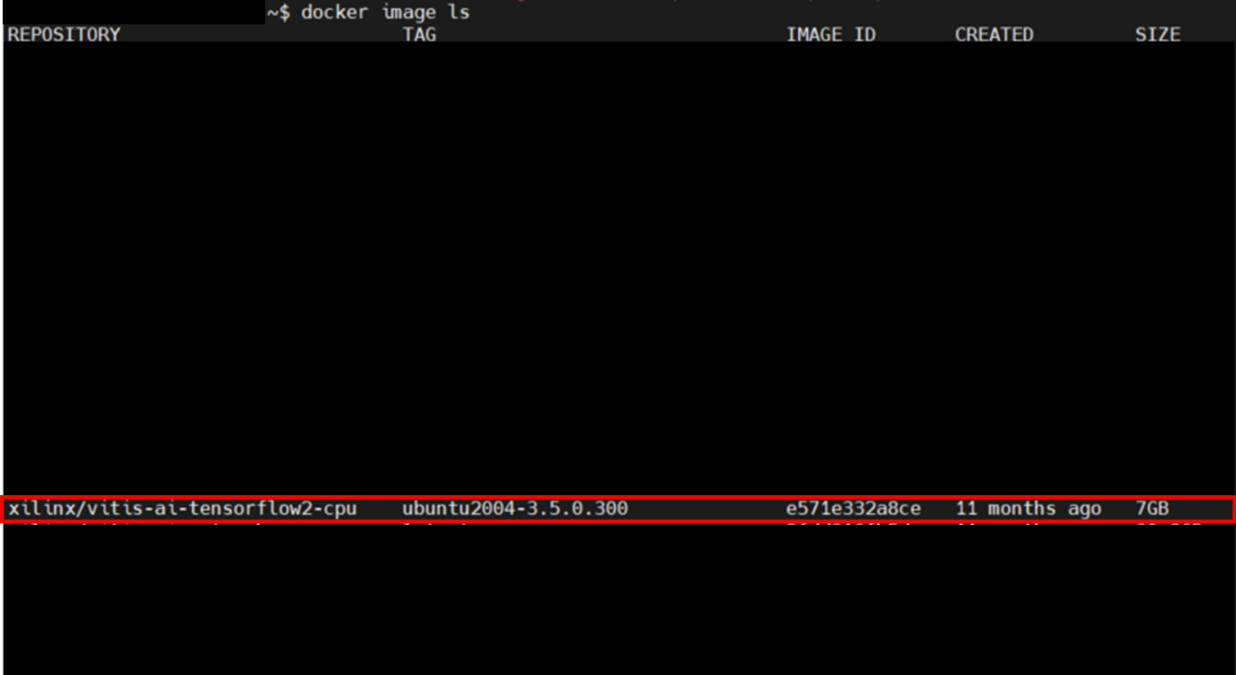
図10. docker image 出力画面①
<GPUの場合>
Vitis™ AI GitHubにあるdockerイメージビルドスクリプトを活用します。
Vitis-AI/dockerディレクトリ内のdocker_build.shが該当のスクリプトになります。
各種オプションがあるので、実行する際はこちらを併せてご参照ください。
$ cd ~/Vitis/vitis_r3.5/Vitis-AI/docker
$ ./docker_build.sh -t gpu -f tf2実行完了後、CPU版と同様、ビルド完了しているか確認します。
REPOSITORY:xilinx/vitis-ai-tensorflow2-gpu
が表示されていれば、ビルド完了です。
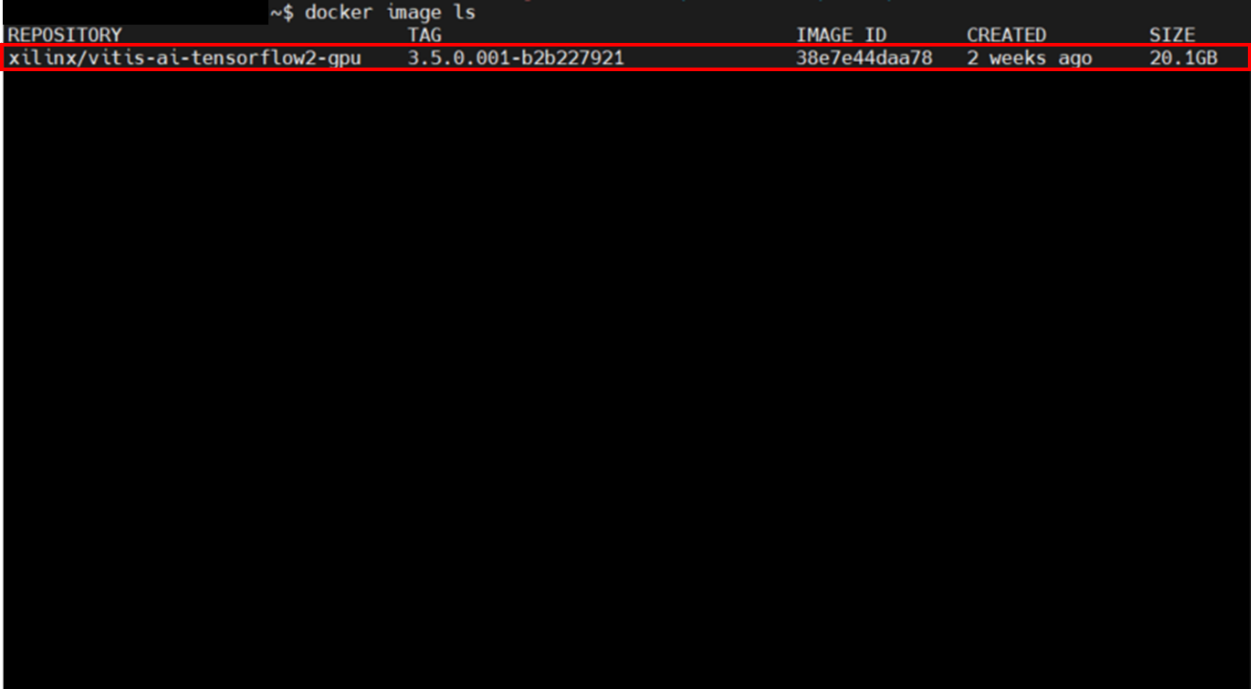
図11. docker image出力画面②
評価ボード
リファレンスデザイン SD IMG書き込み
GitHub上にあるリファレンスデザインをダウンロードします。
今回は、Vitis™ AI 3.0ベースのデザインを活用します。Zynq MPSoC向けDPUはVitis™ AI 3.0が最新版となっており、3.5用のリファレンスデザインは用意されていません。
ただし、用いるチュートリアルにも記載していますが、Vitis™ AI 3.0のデザインを活用するように、とのことなので、活用します。
- ※
- ページ内はZCU102と書いていますが、KV260のイメージを活用します。
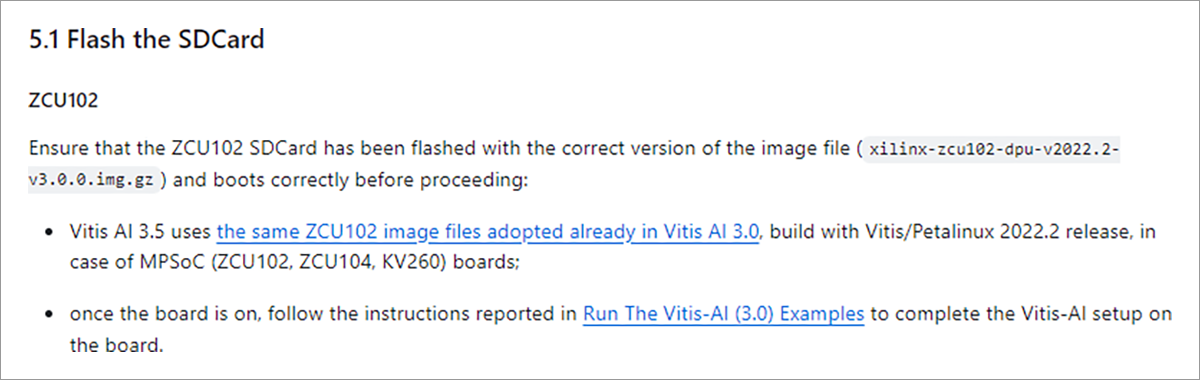
図12. Vitis™ AI Tutorial 使用イメージについて
図13の赤枠箇所をクリックすると、ダウンロードされます。
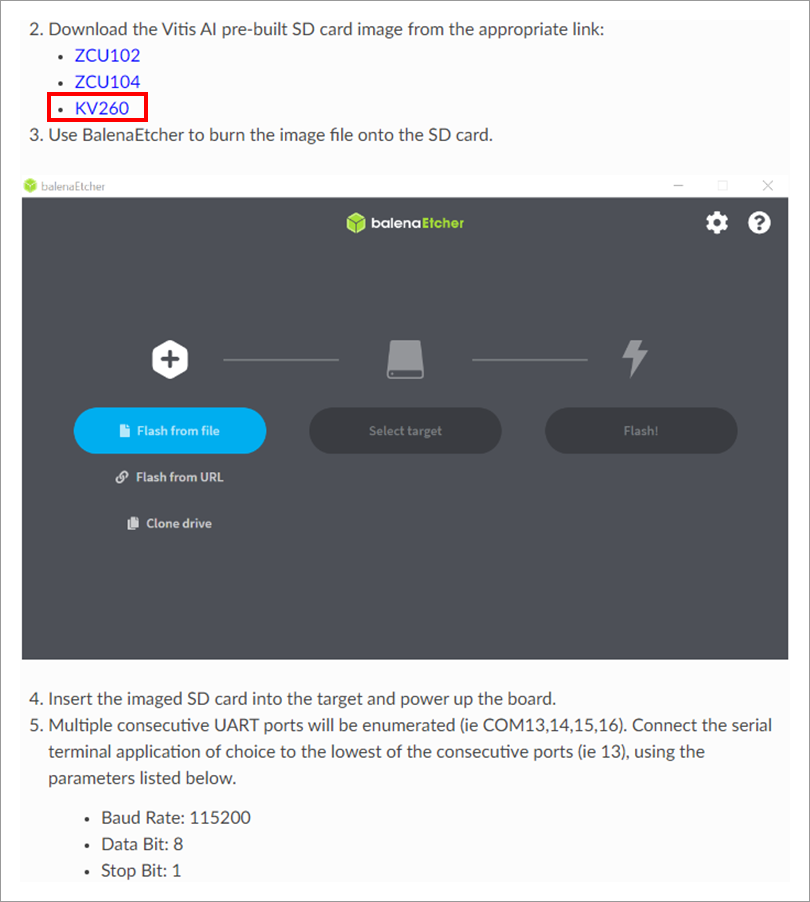
図13. リファレンスデザイン格納先
出典:Quick Start Guide for Zynq™ UltraScale+™
インストール後、SD書き込みツール等を用いてmicroSDカードに書き込んで準備完了です。
おわりに
最後まで閲覧頂きありがとうございました。
今回は準備編ということで、以上になります。
次回は実際にAI Optimizerを試す検証編となります。
それではまた。TEPPE-AIでした~



















