Xilinx社Zynq® UltraScale+™ MPSoCに複数のDPUコアを実装し各々のDPUコア上で異なるVitis™ AI Model Zooを動かしてみた


-
皆さまこんにちは!TEPPE-AIです!
So-Oneモジュールの記事第4弾です!
朝晩めっきり冷えてきましたね。
私の地元でもある新潟では、この時期はあたり一面銀世界が広がります。
某ウィルスもまだまだ油断はできないと思いますので、今一度気を引き締めて過ごしていきたいです!
さて、今回は今までとは異なった観点の記事となります。
「Xilinx社Zynq® UltraScale+™ MPSoCに複数のDPUコアを実装し各々のDPUコア上で異なるVitis™ AI Model Zooを動かしてみた」
今回は、 Zynq® UltraScale+™ MPSoCに複数のDPUコアを搭載し、それぞれのDPUコアで異なるAIモデルを実装し並列に動かしてみました!

-
DPUデザイン上で、複数のAIモデルを同時並列に動かせないか?
こう思い調べていたところ、Vitis™ AI GitHubのサンプルに存在しておらず・・・
-
DPUデザイン上で実現できないの!?
と思い、どうにかして実現できないかと検証を行いました。
結果、複数のDPUコアを実装することで複数のAIモデルを同時並列に動作させることができました!
今回は、動作手順の紹介の前に検証結果をお伝えして、皆さまの参考になればと思います!
是非最後まで見てくださいね!
それでは参りましょう!
目次
概要
冒頭でもお話しした通りですが、Vitis™ AIのDPU処理で、複数のAIモデルを並列に動作させる資料やサンプルが存在していませんでした。
※ただ、以下のサンプルは存在しております。
- マルチタスク:複数のAIモデルを単一AIモデルに結合してからDPU上で動作
- マルチスレッド:単一AIモデルを複数のDPU上で並列動作
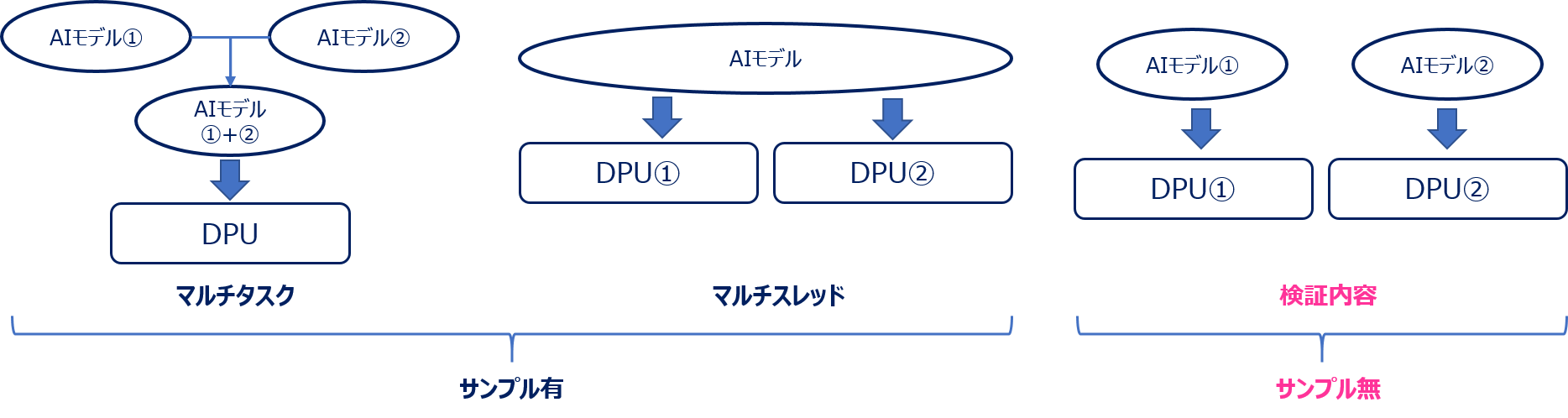
そのため、「複数のAIモデルをそれぞれのDPUを使い、並列動作させることは可能なのか?」と思い 検証してみたところ、無事動作させることに成功しました。
今回の検証過程で、複数のDPUコア実装を行った場合のメリットやデメリット、 性能差分も明確になりましたので、紹介いたします。
以下のような流れで解説していきます。
- DPUコアを複数実装する際のメリット
- DPUコアを複数実装する際のデメリット
- 検証結果
DPUコアを複数実装する際のメリット
AIモデルを同時に並列動作可能
DPUコアを複数実装することで、AIモデルが互いに影響することなく処理することが可能です。

-
複数のAIモデルを並列動作させるケース
皆さまは何を思い浮かべますか?
私であれば、自動運転での事故防止が思い浮かびます。
例えば、以下のような要件定義をしたとします。

-
自分が走っている車線を検出しつつ
周辺にいる車を検出して事故を事前に防ぎたい
この場合、各々以下の画像認識AIモデルが適用されるかと思います。
- 走っている車線を検出 ⇒ セグメンテーション
- 周辺にいる車を検出 ⇒ 物体検出
※イメージ
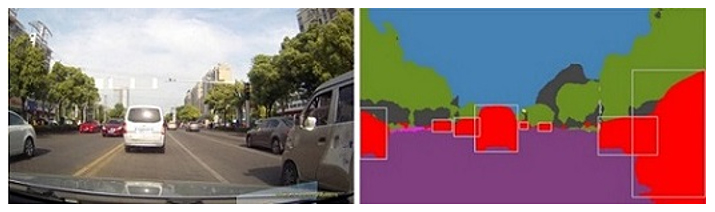
出典:Vitis AI ユーザー資料 APIリファレンス vitis::ai::MultiTask
https://japan.xilinx.com/html_docs/vitis_ai/1_2/oas1583339931693.html (参照 2021/12/27)
それらを並列に動かすことで、 目的である「事故の事前防止」が実現されるかと思います。
DPUコアを複数実装する際のデメリット
選択するDPUコア次第では必要とするFPGA回路規模が大きくなる
DPUのアーキテクチャはB512~B4096まで計8種類存在します。
※詳細は、 こちら をご参照ください!
DPUアーキテクチャはそれぞれ必要とする回路規模が異なります。
大きくなればそれだけ処理性能が向上しますが、その分求められるFPGA回路規模も大きくなります。
以上のメリット/デメリットを理解した上で、今回は規模の大きいDPUアーキテクチャ1つと規模の小さいDPUアーキテクチャ2つを搭載し処理を行った場合、どういった差分が生まれるか当社が開発したSo-One KITに実装して検証も行っておりますので以下検証結果をご覧ください。
- DPU1コア:B1600を1つ搭載
- DPU2コア:B512を2つ搭載
※So-One KITはDPU1コアの場合B4096まで実装することができます (2021/12現在)
検証結果
検証結果を解説します!今回は、以下の検証を行いました。
- ① AIモデルをDPUコア個数別(1コア,2コア)で比較
- ② 異なるAIモデルを独立に動作可能か
- ③ DPU1コア・2コアでの性能比較
測定対象範囲は、AI処理の前処理~後処理までの全工程になります。
モデルは、Vitis™ AI Model Zooにある以下3種類を使用しました。
以下3種類の違いは、モデル作成に用いたフレームワークのみとなります。
- resnet50(Caffe)
- resnet50(Tensorflow v1)
- resnet50(Tensorflow v2)
測定条件は、以下の通りです。
| DPU コア数 | 1 | 2 |
|---|---|---|
| DPU arch | B1600 | B512 |
| DPU RAM Usage | High | Low |
| DPU URAM | Disable | Enable |
| DPU clock | 300MHz | |
| DPU Version | v3.3 | |
| Xilinxツールバージョン | v2020.2 | |
| Vitis™ AIバージョン | v1.4 | |
① AIモデルをDPUコア個数別(1コア, 2コア)で比較した結果
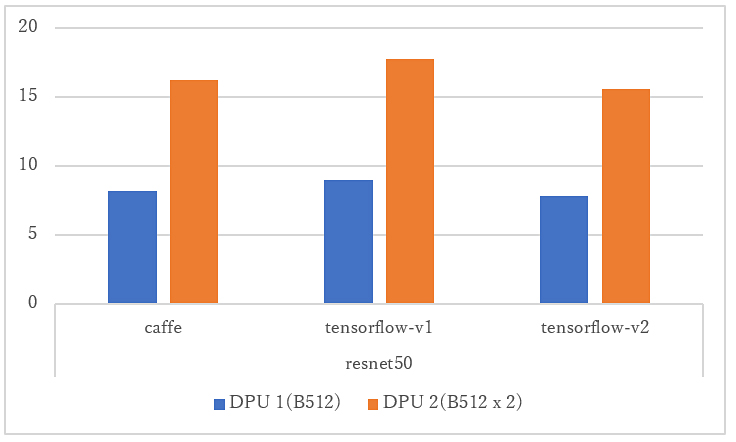
2コアにしたことで、1コアと比べ性能が倍になったことが分かりました。
② 異なるAIモデルを独立に動作可能か
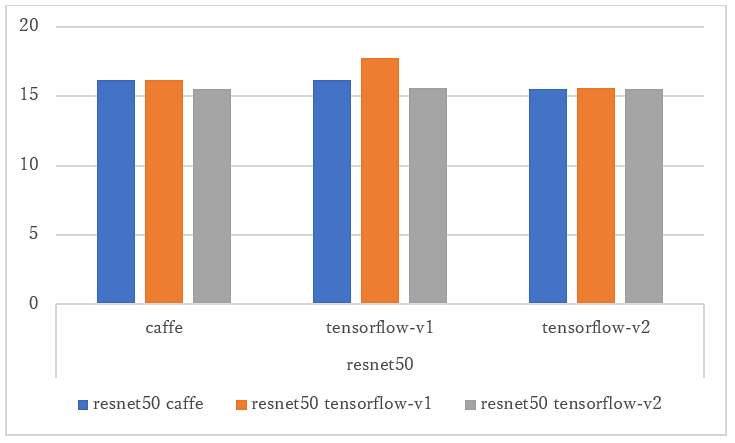
上記グラフは、異なるAIモデルをDPU2コアで動作させた結果になります。
①の2コアの場合の結果とほぼ同じであり、それぞれ独立して動いていることが分かります。
仮に独立で動いていなかったら、処理速度が半減してしまいますが、そのようにはなっていません。
③ DPU1コア・2コアでの性能比較
So-One KITでDPU 1コア(B1600 x 1)と2コア(B512 x 2)で どちらの処理が高速か、検証してみました。
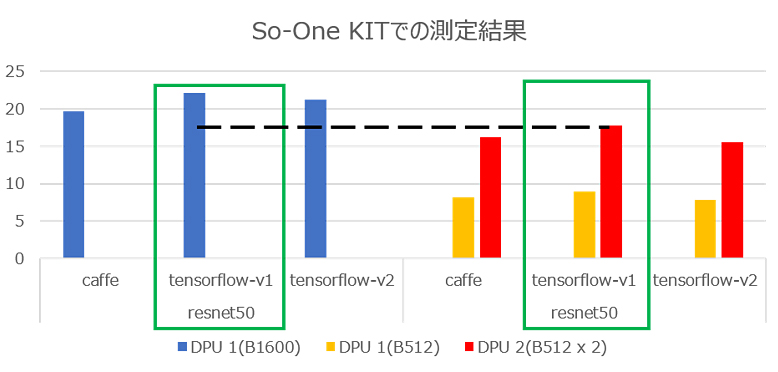
緑枠でハイライトした、2箇所にご注目ください。
1コアの場合、約22FPSなのに対し(青の棒グラフ)、
2コアの場合、約17FPSとなっています(赤の棒グラフ)。
So-One KITの場合、2コアよりも1コアを実装させたほうが 処理性能が高い、という結果になりました。
作業手順について
結果やメリットデメリットが分かったところで、最後にSo-One KITでの実証環境を構築する手順を説明していきます。
主な登場ツールとしては、 「 Vitis ™」 「Vitis™ AI 」 となります。
今回は、Vitis™ AIでの操作にフォーカスして解説していきます。
Vitis™については、同じチームのHさんより「ここだけは気を付けろ!!」と 注意点,変更点を共有いただいたので、そちらも解説させていただきます。
それでは参りましょう!!
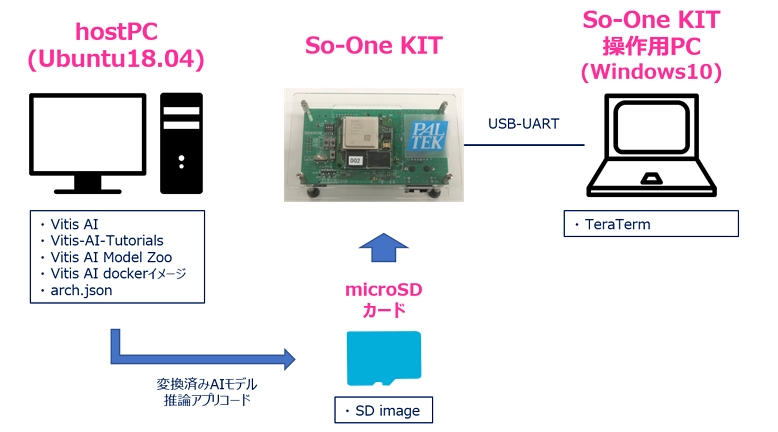
使用機材
| HostPC | OS : Ubuntu18.04 | 今回は、Linux環境が必須となりますので、ご準備をよろしくお願いいたします! このPCで「コンパイル」「実装準備」を実行します。 |
|---|---|---|
| 評価ボード操作用PC | OS:Windows10 | 評価ボードを操作するために用います。 今回は、TeraTermといったコンソール接続ソフトを用いて評価ボードを操作しました。 |
| 評価ボード | So-One KIT | ※So-One KITにご興味があるお客様は こちら ! |
| microSDカード | Micron製 industrial micro SD card 32GB | SDブートモードを用いて起動するので、microSDカードを用意しました。 ※So-One KITはeMMCブートでの起動も可能です。 |
※接続イメージ
事前準備
HostPC
・So-Oneアーキテクチャファイル、SDイメージダウンロード
Vitis™での作業については省略しますが、 生成される以下ファイルを[~/Vitis/vitis_r1.4/VitisOutput]ディレクトリに保存します。
- So-Oneアーキテクチャファイル ※本記事ではarch.jsonとします。
- SDイメージ ※本記事ではsd_card.imgとします。
※今回のデータは現状未公開となっております。
これにて事前準備完了です。
それでは、作業に移っていきましょう!!
Vitis™注意事項
今回、2つのDPUコアを搭載したデザインを作成するにあたり、Vitis™を用います。
Vivadoは用いません。
DPUを実装するフローは以下の流れになります。
- ① Vivadoで足回りを設計
- ② PetalinuxでOS作成
- ③ Vitis™でDPUを実装
今回①②は、当社が提供しているリファレンスデザインを用いたので、省略させていただきます。
③について、DPU2コアを実装するにあたっての注意事項及び変更項目を解説します!
細かな手順については、当社が提供している手順書(P9~P48)に記載がございますので 併せてそちらもご参照ください!
・注意事項:Vitis™プロジェクトのcleanは気を付けて!!
Vitis™で「ApplicationProject」のみをcleanしたとき、バグの影響か、「PlatformProject」まで cleanされてしまう、とのことです!
対応策として、「PlatformProject」をBuildし直すことで対処できますので、ご注意願います!
・変更項目:DPU接続設定
DPU2コアとなるので、接続設定を変更します。
以下コマンドで対象ファイルを開き、変更内容を参照して変更してみてください!
$ vim [Vitis作業フォルダ]/so-one_dpu_app/src/prj/Vitis/config_file/prj_config_gui※変更内容
====<変更内容ここから>====
[clock]
freqHz=150000000:DPUCZDX8G_1.aclk
freqHz=300000000:DPUCZDX8G_1.ap_clk_2
freqHz=150000000:DPUCZDX8G_2.aclk
freqHz=300000000:DPUCZDX8G_2.ap_clk_2
[connectivity]
sp=DPUCZDX8G_1.M_AXI_GP0:HPC0
sp=DPUCZDX8G_1.M_AXI_HP0:HP1
sp=DPUCZDX8G_1.M_AXI_HP2:HP2
sp=DPUCZDX8G_2.M_AXI_GP0:HPC0
sp=DPUCZDX8G_2.M_AXI_HP0:HP3
sp=DPUCZDX8G_2.M_AXI_HP2:HPC1
#nk=DPUCZDX8G:2
====<変更内容ここまで>====※変更にあたっての注意事項①
MPSoCに存在するHPポートはHP0~3の4本になりますが、HP0を使用するとDisplayPort出力に影響が出ることがあります。
DPUごとに2本のHPポートが必要ですが、DPUを2コア実装してHP0を回避すると1本不足するため、今回はHPC1ポートで代用しました。
※変更にあたっての注意事項②
DPU個数設定「nk=」行をコメントアウトしておくことに注意してください!!
DPU個数設定「nk=」行を有効にすると、ビルド時に以下のような分かりにくいエラーが出てきます
ERROR: [v++ 60-696] Failed to create Compute Unit. Compute Unit with name 'DPUCZDX8G_1' already exists.
・変更項目:DPU個数設定
Vitis™上で、DPUの個数を2つと設定してください。
・変更項目:DPUコンフィグ設定
DPU2コアとなるため、適切なサイズのDPUコアやURAM、RAM設定します。
今回はB512、URAM有効、RAM LOWとします。
以下コマンドで対象ファイルを開き、変更内容を参照して変更してみてください。
$ vim [Vitis作業フォルダ]/so-one_dpu_app_kernels/src/prj/Vitis/dpu_conf.vh※変更内容
====<変更内容ここから>====
//`define B4096
`define B512
//`define URAM_DISABLE
`define URAM_ENABLE
//`define RAM_USAGE_HIGH
`define RAM_USAGE_LOW
====<変更内容ここまで>====※変更にあたっての注意事項
このファイルでDPU実装規模を設定します。
使用するデバイスのPLリソースに応じて、PLリソース内に収まるように設定する必要があります。
PLリソース内に収まらないと、ビルド時にエラーが出るのでご注意ください!
作業(HostPC)
Vitis™ AI ダウンロード
以下コマンドでダウンロードします。
$ mkdir -p ~/Vitis/vitis_r1.4
$ cd ~/Vitis/vitis_r1.4
$ git clone --recurse-submodules -b v1.4 https://github.com/Xilinx/Vitis-AI.gitVitis™ AI Dockerイメージダウンロード
docker hubからdockerイメージをダウンロードします。
※今回はCPU版です。
$ docker pull xilinx/vitis-ai-cpu:1.4.916Vitis™ AIランタイムダウンロード
So-One KIT上で用いるランタイムをダウンロードします。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI
$ mkdir -p work_so-one/compiled_output
$ cd work_so-one
$ url=https://www.xilinx.com/bin/public/openDownload?filename=vitis-ai-runtime-1.4.0.tar.gz
$ wget -O ${url##*=} ${url}実行後、以下のような出力が出てきます。
※画像クリックで大きな画像が表示されます。
上記はCUI環境で行っていますが、デスクトップ環境であれば、
「https://www.xilinx.com/bin/public/openDownload?filename=vitis-ai-runtime-1.4.0.tar.gz」
をwebブラウザのアドレスバーにコピペするのみで、ダウンロードが可能となります。
AIモデル変換スクリプト作成
今回は、Caffe, Tensorflow-v1, Tensorflow-v2全て用いますので、3つ作成します。
・Caffe / Tensorflow-v1
2つに関しては、提供している手順書の通りに作成します。
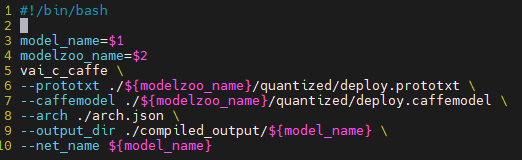
Caffe版変換スクリプト
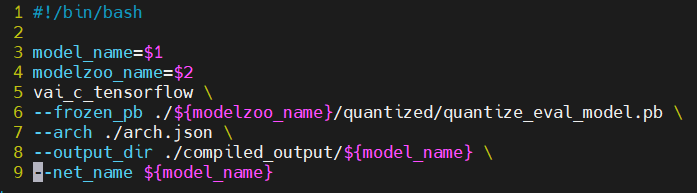
Tensorflow-v1版変換スクリプト
・Tensorflow-v2
Tensorflow-v2については、以下のように記載します。
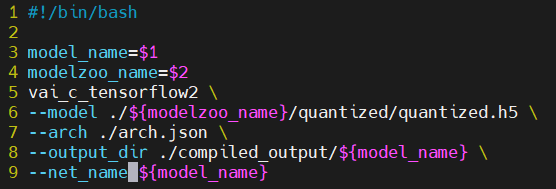
Tensorflow-v2版変換スクリプト
AIモデルダウンロード
今回用いる、学習/量子化済みのAIモデルをXilinx AI Model Zooからダウンロードします。
「AIモデル変換スクリプト作成」と同様、Caffe, Tensorflow-v1, Tensorflow-v2それぞれで 2つのファイルをダウンロードしています。「~~.zip」「~~.tar.gz」
※AIモデルはresnet50です。
・Caffe
「cf_resnet50_imagenet_224_224_7.7G_1.4」を用います。
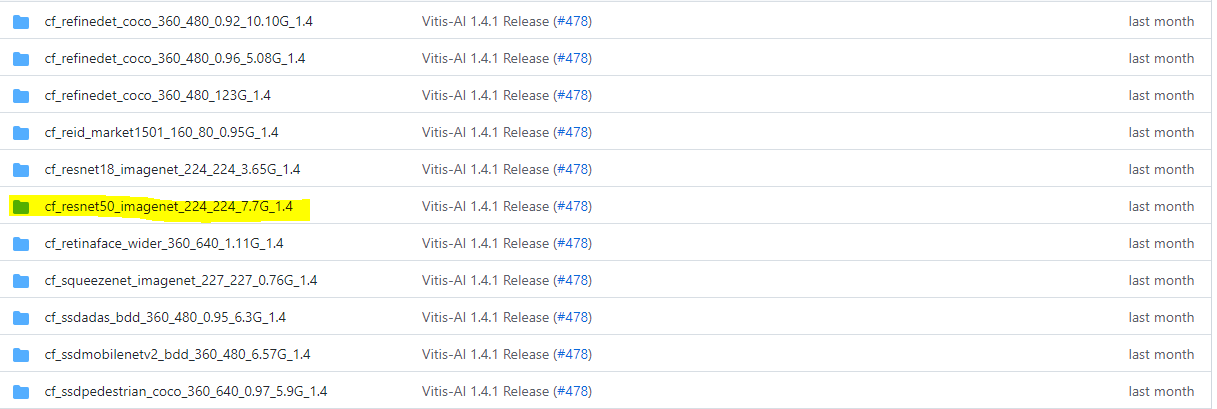
出典:GitHub Xilinx/Vitis-AI
https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo/model-list(参照 2021/12/27)
以下コマンドで、ダウンロードを行います。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI/work_so-one
$ url=https://www.xilinx.com/bin/public/openDownload?filename=cf_resnet50_imagenet_224_224_7.7G_1.4.zip
$ wget -O ${url##*=} $url
$ url=https://www.xilinx.com/bin/public/openDownload?filename=resnet50-zcu102_zcu104_kv260-r1.4.0.tar.gz
$ wget -O ${url##*=} $url・Tensorflow-v1
「tf_resnetv1_50_imagenet_224_224_6.97G_1.4」を用います。
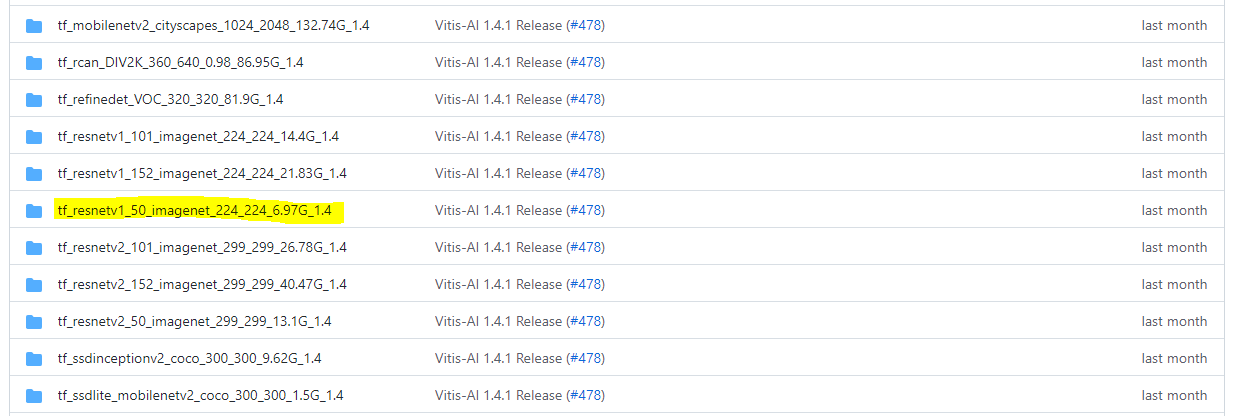
出典:GitHub Xilinx/Vitis-AI
https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo/model-list(参照 2021/12/27)
以下コマンドで、ダウンロードを行います。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI/work_so-one
$ url=https://www.xilinx.com/bin/public/openDownload?filename=tf_resnetv1_50_imagenet_224_224_6.97G_1.4.zip
$ wget -O ${url##*=} $url
$ url=https://www.xilinx.com/bin/public/openDownload?filename=resnet_v1_50_tf-zcu102_zcu104_kv260-r1.4.0.tar.gz
$ wget -O ${url##*=} $url・Tensorflow-v2
「tf2_resnet50_imagenet_224_224_7.76G_1.4」を用います。
出典:GitHub Xilinx/Vitis-AI
https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo/model-list(参照 2021/12/27)
以下コマンドで、ダウンロードを行います。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI/work_so-one
$ url=https://www.xilinx.com/bin/public/openDownload?filename=tf2_resnet50_imagenet_224_224_7.76G_1.4.zip
$ wget -O ${url##*=} $url
$ url=https://www.xilinx.com/bin/public/openDownload?filename=resnet50_tf2-zcu102_zcu104_kv260-r1.4.0.tar.gz
$ wget -O ${url##*=} $urlAIモデル解凍
「AIモデルダウンロード」でダウンロードしたAIモデルを解凍します。
以下コマンドで、Caffe, Tensorflow-v1, Tensorflow-v2一気に解凍していきます!
$ cd ~/Vitis/vitis_r1.4/Vitis-AI/work_so-one
$ unzip -q cf_resnet50_imagenet_224_224_7.7G_1.4.zip
$ unzip -q tf_resnetv1_50_imagenet_224_224_6.97G_1.4.zip
$ unzip -q tf2_resnet50_imagenet_224_224_7.76G_1.4.zip
$ tar zxf resnet50-zcu102_zcu104_kv260-r1.4.0.tar.gz
$ tar zxf resnet_v1_50_tf-zcu102_zcu104_kv260-r1.4.0.tar.gz
$ tar zxf resnet50_tf2-zcu102_zcu104_kv260-r1.4.0.tar.gz現時点で、work_so-oneディレクトリ構成が、以下のようになっていればOKです!
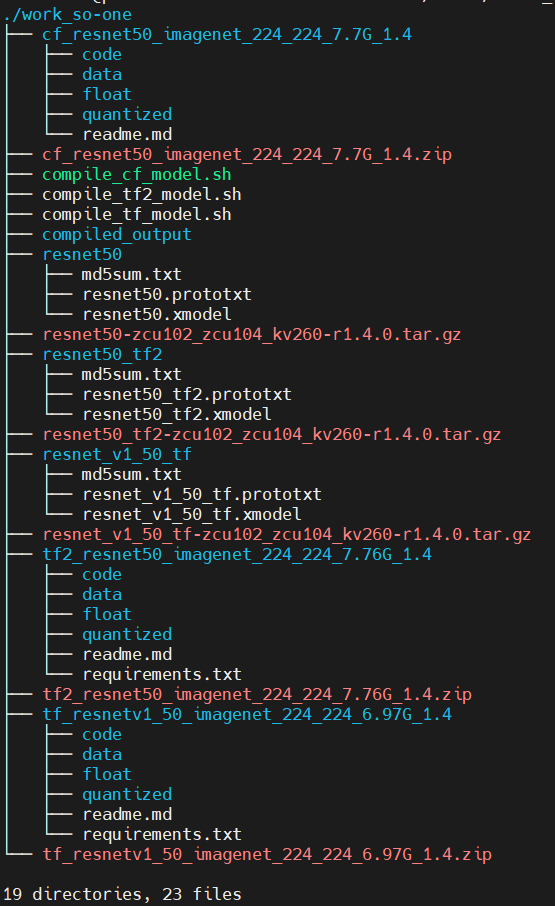
AIモデルコンパイル
「AIモデル変換スクリプト作成」「AIモデルダウンロード」「AIモデル解凍」で用意したファイルを用いて、コンパイルを行っていきます。
以下コマンドで、Vitis™ AI Docker環境を立ち上げます。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI
$ bash docker_run.sh xilinx/vitis-ai:1.4.916フレームワークごとにconda環境が異なるため、コンパイルにはご注意願います!
・caffe
$ conda activate vitis-ai-caffe
$ cd work_so-one
$ bash compile_cf_model.sh resnet50 cf_resnet50_imagenet_224_224_7.7G_1.4・Tensorflow-v1
$ conda activate vitis-ai-tensorflow
$ bash compile_tf_model.sh resnet_v1_50_tf tf_resnetv1_50_imagenet_224_224_6.97G_1.4・Tensorflow-v2
$ conda activate vitis-ai-tensorflow2
$ bash compile_tf2_model.sh resnet50_tf2 tf2_resnet50_imagenet_224_224_7.76G_1.4以上で、Vitis™ AI Docker環境はお役目終了です!
exitコマンドでDocker環境を終了させることをお忘れなく!
$ exitその他ファイル準備
So-One KIT実機動作にあたり、AIモデル以外に必要なファイルのダウンロード等を行います。
・prototxtの用意
Caffe, Tensorflow-v1, Tensorflow-v2どちらでも使用しますので、以下コマンドで コンパイル済みAIモデルと同じディレクトリにコピーします。
$ cd ~/Vitis/vitis_r1.4/work_so-one
$ cp -a resnet50/resnet50.prototxt compiled_output/resnet50/
$ cp -a resnet_v1_50_tf/resnet_v1_50_tf.prototxt compiled_output/resnet_v1_50_tf/
$ cp -a resnet50_tf2/resnet50_tf2.prototxt compiled_output/resnet50_tf2/・推論用サンプル画像ダウンロード
So-One KITで推論する際に用いるサンプル画像をダウンロードします。
以下コマンドで実行します。
$ url=https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_runtime_r1.4.0_image_video.tar.gz
$ wget -O ${url##*=} $url・デモデータ圧縮
Vitis™ AI GitHubにあるdemoディレクトリをSo-One KITへコピーするために圧縮します。
この中に今回用いる推論実行スクリプト(python)があります。
$ cd ~/Vitis/vitis_r1.4/Vitis-AI
$ tar zcf vitis-ai_demo_v1.4.tar.gz ./demo
$ mv vitis-ai_demo_v1.4.tar.gz ./work_so-oneSDイメージへファイル移動
「AIモデルコンパイル」「その他ファイル準備」で準備したファイルをSo-One KITのSDイメージ内に移動させます。
方法としては様々ありますが、今回は前回同様、SDイメージをHostPCへマウントして行います!
第2弾の記事 でも行っていますが、もう一度こちらでも紹介します。
・SDイメージのパーティション情報確認
パーティションの開始セクタを以下コマンドで確認します。
$ cd ~/Vitis/vitis_r1.4/VitisOutput
$ fdisk -l sd_card.img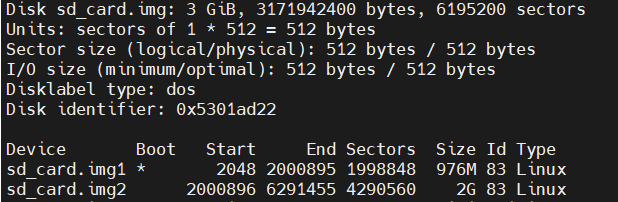
上記から、各パーティションの開始セクタが以下であることが分かりました。
- sd_card.img1:2048
- sd_card.img2:2000896
・SDイメージマウント
開始セクタが判明したので、早速HostPCへマウントしていきます!
マウント対象は、「sd_card.img2」です。こちらにLinuxのディレクトリ階層があります。
以下コマンドでマウントを行います。
$ sudo mkdir -p /mnt/sdcard2
$ sudo mount -o loop,offset=$[512*2000896] sd_card.img /mnt/sdcard2すると、/mnt/sdcard2ディレクトリ以下にSDイメージ内のディレクトリが閲覧可能になります!
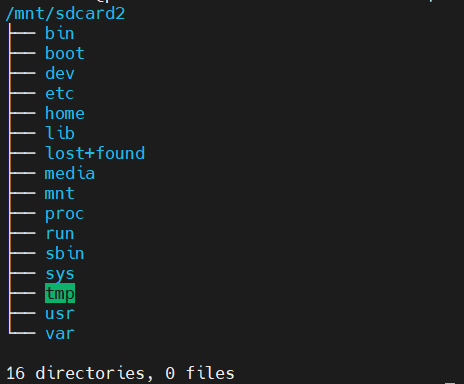
※ご注意!
開始セクタは、環境依存のため適宜しっかり確認し、必要であれば修正願います!!
・SDイメージへファイル移動
準備ができたので、早速該当するファイルを移動させます。
まずSDイメージ内に移動対象ファイルを格納するディレクトリを作成して移動します。
$ sudo mkdir -p /mnt/sdcard2/home/root/archive
$ cd ~/Vitis/vitis_r1.4/work_so-one
$ sudo cp -a vitis-ai-runtime-1.4.0.tar.gz vitis_ai_runtime_r1.4.0_image_video.tar.gz vitis-ai_demo_v1.4.tar.gz compiled_output /mnt/sdcard2/home/root/archive/これで移動完了です!最後にSDイメージをアンマウントして、書き込み用にイメージファイルを圧縮します。
$ sudo umount /mnt/sdcard2
$ cd ~/Vitis/vitis_r1.4/VitisOutput
$ gzip sd_card.imgSDカードへ、SDイメージ書き込み
こちらはコマンドやGUIソフト任意にご選択ください。
GUIソフトの場合は、Etcherをお勧めします!
書き込むイメージファイルは「~/Vitis/vitis_r1.4/VitisOutput」にあるsd_card.img.gzです。
これにて、HostPCでの作業は完了です!お疲れ様でしたー!
作業(評価ボード)
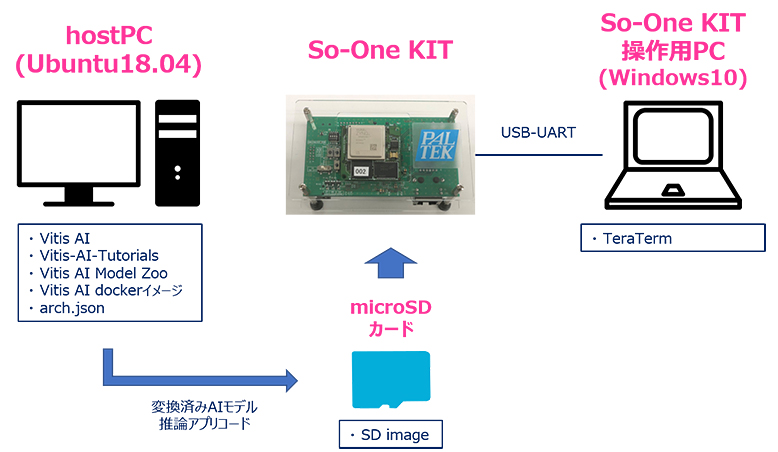
以下作業は、So-One KITを起動し、以下接続図のように、「So-One KIT, So-One KIT操作用PC, microSDカード」それぞれを接続した状態での内容になります。
起動方法の詳細については、手順書の「手順詳細:ボード作業ーOS起動」をご参照ください。
※接続図
最適化実行
以下コマンドで、So-One KITの最適化を行います。
# tar zxf /media/sd-mmcblk1p1/app/dpu_sw_optimize.tar.gz
# bash dpu_sw_optimize/zynqmp/zynqmp_dpu_optimize.shランタイムインストール
Vitis™ AIランタイムを解凍し、So-One KITへインストールします。
以下コマンドで解凍~インストールまで実行します。
# cd ~/archive
# tar zxf vitis-ai-runtime-1.4.0.tar.gz
# cd vitis-ai-runtime-1.4.0/2020.2/aarch64/centos/
# bash setup.shデモデータ展開
「その他ファイル準備 ・デモデータ圧縮」で用意したファイルを展開します。
# cd ~/archive
# tar zxf vitis-ai_demo_v1.4.tar.gz推論用サンプル画像展開
「その他ファイル準備 ・推論用サンプル画像ダウンロード」で用意したファイルを展開します。
展開先にご注意ください!
# cd ~/archive
# tar zxf vitis_ai_runtime_r1.4.0_image_video.tar.gz -C demo/VART/コンパイル済みAIモデル配置
最後に、コンパイル済みAIモデルを指定のディレクトリに移動させます。
以下コマンドで全てのAIモデルを移動させることができます!
# mkdir -p /usr/share/vitis_ai_library/models
# cp -a compiled_output/* /usr/share/vitis_ai_library/models/ファームウェアの設定
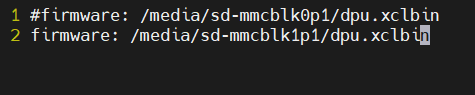
今回の動作検証にあたり、ファームウェアを定義しているファイルを編集します。
以下コマンドで、該当ファイルを開きます。
# vim /etc/vart.conf以下のように編集して、保存します!
推論実行用コード編集
今回はAIモデルを並列動作させるため、サンプルとして用意している推論コードをベースに編集していきます。
ベースとしている推論コードは、Pythonで記述された「resnet50.py」です。
出典:GitHub Xilinx/Vitis-AI
https://github.com/Xilinx/Vitis-AI/blob/master/demo/VART/resnet50_mt_py/resnet50.py (参照 2021/12/27)
まず、動作環境に問題ないか確認すべく、サンプルコードをそのまま実行します。
# cd ~/archive/demo/VART/resnet50_mt_py
# python3 resnet50.py 1 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel問題ないことを確認し、早速編集していきます。
編集箇所は大きく分けて2箇所です。
・1箇所目
main関数を追記します。
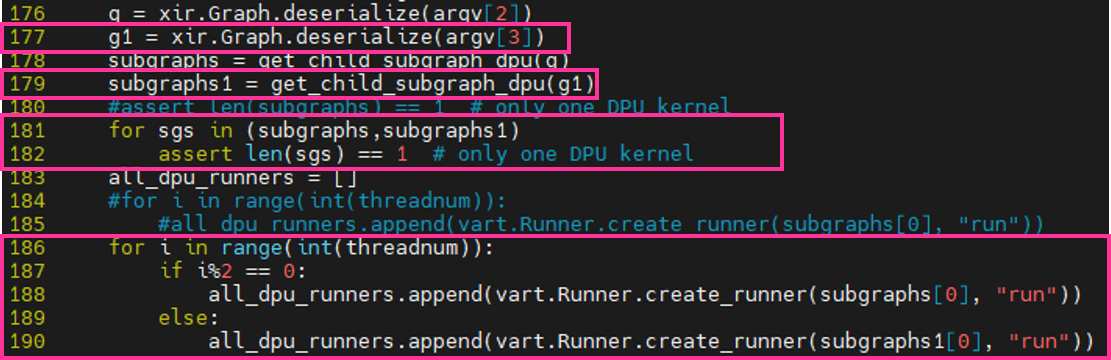
※画像クリックで大きな画像が表示されます。
・2箇所目
main関数実行箇所を追記します。

※画像クリックで大きな画像が表示されます。
これにて動作検証に必要な準備は完了です!
推論実行
準備も整ったので、早速実行していきます!
以下パターンで実行します。
- 同一のAIモデルを複数のDPUコアで並列動作させた場合
- 異なるAIモデルを複数のDPUコアで並列動作させた場合
・同一のAIモデルを複数のDPUコアで並列動作させた場合
-Caffe
# python3 resnet50.py 1 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel
# python3 resnet50.py 2 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel-Tensorflow-v1
# python3 resnet50.py 1 /usr/share/vitis_ai_library/models/resnet_v1_50_tf/resnet_v1_50_tf.xmodel
# python3 resnet50.py 2 /usr/share/vitis_ai_library/models/resnet_v1_50_tf/resnet_v1_50_tf.xmodel-Tensorflow-v2
# python3 resnet50.py 1 /usr/share/vitis_ai_library/models/resnet50_tf2/resnet50_tf2.xmodel
# python3 resnet50.py 2 /usr/share/vitis_ai_library/models/resnet50_tf2/resnet50_tf2.xmodel代表として、各々スレッド2の時の実行後の出力が以下のようになります。

※画像クリックで大きな画像が表示されます。
・異なるAIモデルを複数のDPUコアで並列動作させた場合
-Caffe / Tensorflow-v1
# python3 resnet50_dual_model.py 2 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel /usr/share/vitis_ai_library/models/resnet_v1_50_tf/resnet_v1_50_tf.xmodel-Caffe / Tensorflow-v2
# python3 resnet50_dual_model.py 2 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel /usr/share/vitis_ai_library/models/resnet50_tf2/resnet50_tf2.xmodel-Tensorflow-v1 / Tensorflow-v2
# python3 resnet50_dual_model.py 2 /usr/share/vitis_ai_library/models/resnet50_tf2/resnet50_tf2.xmodel /usr/share/vitis_ai_library/models/resnet_v1_50_tf/resnet_v1_50_tf.xmodel代表して、Tensorflow-v1 / Tensorflow-v2の時の実行後の出力が以下のようになります。

※画像クリックで大きな画像が表示されます。
これにて作業完了です!
お疲れ様でしたー!
最後に
最後までお読みいただきありがとうございました~
今回は今までと違う視点で、検証してみました。
AIモデルの並列動作については、少なからず需要はあるのではと思います。
1つのAIモデルのみでは処理に限界があるので、並列で動かした場合のメリットは大きいのではないでしょうか。
ただ、メリットデメリットでも記載しましたが、小さなFPGAの場合、処理速度がトレードオフの関係となりますね。
どこを妥協点とするか、ここがAI実装の肝になってくると個人的には考えております。
次回は何になるかまだ分かりませんが、引き続き連続投稿目指してかんばっていきたいと思います!
それではまた!TEPPE-AIでした~



















