無償化したAIモデル最適化ツール「Vitis™ AI Optimizer」を試してみた(検証編)


-
皆さまこんにちは!TEPPE-AIです!
今回ご紹介するものは
『無償化したAIモデル最適化ツール
「Vitis™ AI Optimizer」を試してみた(検証編)』 です。
AI Optimizerを適用したAIモデルをKria™ KV260上(以降、KV260)へ実装し、性能を確認していきたいと思います。
無償化したAIモデル最適化ツール「Vitis™ AI Optimizer」を試してみた(準備編) もあわせてご確認ください。
是非最後までお付き合いいただけると嬉しいです。
それでは参りましょう!
目次
作業概要
今回は、Vitis™ AI Tutorial(以降、Tutorial)を用いて作業を進めていきます。
図1. Vitis™ AI Tutorial(TensorFlow2 Vitis AI Optimizer)
作業の流れはTutorialに沿い、以下の手順で実施していきます。
「①環境構築」については 準備編 をご参照ください!
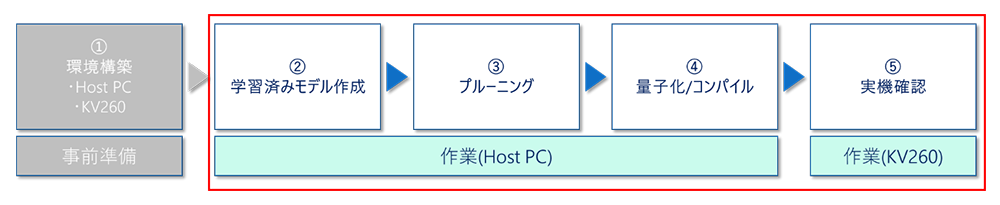
図2. 作業概要
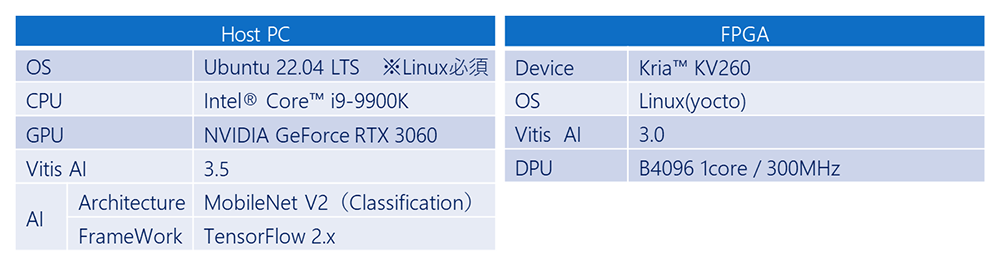
用いる環境は、以下の通りです。
Tutorialに従いAIモデル変換を行うHost PCでは、Vitis AIは3.5を、KV260のデザインはVitis AI 3.0版のサンプルデザインを用います。
表1 使用デバイス環境
以下の内容はTutorialで言及している箇所です。Vitis AI 3.5のFPGAデザインを必須で用意する必要はないみたいです。
なぜなのか、理由を探っていきます。
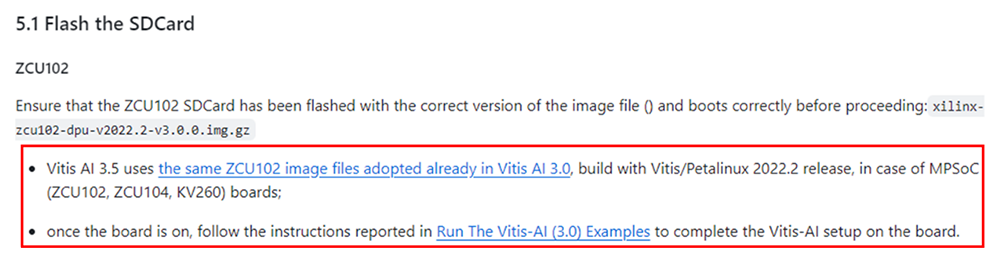
図3. Tutorial FPGAデザイン使用について
Vitis AI GitHubにある ドキュメント を参照してみると、以下のような記述がありました。
- Vitis AI 3.5はZynq™ MPSoC UltraScale+™をサポートしているが、IP(DPU)は更新していない
- Vitis AI 3.5を活用したい場合は、Vitis AI 3.0の環境を用いるかVitis AI 3.5のRuntime,Libraryを用いて、ターゲットボード向けにデザインを構築

図4. Vitis AI GitHubドキュメント
出典: Overview — Vitis™ AI 3.5 documentation
Vitis AI 3.5で変換したAIモデルがVitis AI 3.0のデザイン上で動作するのかについても、確認していきたいと思います。
ご参考までに、以下の内容はVitis AIのバージョンに対するIPやツールバージョンの 対応表 です。
記述の通り、3.5と3.0ではDPUは同じバージョン(4.1)になっています。
DPU自体にアップデートがないため、問題なく動作するのでは?と予想しています。
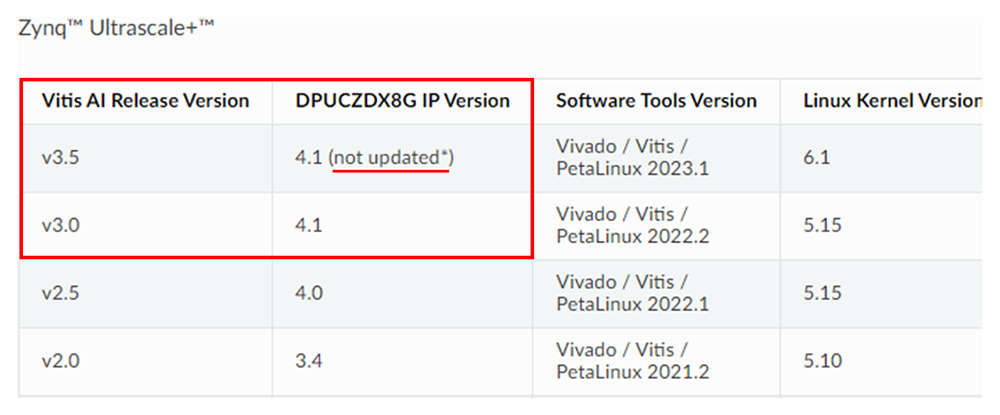
図5. IPとツールの対応表
出典: IP and Tool Version Compatibility — Vitis™ AI 3.5 documentation
実際に本当に動作したのかについて試してみた結果を以降に記載していますので、是非最後までお付き合いいただけると嬉しいです。Tutorialに沿って作業を行っていますので、Tutorialの ページと照らし合わせながら本ブログをご参照ください。
学習済みAIモデル作成
Tutorialに沿って、学習済みAIモデルを作成していきます。
その前に、事前準備をいくつか実施してきます。
- ※
- 事前準備は、「1.2 Working Directory」、「2 Prerequistes」に沿っています。
作業ディレクトリの確認
作業ディレクトリの作成及びTutorialのダウンロードについては、 準備編 の
「デバイス環境構築>hostPC>Vitis AI Tutorialダウンロード」をご参照ください!
AI Optimizerを試せるTutorialは2つ存在し、今回は「dog-vs-cats_mobilenetv2」を試します。
図6. AI Optimizer Tutorialの種類
加えて以下のようにライセンスに関する準備(AI Optimizer License)と記載がありましたが、こちらは特に何も実施しなくても問題なかったです。もし問題があったらアップデートします。
ここでは作業ディレクトリがあること、Tutorialがダウンロードできていることを確認できればOKです。
もし何か問題があったらアップデートします。
図7. License設定を記載しているところ
学習用データセットのダウンロード
続いて学習用のデータセットの準備を行います。
Tutorialの名前にもある通り、「dogs-vs-cats」というKaggleで公開されているデータセットを用います。
Kaggleとは、データサイエンス及び機械学習のコミュニティで、コンペティションやデータの共有などさまざまなことが実施できるプラットフォームになります。
「kaggle dogs vs cats」とwebブラウザで検索し、“Dogs vs. Cats | Kaggle”をクリックします。
図8. Kaggle dog vs cats 検索結果
ダウンロードする際、Kaggleのアカウントを作成する必要がありますので、ご注意ください。
作成後、以下のページが開けるかと思います。ハイライトをしている“Data”をクリックします。
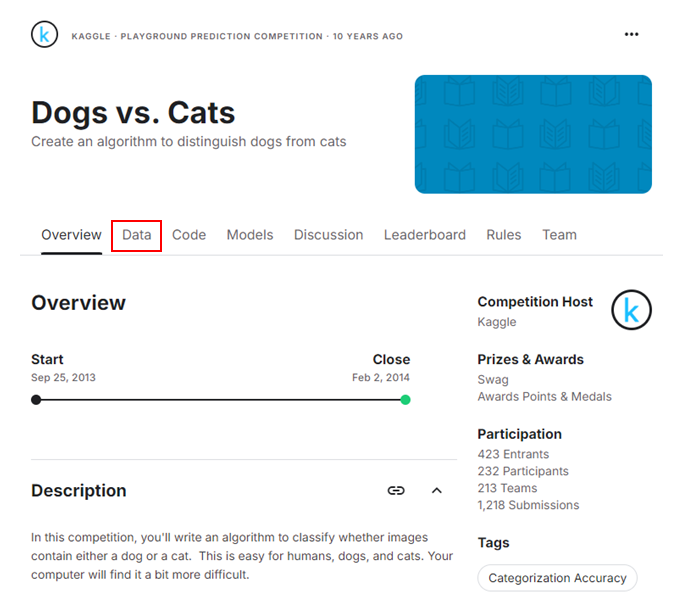
図9. Kaggle Dogs vs. Catsのページ
画面切り替わり後、下までスクロールし“Download All”をクリックします。
すると、dog-vs-cats.zipがダウンロードされます。
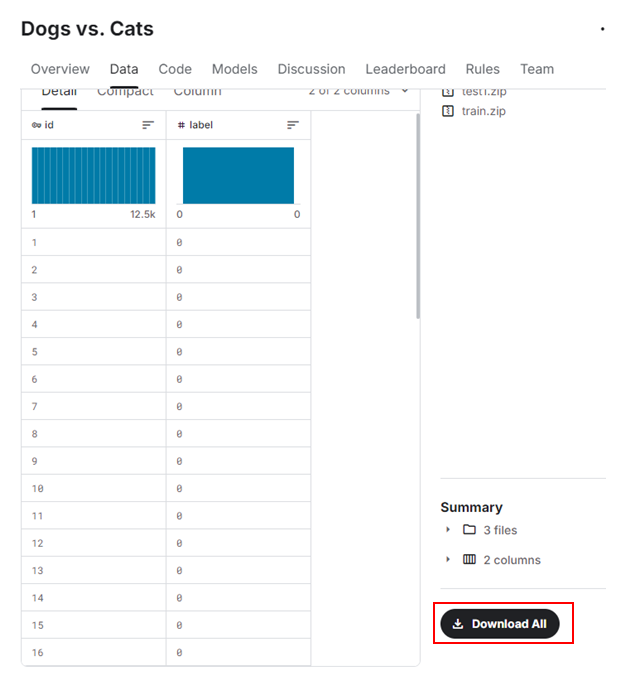
図10. ダウンロード元の場所
TF2-Vitis-AI-Optimizer/files/dogs-vs-cats_mobilenetv2ディレクトリにダウンロードすれば準備OKです。解凍は不要です。
Vitis AI Docker Imageの準備
こちらは、 準備編 の「デバイス環境構築>hostPC>Vitis AI dockerビルド>GPUの場合」をご参照ください。

-
悩んでいるお話・・・
原因は不明ですが、Ubuntu22.04上でビルドを行うとエラーとなる現象が起きています。。
去年末は問題なくできていたのですが、今年に入ってからその現象が起きていますorz
Ubuntu18.04のマシンでは問題なくビルドはできます。
Vitis AIの GitHub でも問い合わせているのですが、未だ解決せず・・・
もし同じ現象の方、解決した方などいらっしゃいましたら、ご連絡いただけると嬉しいです。
これにて準備が完了しましたので、いよいよ学習済みAIモデルの作成に移っていきます。
Vitis AI Dockerを起動させます。
$ cd ~/Vitis-AI/vitis_r3.5/Vitis-AI
$ ./docker_run.sh xilinx/vitis-ai-tensorflow2-gpu:3.5.0.001-b2b227921起動完了後は以下のように表示されます。
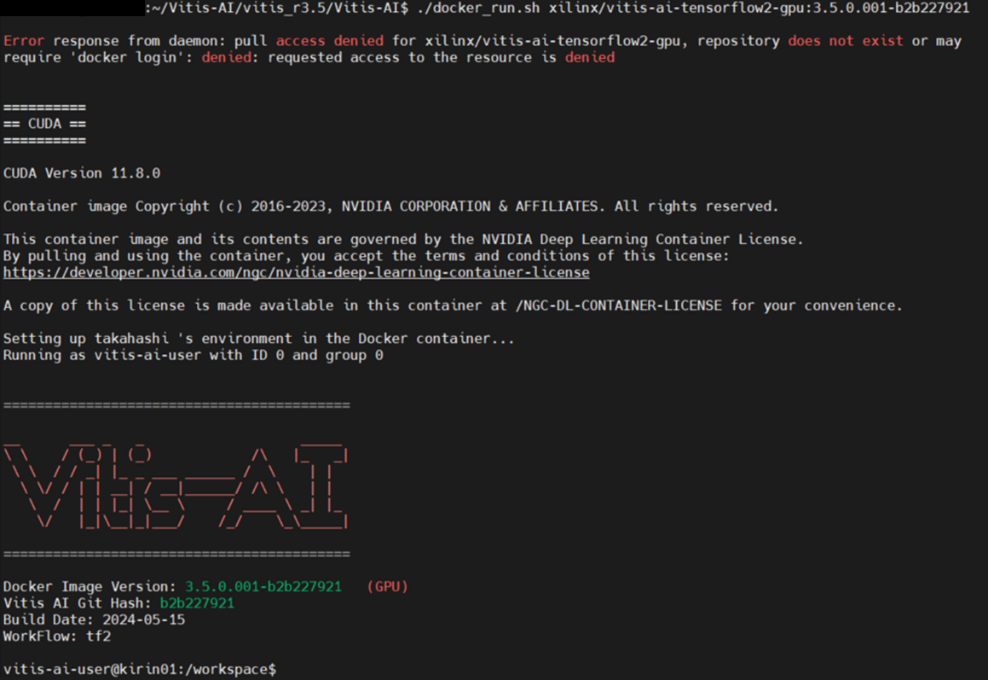
図11. Vitis AI Docker(TF2/GPU)起動画面
起動確認後、Tutorialを参照しsetup_env.shを実行します。
$ cd Vitis-AI-Tutorial/Vitis-AI-Tutorials/Tutorials/TF2-Vitis-AI-Optimizer/files/scripts/
$ sh setup_env.sh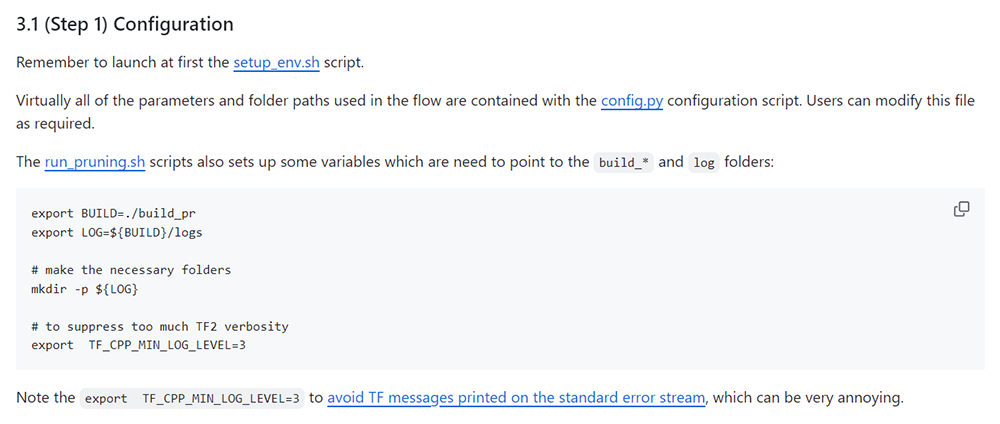
図12. setup_env.sh
その後、以下設定コマンドを実行します。
$ cd Vitis-AI-Tutorial/Vitis-AI-Tutorials/Tutorials/TF2-Vitis-AI-Optimizer/files/ dogs-vs-cats_mobilenetv2
$ export BUILD=./build_pr
$ export LOG=${BUILD}/logs
$ mkdir -p ${LOG}
$ export TF_CPP_MIN_LOG_LEVEL=3完了後、dog-vs-cats_mobilenetv2ディレクトリが以下の構成になっていればOKです。
図13. dogs-vs-cats_mobilenetv2ディレクトリ
その後、学習用データをTFRecord形式に変換します。
変換することで、TensorFlow内でデータを扱う際に、変換前のデータの形式と比較し、高速かつディスク領域の節約が可能になります。
変換するスクリプトが用意されているので、そちらを用います。
$ python -u images_to_tfrec.py 2>&1 | tee ${LOG}/tfrec.log完了後、以下のように出力され、dataというディレクトリが新たに生成されます。
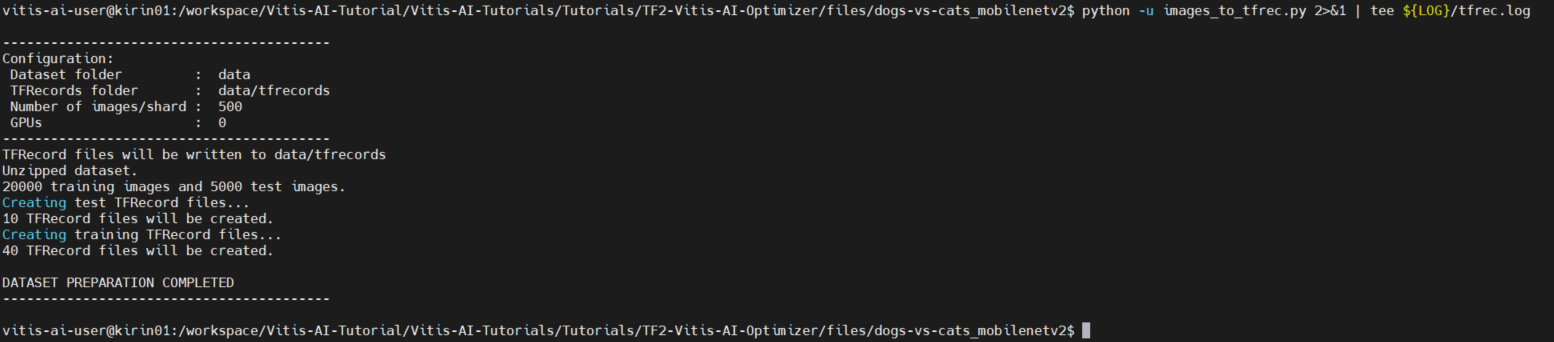
図14. TFRecord変換実行時の標準出力
dataディレクトリはこんな感じ。
図15. dataディレクトリ一覧(一部抜粋)
そしていよいよ学習を実行していきます。
以下コマンドで学習済みAIモデルを作成します。
$ python -u implement.py --mode train --build_dir ${BUILD} 2>&1 | tee ${LOG}/train.logこのまま実行すると85回学習が実行されます。学習に関するパラメータはconfig>config.pyに記載されているので、epoch数やbatchsizeを変更したい場合はご参照ください。
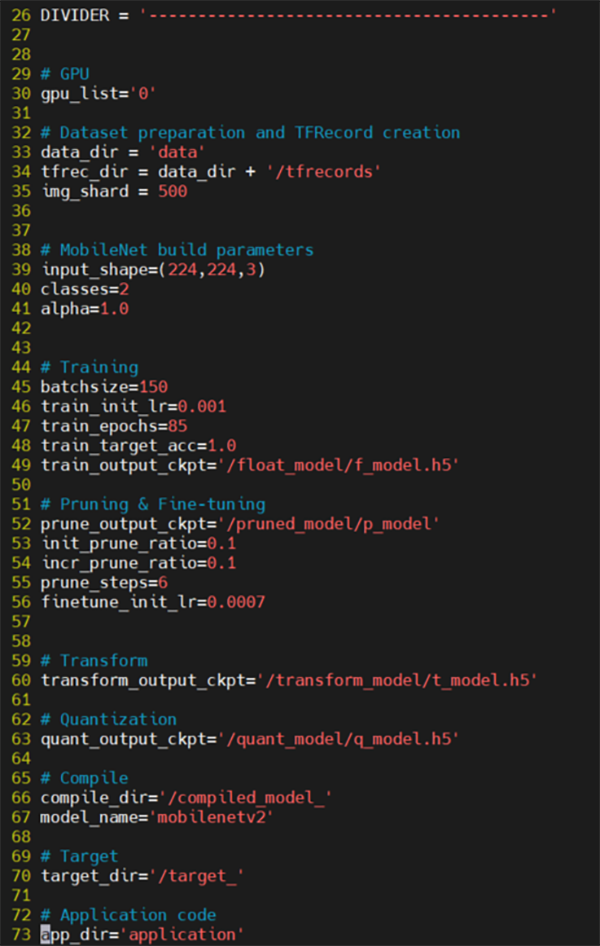
図16. config.py
config.pyでは、学習以外にもtutorial実行に必要なパラメータが記載されています。項目は、各工程にて触れていきます。
以下のように実行され、85回の学習が完了後、f_model.h5として保存され、学習にかかった時間とアーキテクチャが表示されます。当方環境では約1時間かかりました。
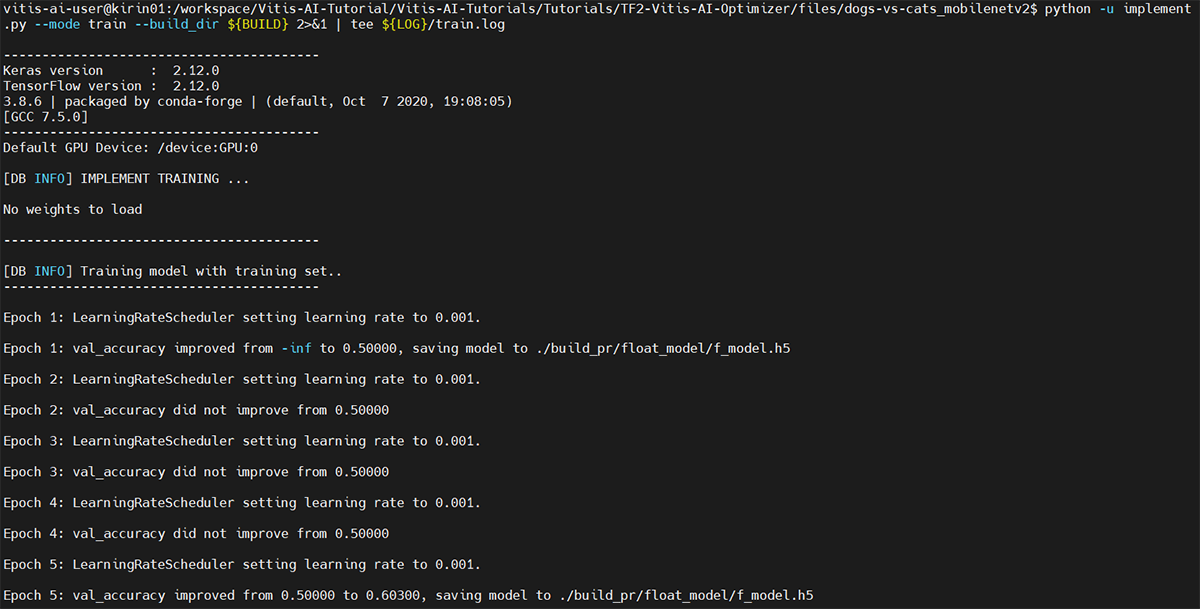
図17. 学習実行直後の出力画面
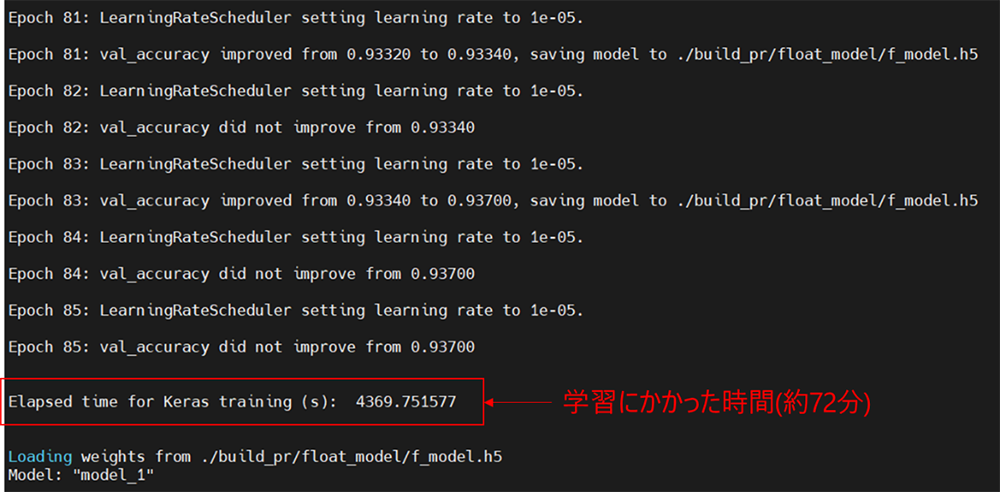
図18. 学習完了後の出力画面
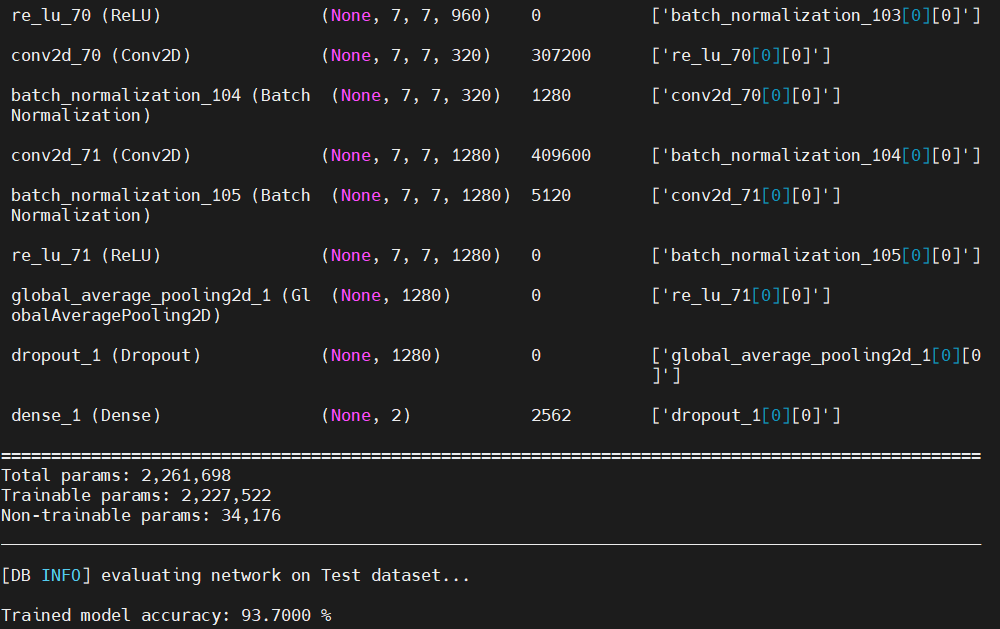
図19. AIモデルアーキテクチャ出力画面(最後部)
学習完了後、build_prディレクトリに以下が格納されます。
| float_model/f_model.h5 | 学習済みAIモデル |
|---|---|
| logs | 各種ログデータ |
| trained_accuracy | 学習済みAIモデルのvalidation性能結果(accuracy) |
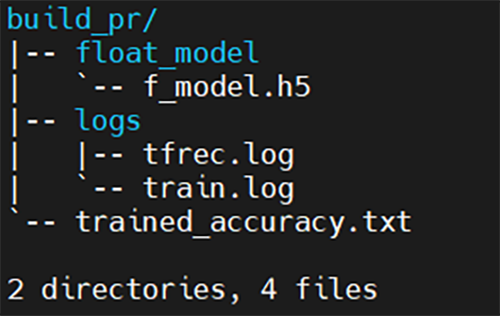
図20. build_prディレクトリ
これにて学習済みAIモデル作成は完了です。
プルーニング(AI Optimizer)
AI Optimizer及びプルーニングの概要については、前回の 準備編 の「プルーニングとは」をご参照ください!
Tutorialでは反復プルーニングを採用しています。
今回は、以下3パターンで削減率を定義し、推論精度の比較を行っていきます。
- 60%
- 70%
- 80%
削減率を変更するためには、config>config.pyの“Pruning & Fine-tuning”を編集します。
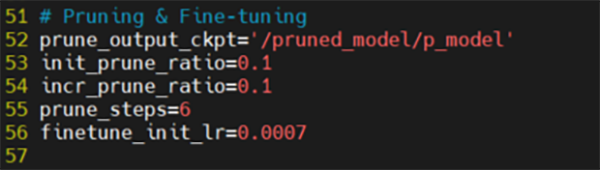
図21. config.py “Pruning & Fine-tuning”
以下 Tutorialの記述にある通り、60%を実現するには、prune_stepsを6にし、prune_ratioを0.1にするということになります。
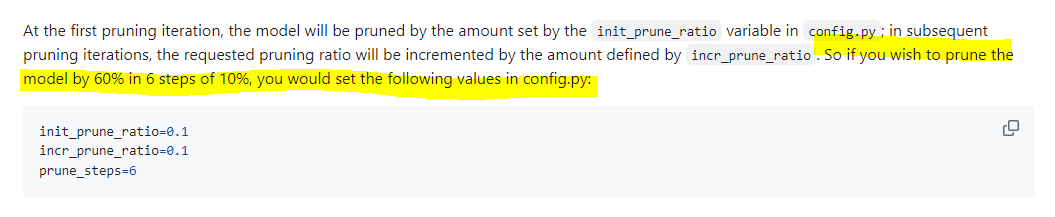
図22. Tutorial 削減率定義方法について
-
ちょっと外れた話・・・
試してはいないですが、60%を実現する場合はその他にprune_ratioを0.1ではなく0.2に変え
prune_stepsを3にする、なんて方法もあるでしょう。
個人的な感覚になりますが、prune_stepsの回数が一定数あるほうが精度の担保はされやすいのではと思っています。
一概には言えませんが、AIモデルによって適している回数があるかもです!
前述の通り、今回はprune_stepsを6,7,8の3パターンで試してみますので、以下のようにそれぞれ実施した際のconfig.pyを設定していきます。
・prune_steps = 6 ※削減率60%
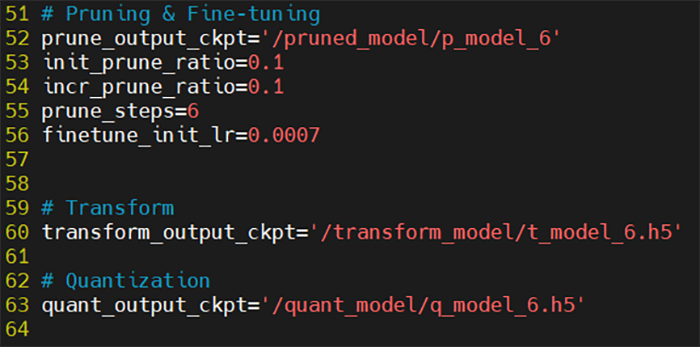
図23. 削減率60%のconfig.py
・prune_steps = 7 ※削減率70%
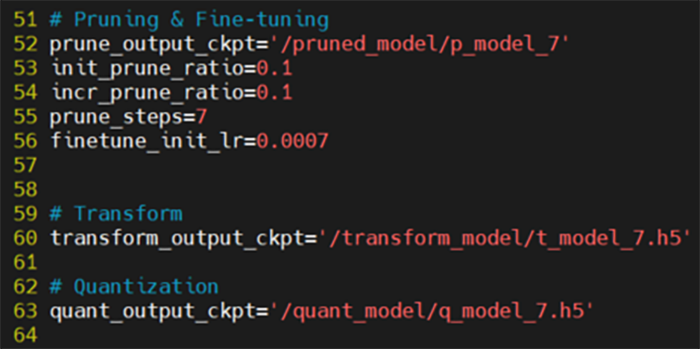
図24. 削減率70%のconfig.py
・prune_steps = 8 ※削減率80%
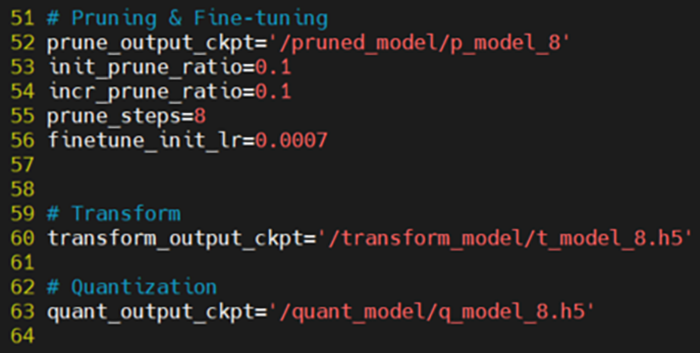
図25. 削減率80%のconfig.py
本ブログでは、削減率60%を実行した際の実行結果を記載しています。
最後に、各削減率での実行結果を比較していますので、ご安心ください!!
反復プルーニングは「分析」→「プルーニング」→「微調整(以降、ファインチューニング)」で実施され、設定した回数分(prune_step)、プルーニングとファインチューニングをループで実施していきます。
以下が実行アプリケーション(implement.py)でAI Optimizerによるプルーニングを実行している箇所です。
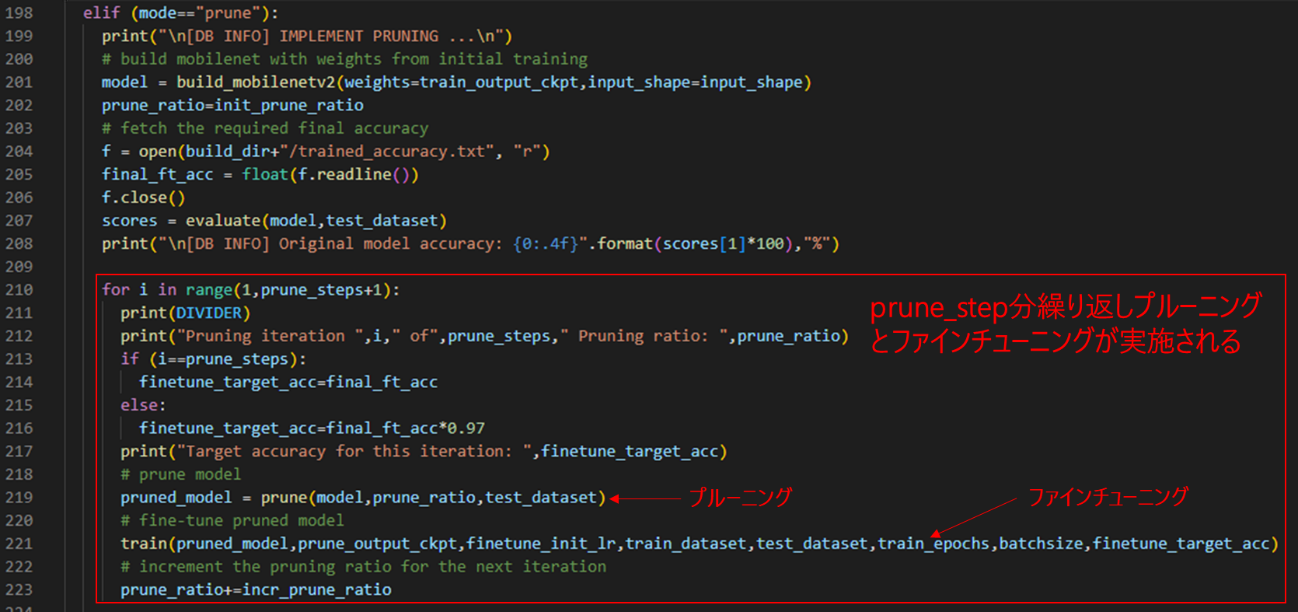
図26. implement.py
Forループで設定したprune_stepの回数分プルーニングとファインチューニングを実行しているのが分かります。
以下実行コマンドでプルーニングを実施します。
$ python -u implement.py --mode prune --build_dir ${BUILD} 2>&1 | tee ${LOG}/prune.log完了するまで少々時間がかかります。削減率60%の場合、合計で90分ほどかかりました。
理由としてファインチューニングを都度実施しており、かつプルーニング適用前の学習済みAIモデルの認識精度と近い値になるまでファインチューニングを繰り返しているためではないかと推測しています。
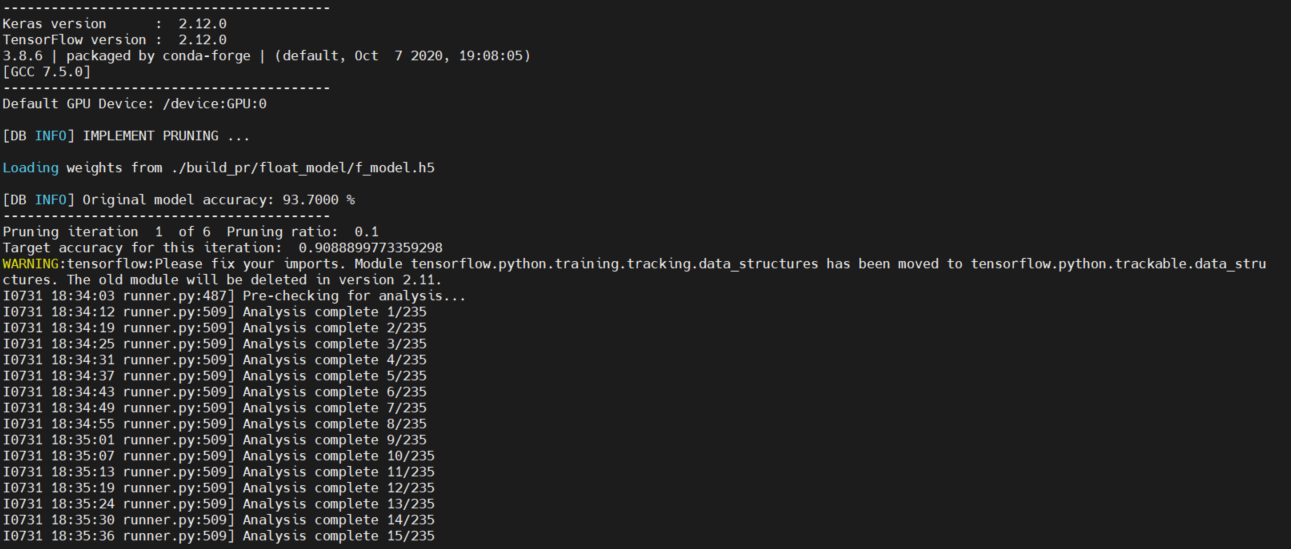
図27. 分析をしている様子
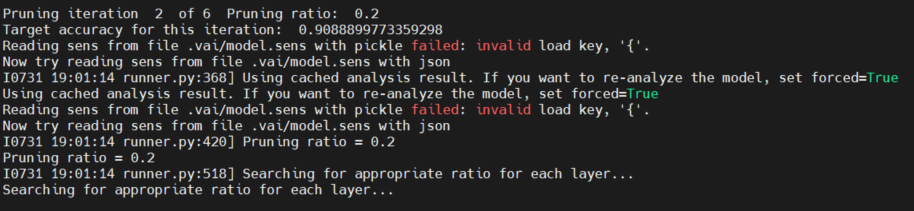
図28. プルーニングを実施している様子
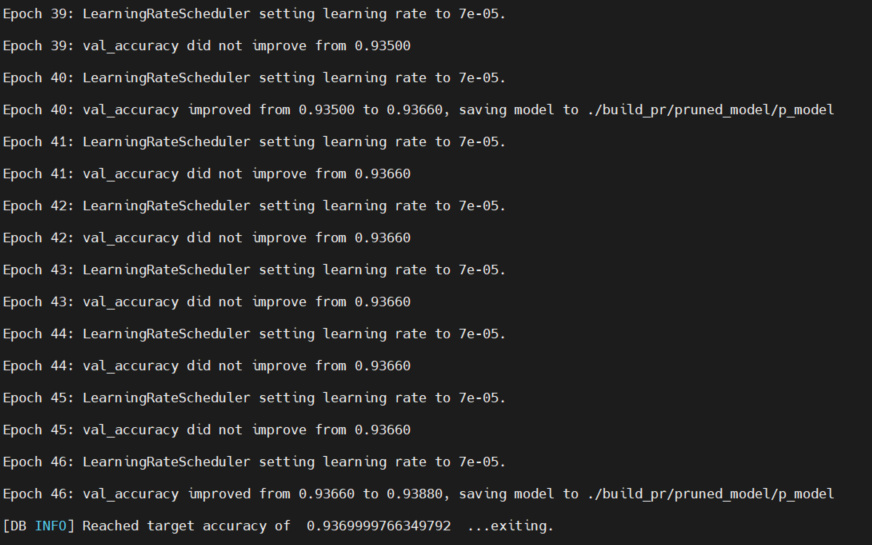
図29. ファインチューニングを実施している様子
プルーニングが完了すると、build_pr内にpruned_modelディレクトリが生成されcheckpointファイルが格納されます。
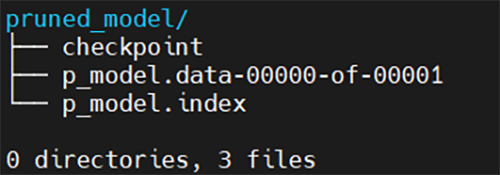
図30. pruned_modelディレクトリ
最後にプルーニングしたモデルを変換します。
checkpointとして保存されているAIモデルは、プルーニングによって削除された重みは「0」の値を持っています。行う変換は「0」となっている重みを完全に除去するのが狙いです。
以下コマンドで変換を実施します。
$ python -u implement.py --mode transform --build_dir ${BUILD} 2>&1 | tee ${LOG}/transform.log
図31. 変換実行後の標準出力
実行後、build_prディレクトリにtransform_modelディレクトリが生成され、H5ファイルが格納されます。
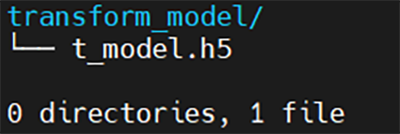
図32. transform_modelディレクトリ
これにてプルーニング完了です。
量子化・コンパイル
続いて、KV260上で動作できるように、量子化とコンパイルを実施していきます。
実行用のスクリプトとコマンドが既に用意済みなので、サクッと実行していきます。
量子化
以下コマンドで実行します。
$ python -u implement.py --mode quantize --build_dir ${BUILD} 2>&1 | tee ${LOG}/quantize.logTutorialでは こちらをご参照ください。
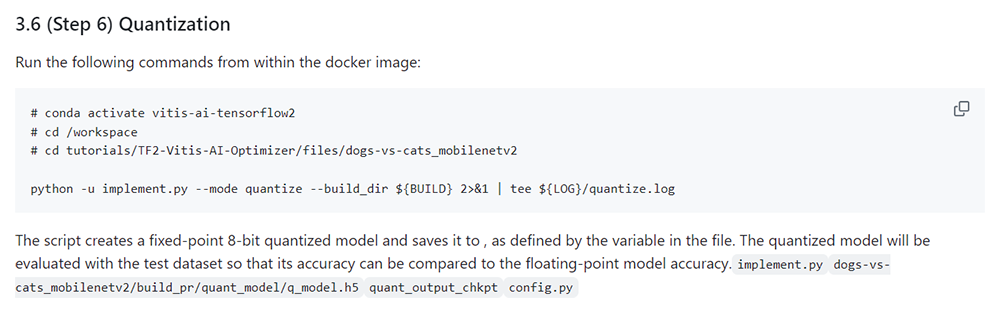
図33. Tutorial 量子化実行
実行後以下のような画面が出力され、build_prディレクトリにquant_modelディレクトリが生成され、量子化済みAIモデル(.h5)が格納されます。
図34. quant_modelディレクトリ
これにて量子化完了です。
コンパイル
以下コマンドで実行します。
$ python -u implement.py --mode compile --build_dir ${BUILD} --target kv260 2>&1 | tee ${LOG}/compile_kv260.logTutorialでは こちらをご参照ください。
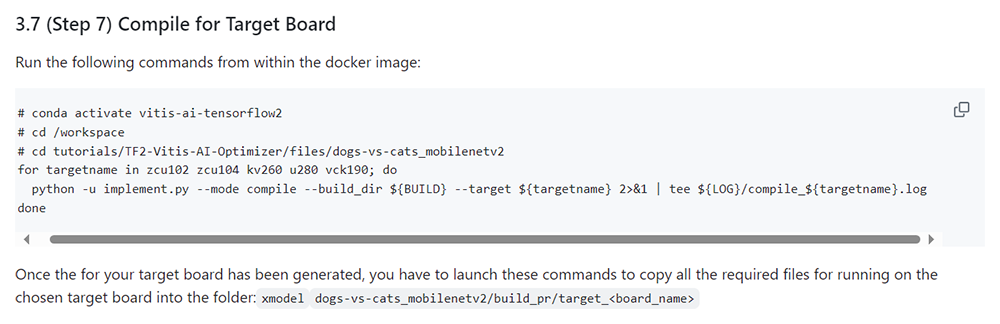
図35. Tutorial コンパイル実行
本来ですと、コンパイル時に用いるDPU情報を記述しているarch.jsonを用意する必要がありますが、KV260の場合、Vitis AI Docker上に保存されているサンプルのarch.jsonで問題なかったです。
- ※
- 前述した通り、Zynq™ MPSoC UltraScale+™のDPUの場合、Vitis AI 3.0と3.5で同じverのDPUであること、サンプルデザイン上に搭載されている種類がB4096であったことが要因です。
以下のように、Vitis AI Docker起動後
「/opt/vitis_ai/compiler/arch」ディレクトリに各デバイス向けのarch.jsonが格納されています。
今回はその中にある、DPUCZDX8G>KV260ディレクトリ内のarch.jsonを用いました。
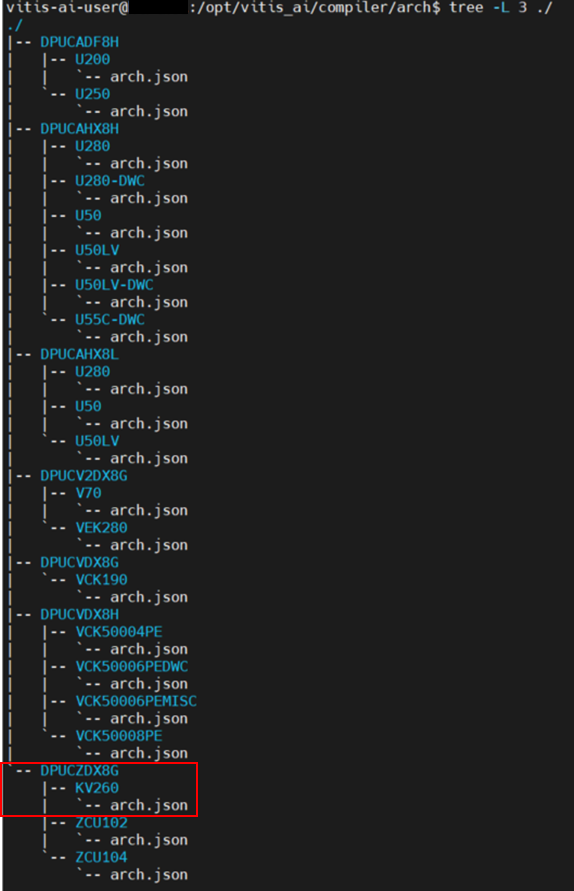
図36. arch.json格納ディレクトリ
実行後、build_prディレクトリにcompiled_model_kv260ディレクトリが生成され、コンパイル済みAIモデル(xmodelファイル)が格納されます。
図37. compiled_model_kv260ディレクトリ
これにてコンパイル完了です。
実機確認
AIモデルの変換も完了しましたので、いよいよ実機確認をしていきます!
以下流れで実行していきます。
- 実機確認に必要なファイルの準備
- KV260起動
- Host PCからKV260へ必要ファイル転送
- KV260実機確認
実機確認に必要なファイルの準備
Tutorialに、実機確認に必要なファイルを一括にディレクトリへ格納させるスクリプトが用意されているので、そちらを活用します。
以下ハイライト箇所を参照し、コマンドを実行します。
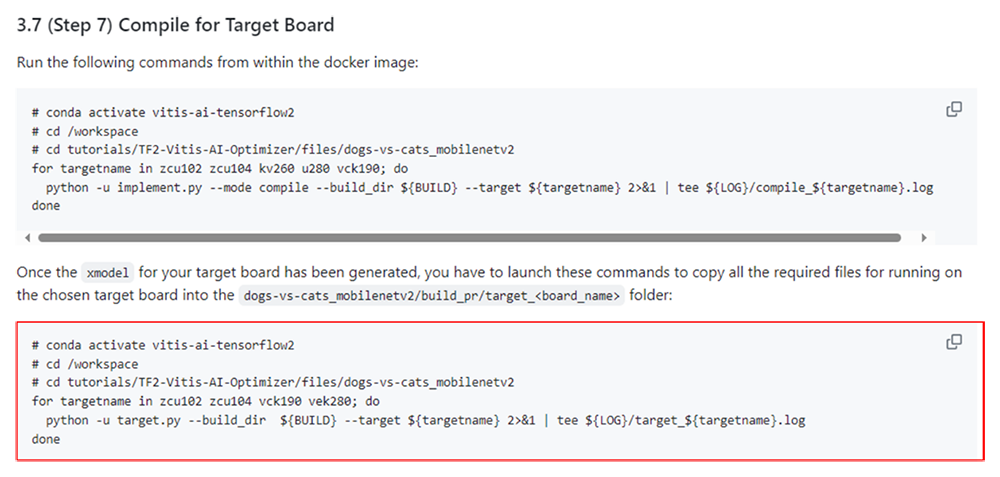
図38. 必要なファイル一括化コマンド
Vitis AI Dockerは起動したままでOKです。
$ python -u target.py --build_dir ${BUILD} --target kv260 2>&1 | tee ${LOG}/target_kv260.log実行後、build_prディレクトリにtarget_kv260というディレクトリが生成されます。
以下のように実機確認に必要なアプリケーション等が格納されています。
| app_mt.py | 推論アプリケーション |
|---|---|
| images | 推論用静止画像(5000枚) |
| mobilenetv2_pruned-0.6.xmodel | 変換済みAIモデル |
| run_all_mobilenetv2_target.sh | 推論スクリプト ※これは使いませんでした。 |
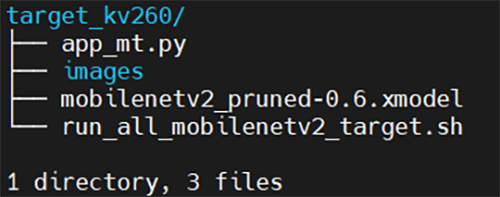
図39. target_kv260ディレクトリ一覧
これにて作業完了です。
KV260起動
準備編で用意したサンプルデザイン書き込み済みmicroSD(デバイス環境構築>評価ボード)をKV260へ挿入し起動します。
起動後、以下のように表示され、Linuxが立ち上がり、rootユーザーとして自動ログインされます。
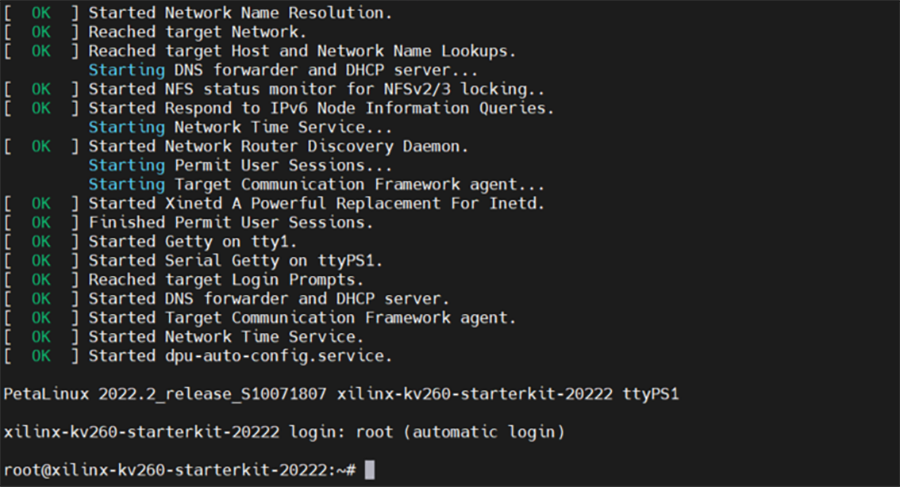
図40. KV260起動画面
Host PCからKV260へ必要ファイル転送
さまざまな手法がありますので、慣れている手法でファイルの転送を実行してみてください。
Tutorialでは、ネットワーク経由でscpコマンドを用いた転送方法が記述されています。
私も同様の手順で実行しました。
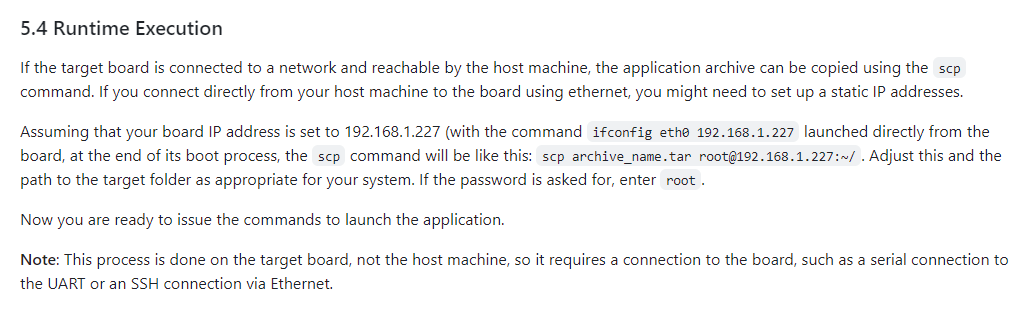
図41. ネットワーク経由によるファイル転送方法
転送後、KV260で起動しているLinuxの任意のディレクトリに保存します。
私は、rootのhomeディレクトリに保存しました。
図42. root/homeディレクトリ
KV260実機確認
準備が整いましたので、実行していきます!
以下コマンドで推論アプリケーションを実行します。
# python3 app_mt.py -t 1 -m mobilenetv2_pruned-0.6.xmodel実行後、以下のように推論結果が表示されます。
| Throughout | 処理速度(FPS)→ Total frames / time |
|---|---|
| Total frames | 処理した静止画像の枚数 |
| time | 処理速度(seconds) |
| Correct | 正しく認識できた枚数 |
| Wrong | 間違って認識した枚数 |
| Accuracy | 正解率 → Correct / Total frames |
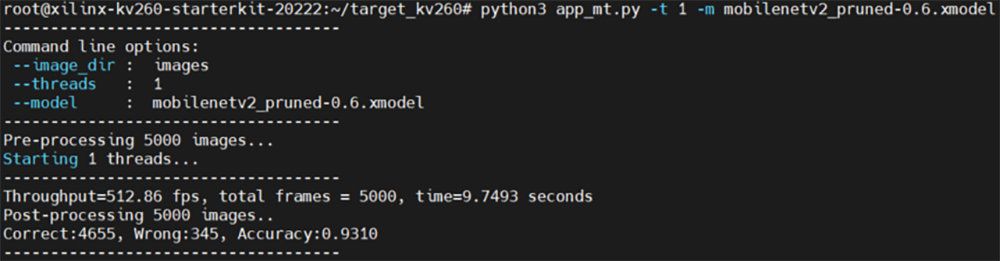
図43. KV260推論実行結果の標準出力画面
プルーニング未適用、削減率60%、70%、80%で実行結果を比較してみました!
表2 各削減率での性能比較
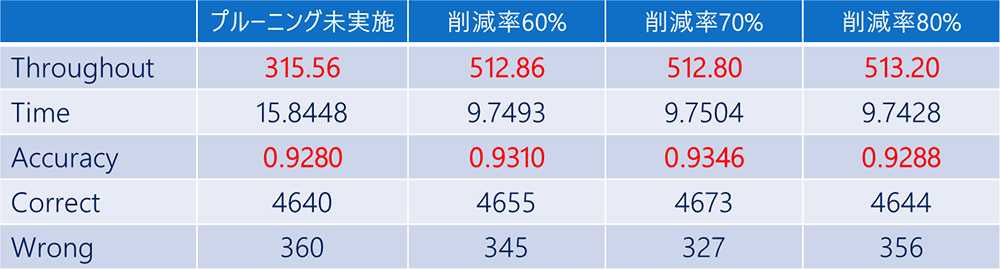
プルーニング適用の有無でここまで処理速度が変わるのですね・・・
精度についても適用有無でそこまで差分がないように見受けられます。
- ※
- 適用した場合が若干向上しているのは、おそらく外れ値なのではと思います。
以下に、削減率60%以外の各項目での出力結果を示します!
・プルーニング未適用
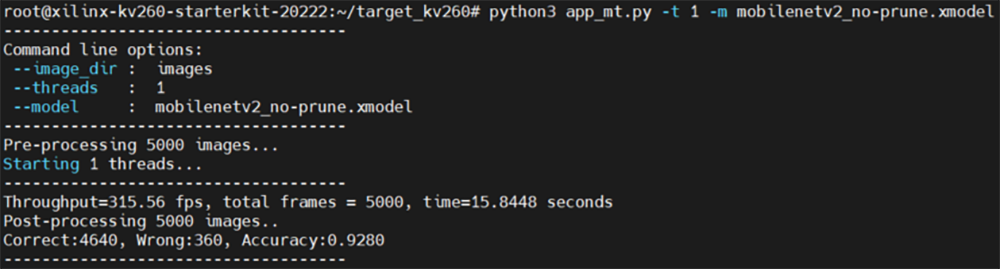
図44. プルーニング未適用モデルの推論結果
・削減率70%の場合
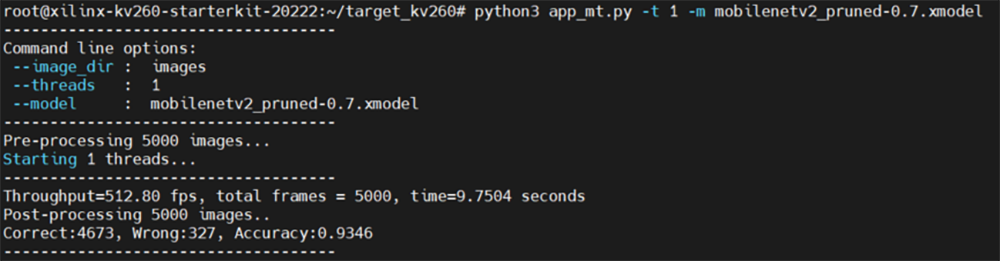
図45. 削減率70%モデルの推論結果
・削減率80%の場合
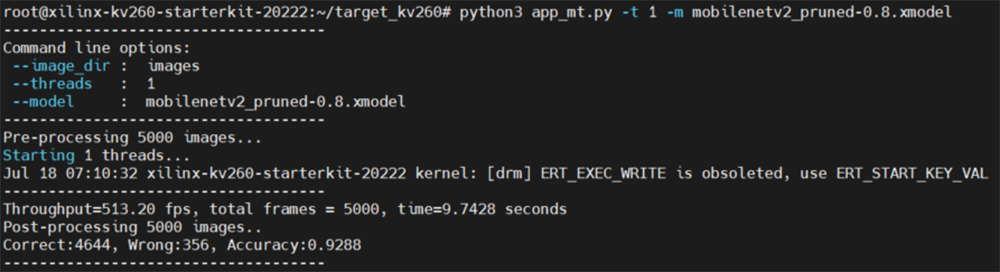
図46. 削減率80%モデルの推論結果
おわりに
最後まで閲覧いただき、ありがとうございました!
Tutorialを活用することで、AI Optimizerを簡単に扱うことができるのはいいですよね。
Tutorialにも記述されていたのですが、削減率の適正値はケースバイケースのようでいろいろと試行錯誤して見つける必要があります。

図47. 削減率の設定について
今回は画像分類でしたが、物体検出のモデルでも試してみたいです!
それではまた!TEPPE-AIでした~



















