ついに!オープンソースのモデルをVitis™ AIを使い評価キット ZCU102上で動かしてみた

皆さまこんにちは!TEPPE-AIです!
まだまだコロナは収まりませんね・・
今まで当たり前であったことが羨ましく思う、今日この頃です(笑)
当たり前の日常が一刻もはやく復活することを願って、日々過ごしていきたいと思います!

-
さぁ早速本題に入りますが、今回のタイトルはこちら!
ついに!オープンソースのモデルをVitis™ AIを使い評価キット ZCU102上で動かしてみた
「ん!? Vitis AIってTensorFlow とCaffe対応でしょ?」
と思った方がいらっしゃったかもしれません。
なんと、Kerasベースでもいけちゃうのです!
※深層学習エンジニア初心者の方にとっては嬉しいですよねー!
そしてなんといっても今回の注目いただきたい点は、オープンソースモデルの実装です! ようやく。。。(泣)
ザイリンクス社が用意したサンプルしか動かせていなかったのですが今回は、GitHubに掲載されているオープンソースのVGG-16を、cifar-10データセットで学習させ、ZCU102上で動作できるか試してみました。
(参照はこちら ⇒ https://github.com/geifmany/cifar-vgg)
結果、無事動かすことに成功しましたので、紹介させていただきます!!
実運用に向けた、確実なステップアップになるかと思いますので、是非最後まで読んでいただけると嬉しいです!
それでは参りましょう!
目次
Vitis-AI- Tutorialsについて
Vitis-AI-Tutorialは、Vitis AIを使用して様々なAIタスクの実行例を記載しているリポジトリです。
種類は様々で、アプリケーションに注目したものやフレームワークに注目したものなど多岐に渡ります。
また、実行結果だけでなく手順なども記載されているので、試しやすいところも大きな利点となっています。
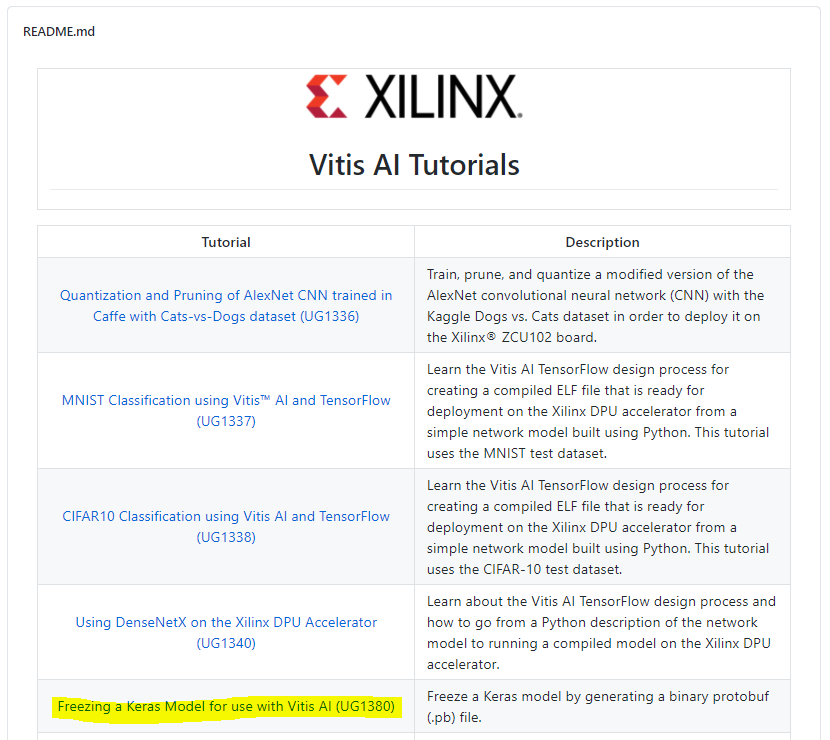
今回は、上の図でもハイライトしている 「Freezing a Keras Model for use with Vitis AI (UG1380)」 を試し、Kerasモデルの実装を行いました。
「Freezing a Keras Model for use with Vitis AI (UG1380)」には、Kerasベースのモデル(.h5)をVitis AI ver1.2.1を用いて、Alveo™ アクセラレータ カード, Zynq® UltraScale+™ MPSoC上に実装させる手順が記載されています。
サンプルのKerasモデルもございますが、今回は使いません!!
※もちろんサンプルも動作確認は完了しています!
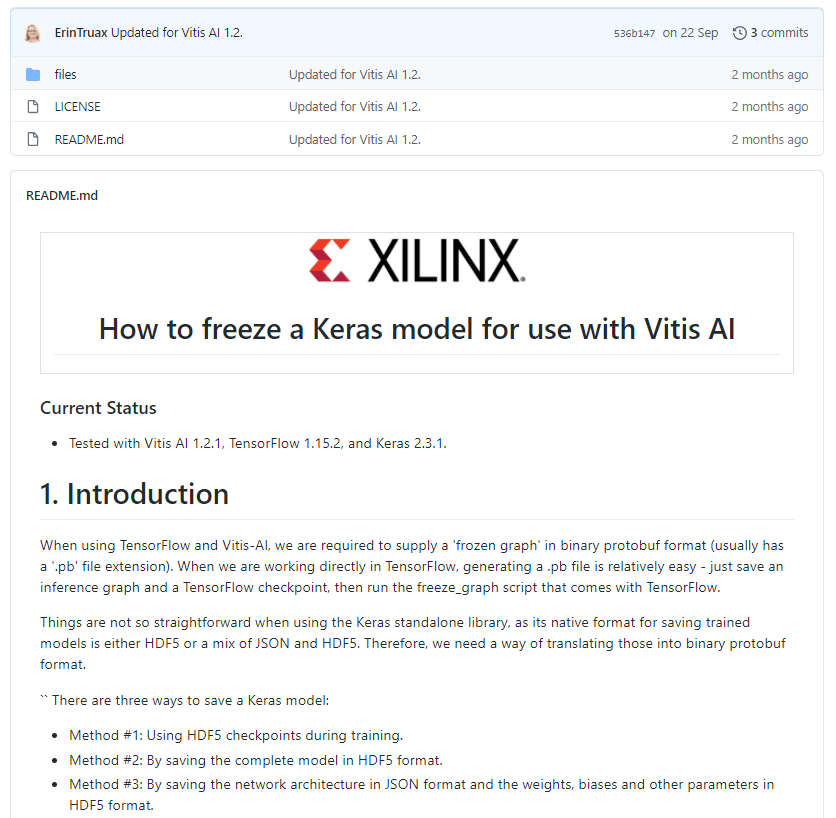
流れとしては、以下のようになります。
① KerasモデルからTensorFlow チェックポイントの作成
② 凍結済みTensorFlowグラフの作成
③ 量子化、コンパイル
Tutorialには、①~③で用いる変換ツールがすべて用意されているため、Kerasモデルさえ用意できれば、試せる状態となっています。
用意するKerasモデルのパターンは3通りに対応可能で
・Kerasチェックポイント
・アーキテクチャ、重みが一体化したhdf5ファイル
・アーキテクチャを保存したjsonファイル + 重みを保存したhdf5ファイル
いずれのパターンでも試すことが可能です。
今回は、アーキテクチャ、重みが一体化したhdf5ファイルを用いました。
使用機材
| hostPC |
OS : Ubuntu18.04 LTS |
→開発マシンとしてLinux搭載が必須になります。 WindowsPCでは開発できませんので、ご注意願います! |
|---|---|---|
| WindowsPC | OS:Windows 10 | →ZCU102 コマンドベース操作用として用います。 Tera Termを用いてUART、SSH経由で操作するため、用意しました。 |
| 評価ボード | Zynq UltraScale+ MPSoC ZCU102 | |
| SDカード | Micron社製 industrial micro SD card 32GB | →ZCU102はSDカード必須なので、microSD→SD変換アダプタを用いました。 |
事前準備
hostPC
✔ 作業ディレクトリの作成
今回は、homeディレクトリ直下に作成しました。
$ mkdir ~/Vitis
$ mkdir ~/Vitis/vitis_r1.2.1
✔ docker imageのインストール
docker imageをザイリンクス公式のDocker Hubよりインストールします。
以下URLにアクセスし、”latest”タグのimageをpullします。
https://hub.docker.com/r/xilinx/vitis-ai/tags?page=1&ordering=last_updated
✔ Vitis AI GitHubのインストール
Vitis AI ver1.2.1のGitHubをcloneします。
以下URLにアクセスし、”latest”タグのimageをpullします
$ cd ~/Vitis/vitis_r1.2.1
$ git clone https://github.com/Xilinx/Vitis-AI
✔ Vitis-AI-Tutorial GitHubのインストール
使用するVitis-AI-TutorialのGitHubをcloneします。
$ cd ~/Vitis/vitis_r1.2.1
$ git clone -b Moving-Edge-Cloud https://github.com/Xilinx/Vitis-AI-Tutorials.git
✔ VGG-16 GitHubのインストール
使用するモデルのGitHubをcloneします。
$ cd ~/Vitis/vitis_r1.2.1
$ git clone https://github.com/geifmany/cifar-vgg
WindowsPC
✔ Tera Termのインストール
ZCU102をUART、SSH経由で操作すべく、インストールします。
下記URLをご参照ください。
https://ja.osdn.net/projects/ttssh2/releases/
評価ボード ZCU102
✔ imageファイルをSDカードへ書き込み
参照 : https://github.com/Xilinx/Vitis-AI/blob/master/demo/Vitis-AI-Library/README.md#setting-up-the-target
ZCU102用のimageファイルが、上記GitHubリポジトリに公開されていますので「ZCU102」をクリックしダウンロードします。
※ファイル名:xilinx-zcu102-dpu-v2020.1-v1.2.0.img.gz

※ZCU102用imageファイルダウンロードリンクページ
Etcherを用いて、SDカードへ書き込みを行いました。
→https://www.balena.io/etcher/
学習
cifar10vgg.pyを用いて、VGG-16の学習を行います。
学習の前に、アプリケーションコードを少し編集します。
アプリケーションコード編集
✔ Batch Normalizationのコメントアウト化
以下のように、”build_model”で定義されているモデルの”model.add(BatchNormalization)”をコメントアウトします。
※コメントアウトした理由は[こちら]をご参照ください。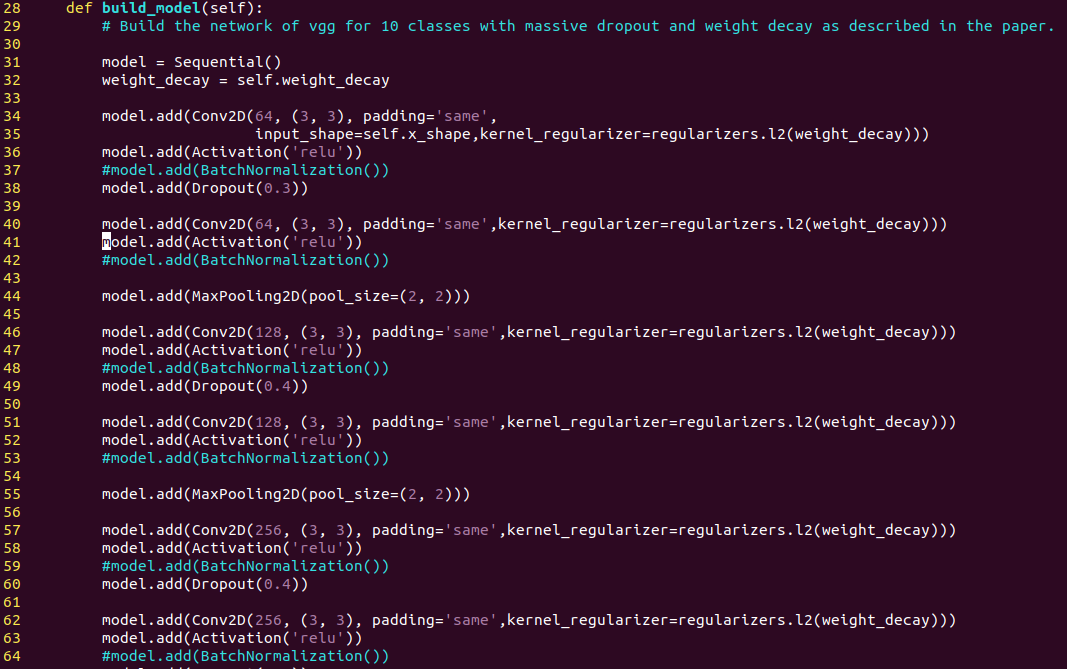
✔ 学習エポック数の変更
250回から1回に変更します。

✔ モデル保存方法の変更
デフォルトでは重みのみを保存しているので、アーキテクチャ+重みが格納されるh5を作るため、“model.save(‘cifar10vgg_non_batchnorm.h5’)”に変更します。
※この変更は任意で構いません。

学 習
以下のコマンドで学習を行います。
current dirは、cloneしたvgg-16モデルのメインリポジトリとなります。
$ python3 cifar10vgg.py
完了後、同ディレクトリに”cifar10vgg_non_batchnorm.h5”が生成されます。
これで学習は完了です!
KerasモデルからTensorFlowモデルへの変換
学習させたKerasモデルをTensorFlowベースへ変換させていきます。
変換ツールは、Tutorial内にありますので、そちらを用いていきましょう!
事前準備
✔ 学習させたKerasモデル移動
以下コマンドで、学習させたKerasモデルをVitis-AI-Tutorialディレクトリにコピーします。
※Vitis-AI-Tutorials/files直下に”model”ディレクトリを作成しました。
$ cd ~/Vitis/vitis_r1.2.1/cifar-vgg
$ cp cifar10vgg_non_batchnorm.h5 ~/Vitis/vitis_r1.2.1/Vitis-AI-Tutorials/files/model
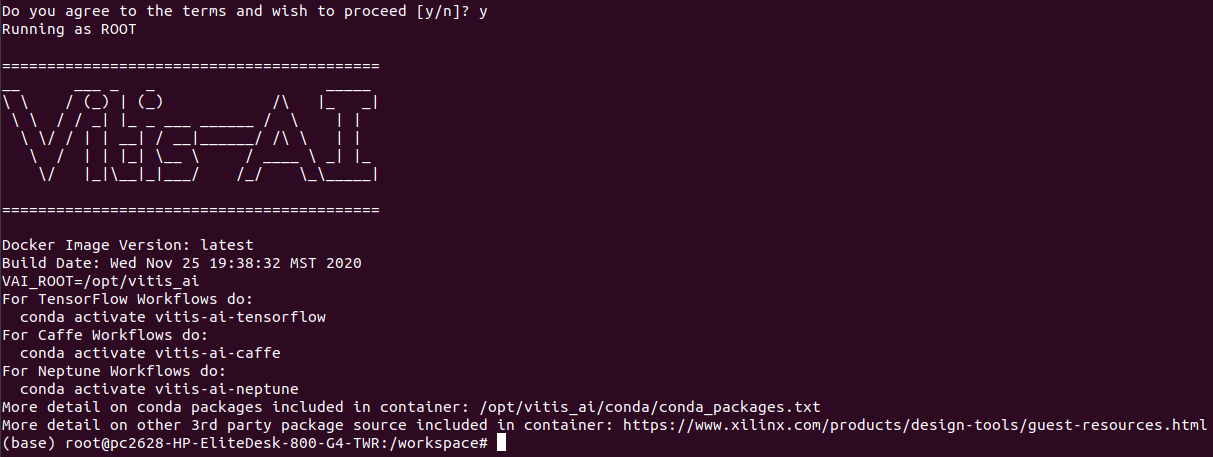
✔ Vitis AI Docker(CPU版)の起動
以下のコマンドで、CPU版のVitis AI Dockerを起動します。
$ cd ~/Vitis/vitis_r1.2.1/files
$ sudo su
# chmod +x ./docker_run.sh /dockerを起動するスクリプトに実行権限を付与
# source ./start_cpu_docker.sh
正常に起動すると、以下のようになります。
✔ 0_setenv.sh実行
様々な変数等を定義するスクリプト”0_setenv.sh”を実行します。
今回は、こちらで用意したモデルを用いるので、少し編集を行います。
以下の項目を設定変更します。
・INPUT_HEIGHT → 32
・INPUT_WIDTH → 32
・INPUT_NODE → conv2d_1_input
・OUTPUT_NODE → dense_2/BiasAdd
・NET_NAME → cifar10_vgg16
※ノード名の確認方法については、[こちら]を参照ください!!
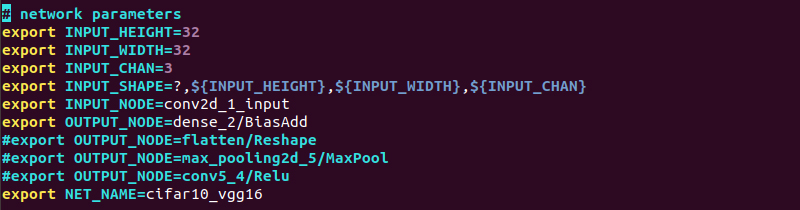
以下のコマンドで、実行します。
# source 0_setenv.sh
Anaconda環境が、(base)から(vitis-ai-tensorflow)になっていることを確認し完了です!
✔ 変換ツール(3_keras2tf.sh)の編集
Kerasモデル名を設定した名前に変更します。
モデル名が、cifar10vgg_non_batchnorm.h5なので、“—keras_hdf5”の箇所を以下のように変更します。
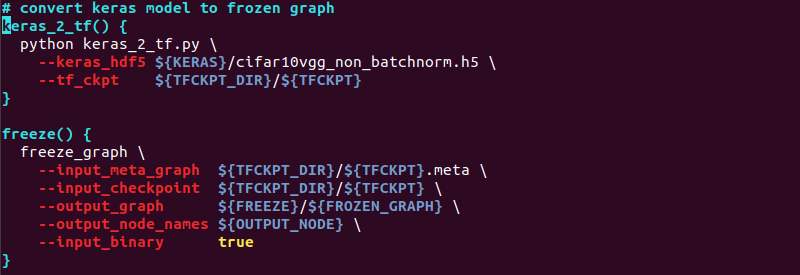
長くなってしまいましたが、これで準備完了です!
✔ KerasモデルからTensorFlowモデルへの変換
早速、変換していきましょう!
作成したKerasモデルをbuild/keras_modelディレクトリにコピーし、実行します。
# cp model/cifar10vgg_non_batchnorm.h5 build/keras_model
# source 3_keras2tf.sh
正常に終了すると、以下のように”freeze”,”tf_chkpt”ディレクトリが生成され、“freeze”ディレクトリ内に凍結済みのpbファイルが生成されます。
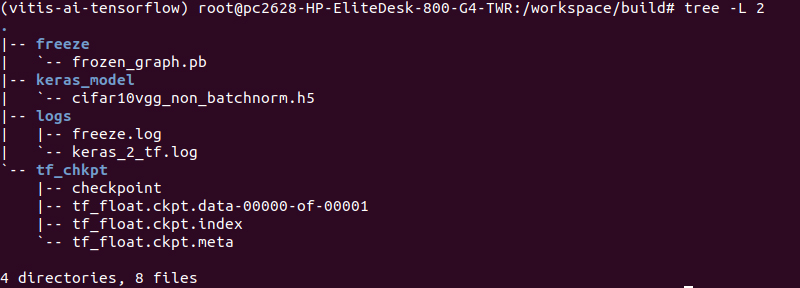
TensorFlowモデルへの変換はこれで完了です!お疲れ様でした!
量子化
vai_q_tensorflowという量子化ツールを用いて、量子化を行っていきます。
実行としては、5_quant.shというスクリプトを実行するのみですが、こちらも事前準備が必要になります。
一番重要なポイントは、量子化するにあたり、学習で使用した画像データを複数枚用意する必要があることです。
以下が、Vitis AIユーザガイドに記載されていた量子化に関する内容の抜粋です。
(https://www.xilinx.com/html_docs/vitis_ai/1_2/zvf1570695925069.html)
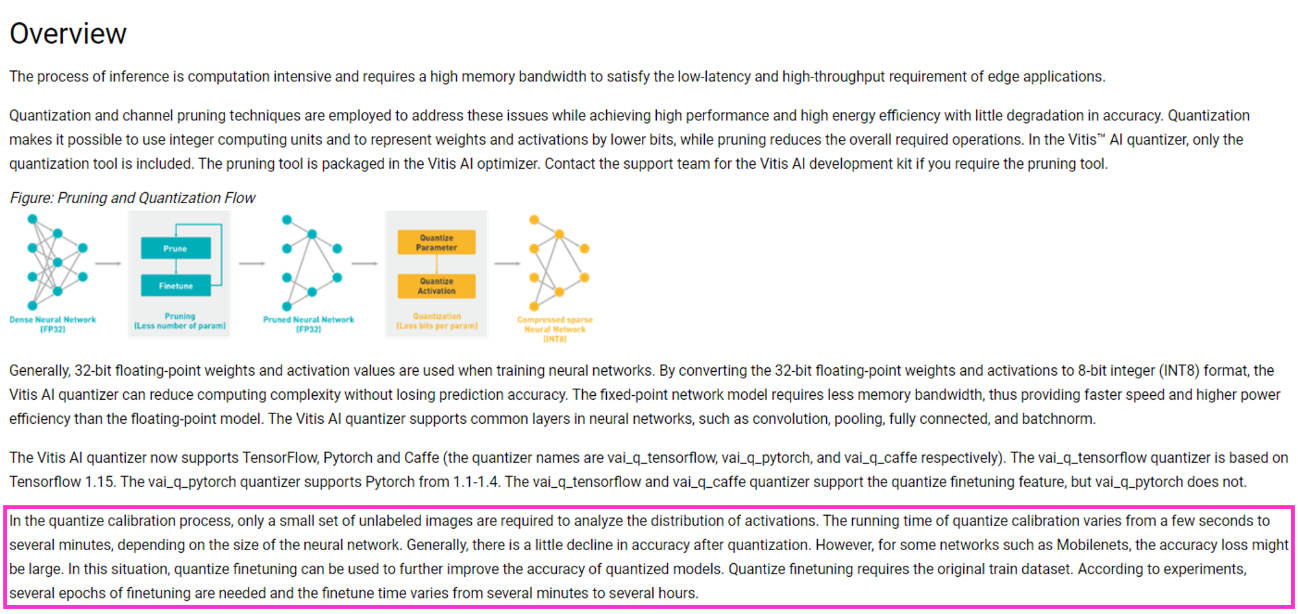
ハイライトした箇所にあるように、量子化するにあたり精度を担保するために学習データを用いたキャリブレーションなるものを実行しているようです。
注意点もあり、mobilenetなどいくつかのモデルでキャリブレーションを行うことにより精度が落ちてしまう可能性があるとのことでした。
どの程度落ちるか、どういったアーキテクチャをしたモデルが精度減衰を起こすのかベンチマークなどは見つかっていませんが、日々チェックしていきたいと思います!
話がそれてしまいましたが、準備に取り掛かりましょう!
事前準備
✔ cifar-10画像データの用意
cifar-10のサイトからダウンロードが可能ですが、実体はバイナリデータです。
画像データとして保存する場合、別途コードを用意する必要があります。
め、めんどくさいなぁ。。と思っていたのですが、なんと!コードが記載されているwebを見つけました!(https://cafe-and-cookies.tokyo/wp/?p=942)
記載されているコードを実行すると、以下のようなディレクトリ構成となり画像が保存されます。

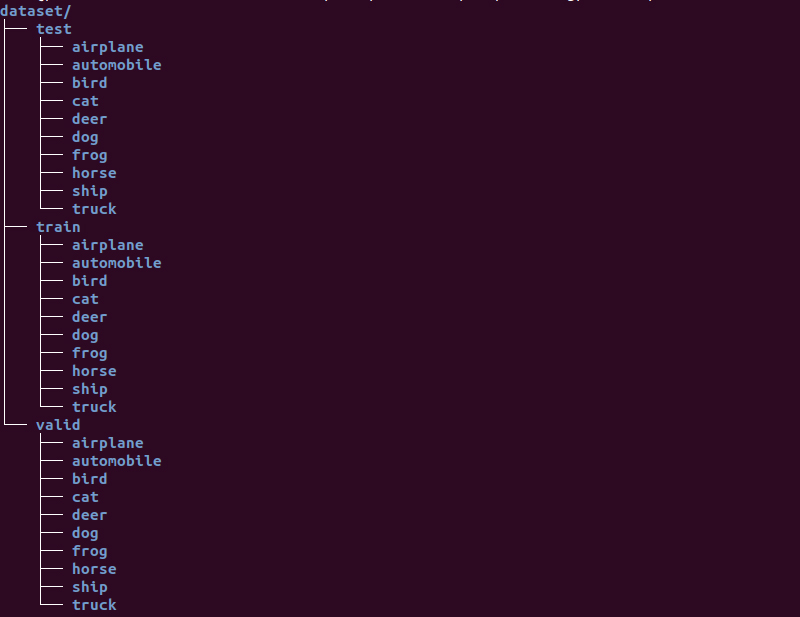
これらを”test”,”train”,”valid”という名前で複製し、”dataset”というディレクトリにひとまとめして作業完了です!
datasetディレクトリは、Vitis-AI-Tutorial/files直下に保存します。
※注意※
ここで用意する画像は、モデルのinputサイズと同じにする必要がありますのでご注意願います!!!
※更に注意!!※
この後、ZCU102上で実行するサンプルコードを用いるのですが、もしそのサンプルコードを用いる場合は、画像名を”クラス名.番号.png”に変更する必要があります!
理由は[こちら]に記載していますので、ご確認ください!
以下、私が作成した画像名の一部抜粋です。
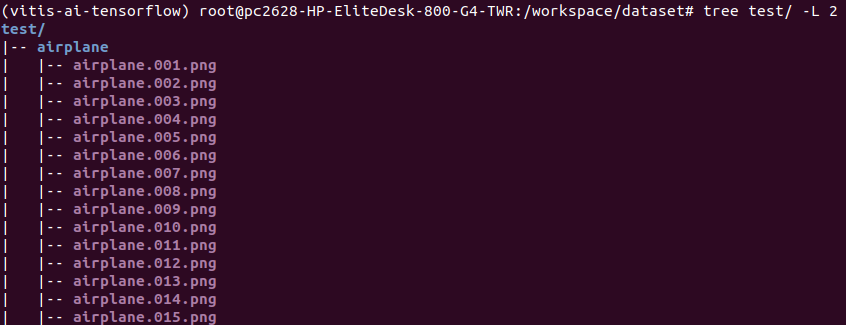
私の場合は、WindowsPC上でFlexible Renamerを用いて一括変換をしました。
(https://www.vector.co.jp/soft/winnt/util/se131133.html)
Windows環境であればこちらお勧めします!
Windows 10でも動きますので、ご安心を!
量子化
準備ヨシ!量子化実行に移ります!
以下コマンドで、量子化実行です!
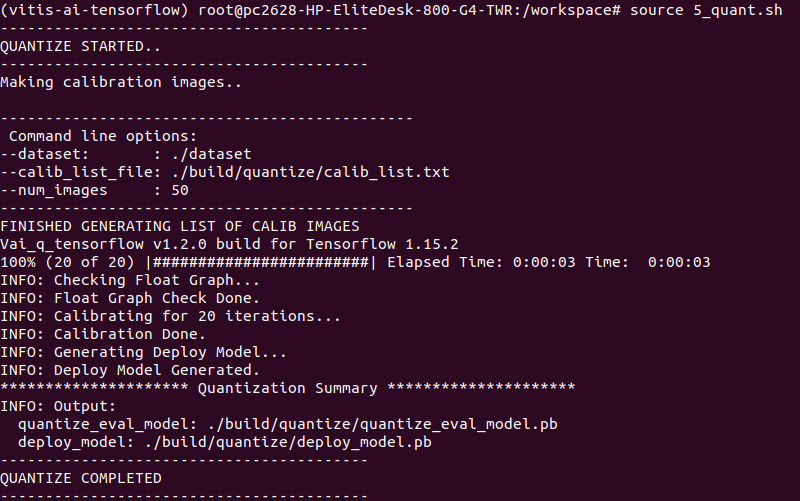
# source 5_quant.sh
正常に完了すると、以下のようなメッセージが出力されます。
※ここで先ほど用意した画像のサイズがモデルのinputサイズ異なるとエラーがでました。。
また、キャリブレーションに用いる画像枚数は、0_setenv.shで設定できますので、もしエラーが出ている場合はそちらも併せてご確認ください!
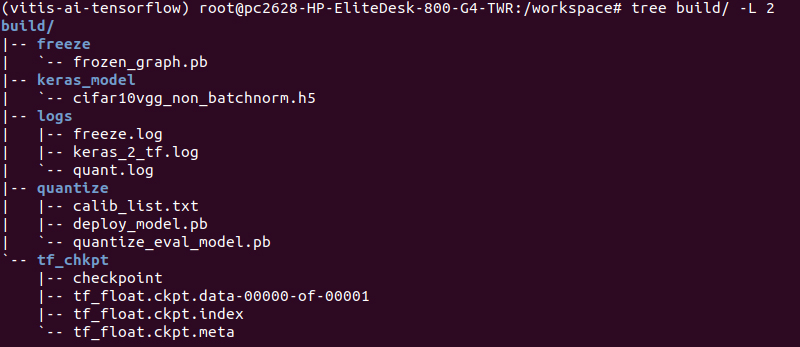
完了後、”build”ディレクトリに”quantize”ディレクトリが生成され、量子化されたpbファイルが生成されます。
検証を始めた当初は、ここでつまずいていました。。
後ほど述べますが、ここでDPUが対応していないレイヤーが含まれるとCPU演算になるような警告が出てきます。
詳細は[こちら]
ここまできたらあと少しです。
とりあえずコーヒーでも飲んで休憩しましょうか(笑)
コンパイル
さあ!最後の一押しです!
コンパイルは、個人的な経験では量子化が通れば、おそらく問題なく実行できます!
事前準備も必要ございません!メインディッシュに取り掛かっていきましょう!
コンパイル
vai_c_tensorflowを用いて、コンパイルを行います。
こちらも量子化同様、7_compile_XX.shという実行スクリプトが存在しますのでそちらを実行するのみです。
今回はZCU102を用いるので、以下コマンドで実行します!
# source 7_compile_zcu102.sh
以下のように出力されれば、オッケーです!
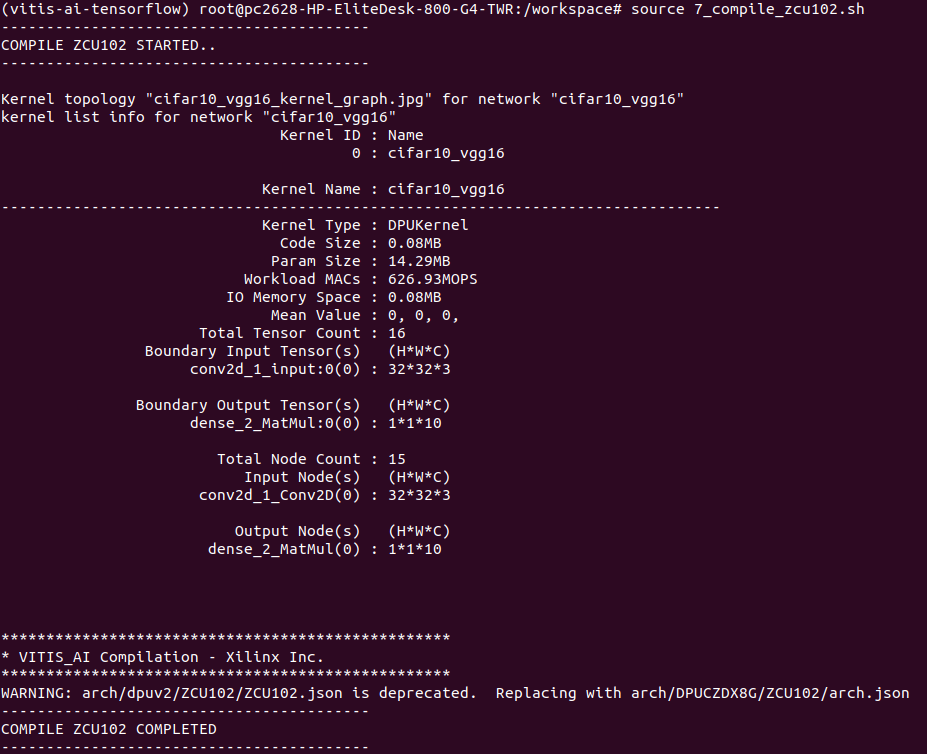
ここで、以下の点に注目し問題がないことを確認します!
・input node が、0_setenv.shで設定したheight,width,channelになっているか
・output nodeのchannelが、分類したいクラス数と一致しているか
完了後、”build”ディレクトリに”compile_zcu102”ディレクトリが生成されコンパイルされたelfファイルが生成されます。
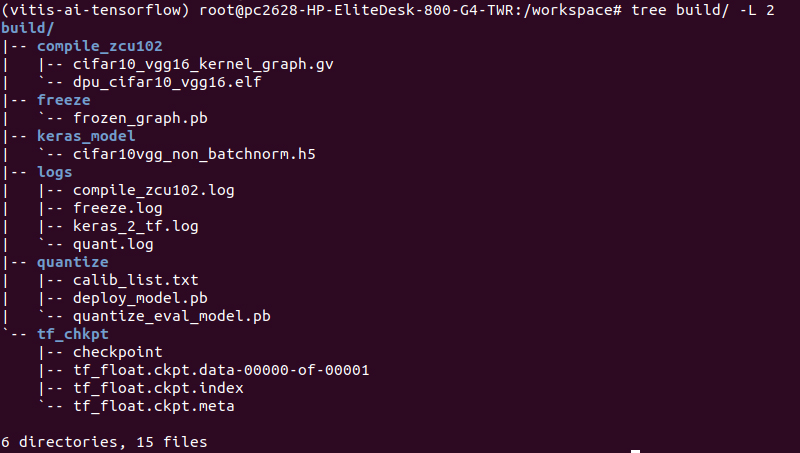
やっとここまできました!
学習はほとんど行っていないので精度は期待できませんが、とりあえず動くことを願って実装作業に取り組んでみることにします。
ZCU102へ実装
今回実行コードは、サンプルで用意されているpythonベースのものに変更を加えたものを用いました。
事前準備にて変更箇所を記載します。
最後、気合い入れていきましょう!
事前準備
✔ ZCU102へdeployさせるディレクトリ作成
ありがたいことに、deployに必要なファイルを1つのディレクトリにまとめてくれる実行スクリプト(8_make_target_zcu102.sh)が存在します。
この実行スクリプトは、サンプルモデルを想定しているので少し変更を加えます。
検証用画像を格納するディレクトリを作成する工程で、サンプルでは2クラス分類ですが、今回は10クラス分類になるので以下のように変更を加えます。
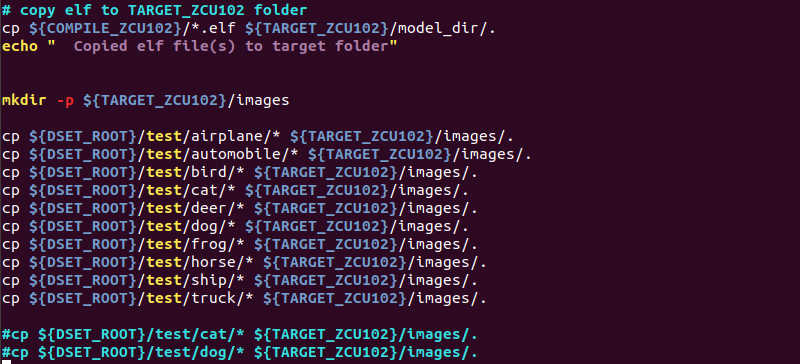
変更完了後、以下のコマンドを実行しディレクトリを作成します。
# source 8_make_target_zcu102.sh
正常に終了後、”build”ディレクトリに”target_zcu102”ディレクトリが生成され、その中に必要なアプリケーションコードや検証用画像が格納されます。
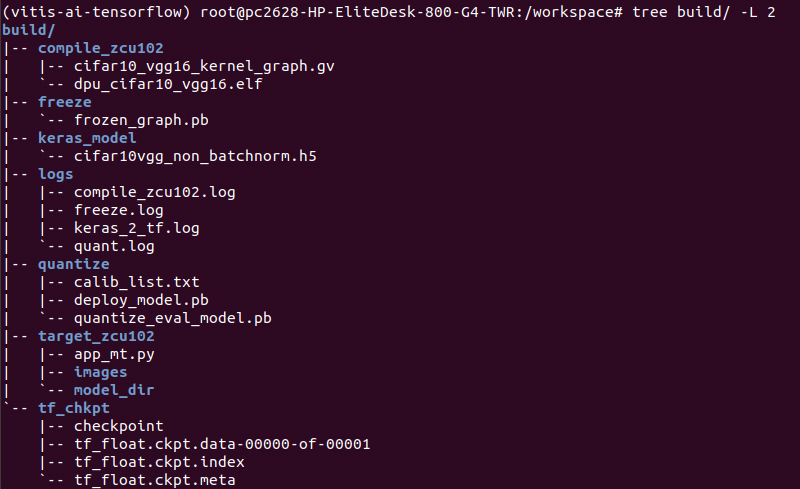
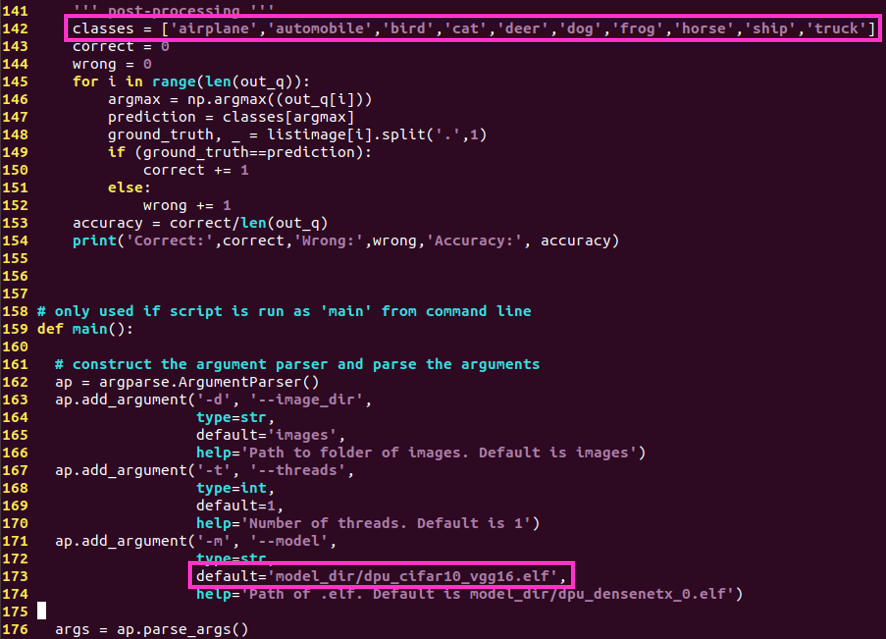
✔ 実行コード(app_mt.py)の編集
サンプルベースから、今回のモデル仕様に変更します。
変更箇所は2箇所です。
・142行目の”classes”を10クラス分類用に変更
・173行目のelfファイル名を生成したファイル名に変更
変更を反映させた実行コードが以下になります。
✔ ZCU102上へdeploy
ZCU102を起動し、hostPCと同じネットワークに接続していることを確認します。 ※私で設定したネットワーク関係については、[前回の記事]をご参照ください! 以下コマンドでZCU102へdeployします。
# scp -r target_zcu102 root@ZCU102_IPv4:~/
いざ実行!
ここまでくれば、あとは実行コードを実行するのみです!
先ほどZCU102へdeployしたディレクトリが、homeディレクトリ直下にありますので以下のコマンドで実行コードを叩きます!
# cd ~/target_zcu102
# python3 app_mt.py
実行後、以下のようにFPS、正答率などが出力されます!
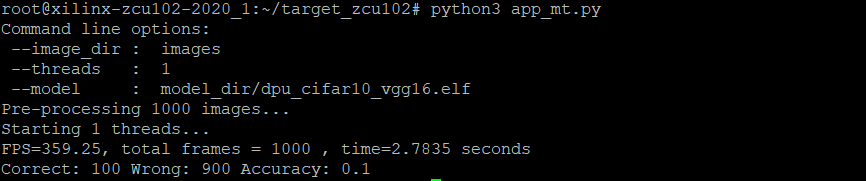
epochが1なので、正答率は恐ろしくひどいですが。。
とりあえず、正常に動作できてひと安心です!!
処理速度は、分類タスクなだけに相当速いですね。
検出などになるとどうなるのでしょうか?その辺についても今後トライしてみたいと思います!
※正答率の算出方法について
今回使用した、実行コード(app_mt.py)では少し変わった方法で算出しています。
ざっくりとした流れは以下の通りです。
・定義したoutput node数分値が出力され、その中から最大値及びそのリスト番号を抽出
・142行目で定義したclassesリストとリスト番号を参照し、分類したクラス名を出力
・”クラス名.番号.png”で定義された画像名の”クラス名”と照らし合わせ、正解か判定
・正解した画像数を使用した全画像数で割り、正答率を算出
まさか、画像ファイルを使って正答率を出しているとは。。(笑)
画像名を”クラス名.番号.png”で保存しなければいけない理由は、このためですorz
ただし、あくまでサンプルなので、 後処理に関しては自由にカスタマイズして頂いても良いかと思います!
以下が実行コードにおける正答率算出箇所です。
参考情報
input,outputノード名の確認方法
Vitis AIでTensorFlowを用いるにあたり、input及びoutputノード名を把握する必要があります。
個人的にはここが一番面倒な作業だと思っています。。
色々と方法はありますが、今回はTensorBoardを用いました!
Vitis AI Docker上にTensorBoardがございますので、インストールの必要はございません。
では、順を追って解説していきます!
✔ TensorBoardに反映させるグラフを定義
以下のコードを書いたpythonファイルを作成します。
名前は任意ですが、今回はnode_check.pyという名前にしました。
import tensorflow as tf
from tensorflow.summary import FileWriter
sess = tf.Session()
tf.train.import_meta_graph("tf_float.ckpt.meta")
FileWriter("__tb", sess.graph)
node_check.pyを、metaファイルが存在するディレクトリにコピーします。
※3_keras2tf.shを実行すると、metaファイルが”build/tf_chkpt”ディレクトリに自動で生成されます!
✔ TensorBoardの起動
作業ディレクトリは、”build/tf_chkpt”となります。
起動前のディレクトリはこんな感じです↓
以下のコマンドで起動します!
# tensorboard –-logdir __tb
実行後、URLが出力されるのでそちらをクリックするとwebブラウザ上で確認できます。 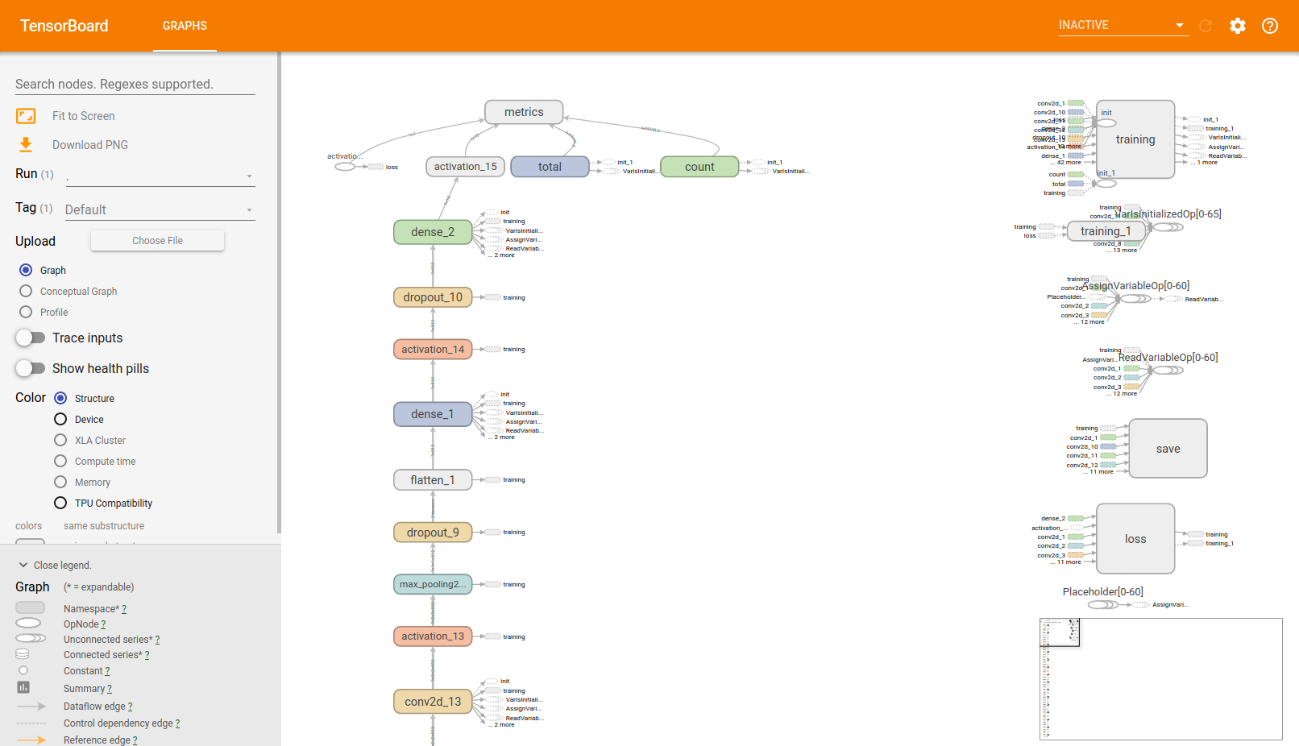
✔ inputノード名確認
グラフを下にスライドすると、以下のように一番下に〇が存在します。 この〇がinputノードで、クリックすると右上に名前や詳細が表示されます。 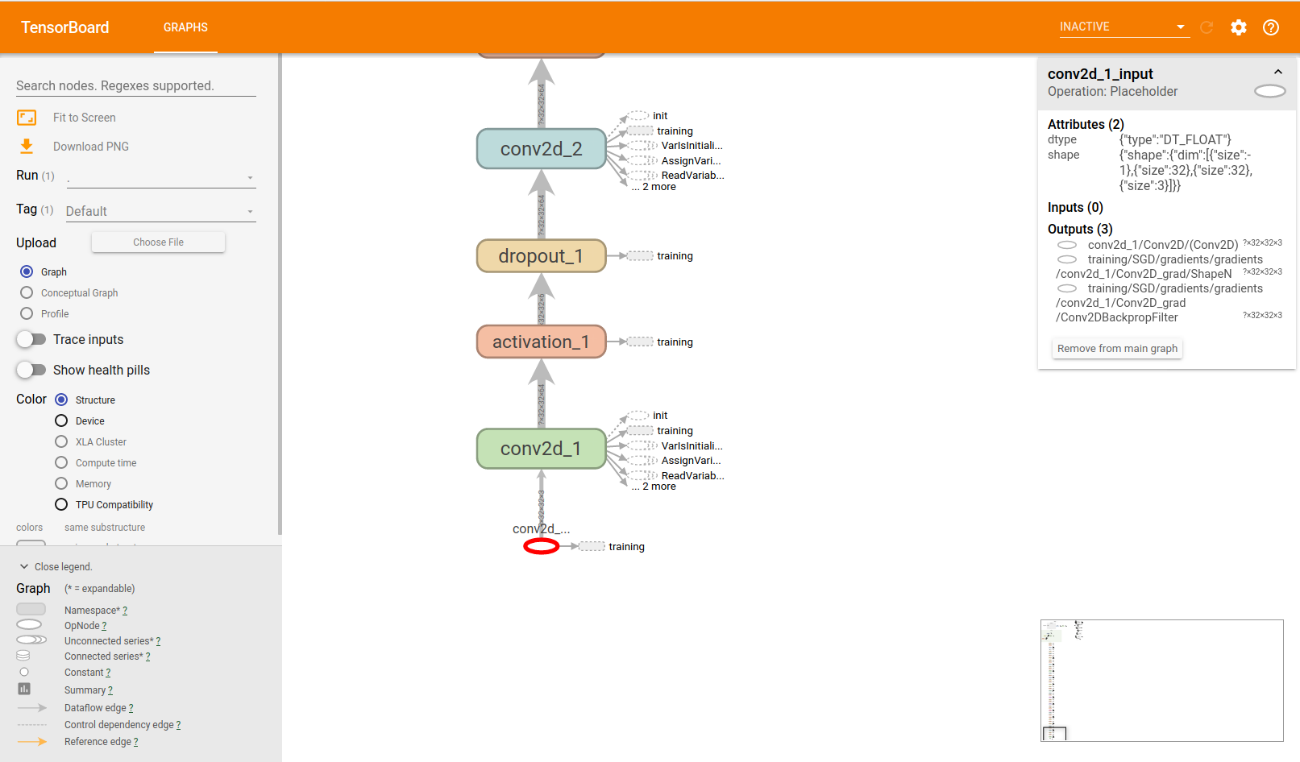
右上に表示されている名前が、inputノード名となります。(今回はconv2d_1_input)
✔ outputノード名確認
グラフを上にスライドすると、一番上に”metrics”があります。
metricsに接続している”activation_15”がoutputノードとなります。
ただし、今回はその前の”dense_2”をoutputノードとします。
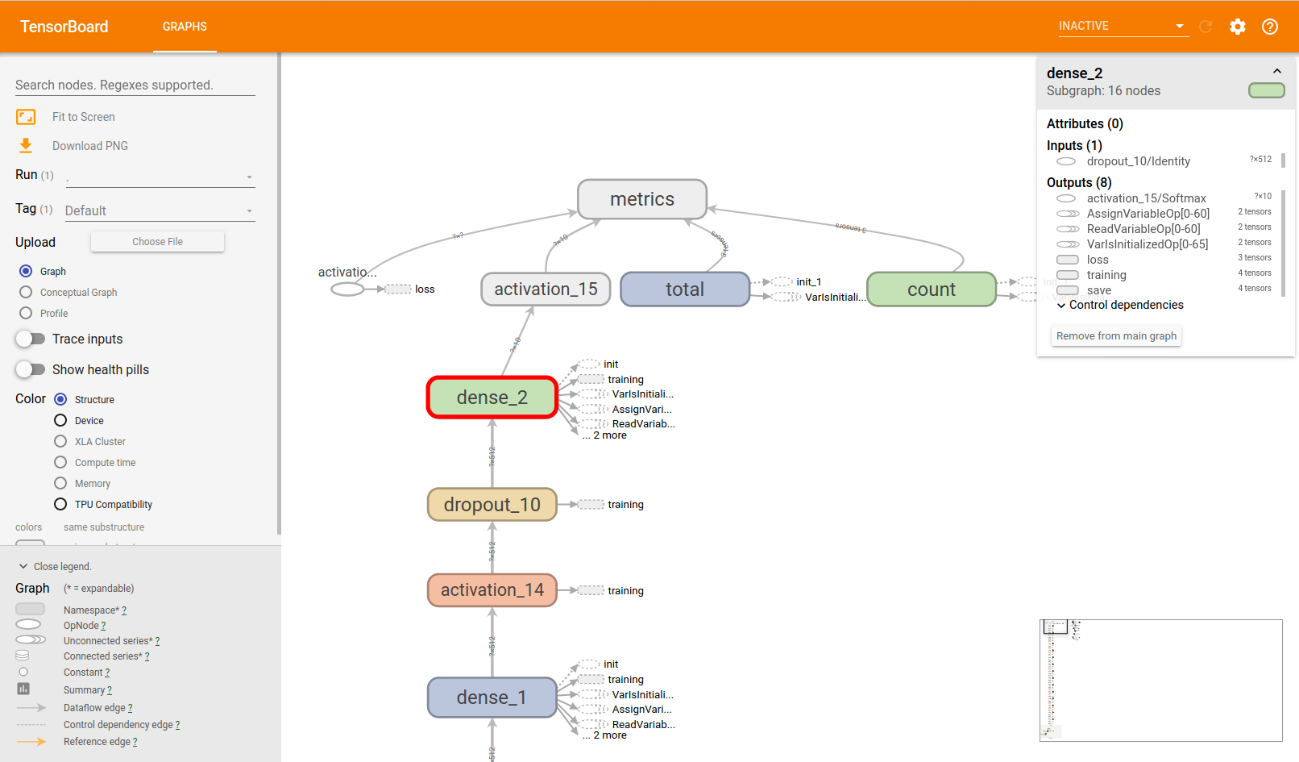
更に”dense_2”をクリックし、詳細を確認します。
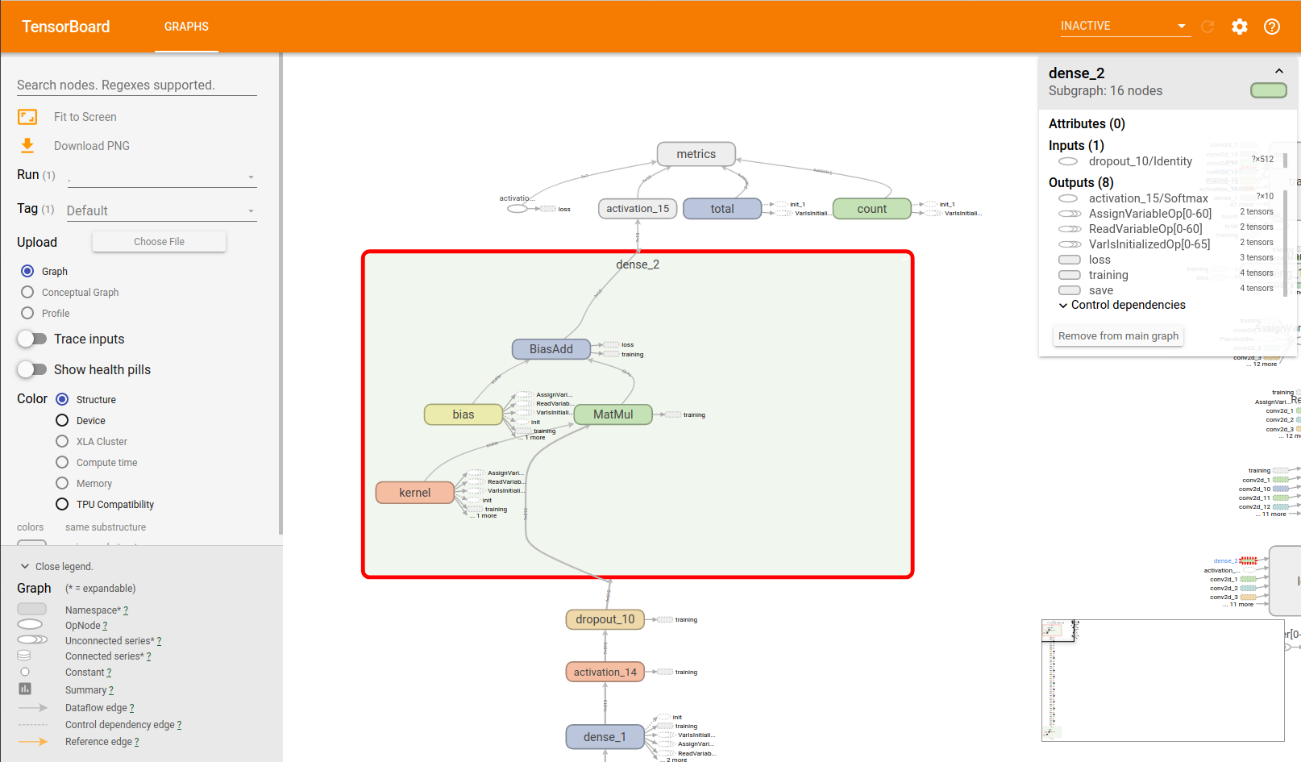
すると、outputに一番近いノードが、”BiasAdd”になるので、今回求められているoutputノード名は、”dense_2/BiasAdd”となります。
これで、確認終了です!
今回で本格的にTensorBoardを使用したのですが、とても便利ですね!
これでTensorFlow関連のモデル構築も捗りそうです。
DPU非対応のレイヤーについて
DPUに対応していないレイヤーがいくつか存在しています。
もし非対応のレイヤーがある場合は、実行コードで別途関数として定義する必要があるのですが、定義方法に関するドキュメントがなく、今回はスルーとさせていただきました。
現在、私の方で確認がとれている非対応レイヤーは、以下の通りです。
・Softmax
・Batch Normalization
Batch Normalizationについては、コンパイルでエラーとなってしまい実装することができませんでした。。
エラーメッセージをみても検討がつかなかったため、今回はBatch Normalizationについてもスルーとさせていただきました。
・ Softmax
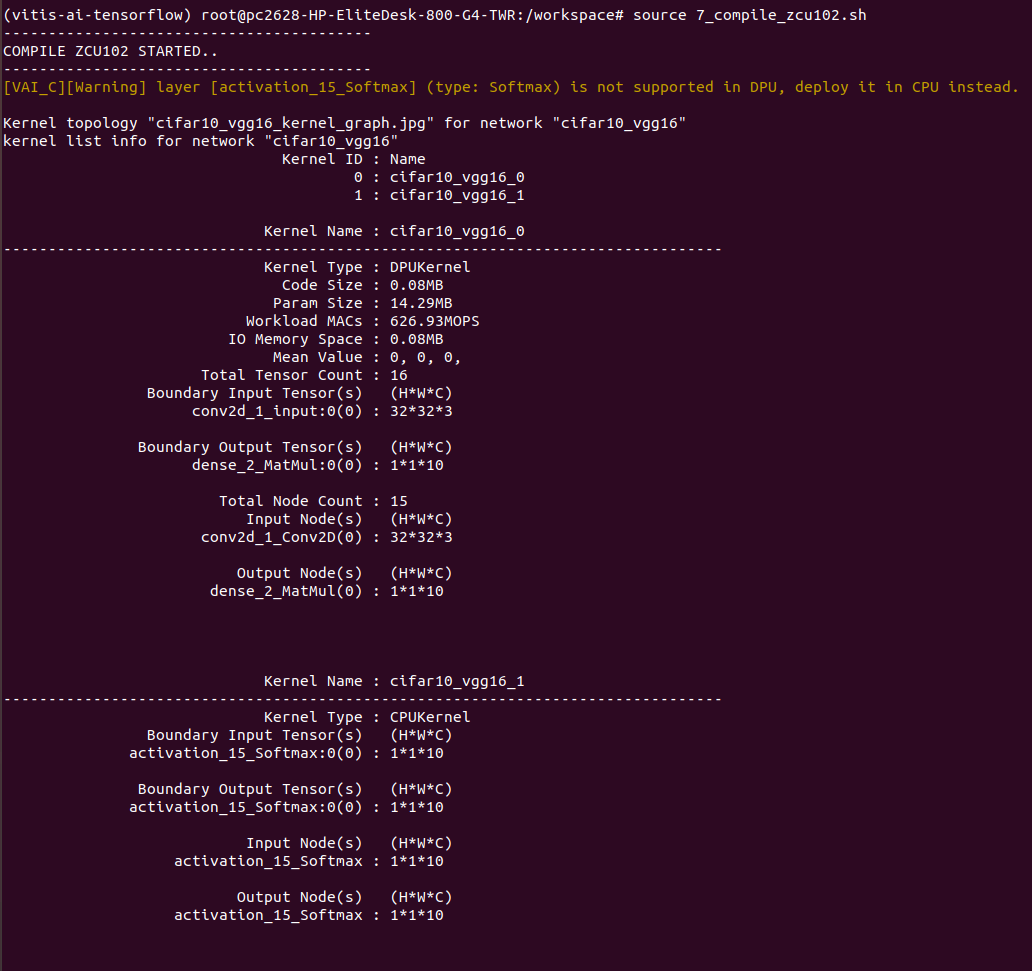
Softmaxをoutputノードに指定して(activation_15/Sofmax)コンパイルを行うと以下のように、警告が出力されました。
- [VAI_C][Warning] layer [activation_15_Softmax] (type: Softmax) is not supported in DPU, deploy it in CPU instead.
表示されるコンパイル済みファイルの結果も増えていました。
ただし、コンパイル済みファイルは、”DPUKernel”のもののみで、”CPUkernel”は存在していませんでした。。このあたりも今後詳しく調べていきます!
・ Batch Normalization
Batch Normalizationを用いると、量子化の時点で警告がでてきます。
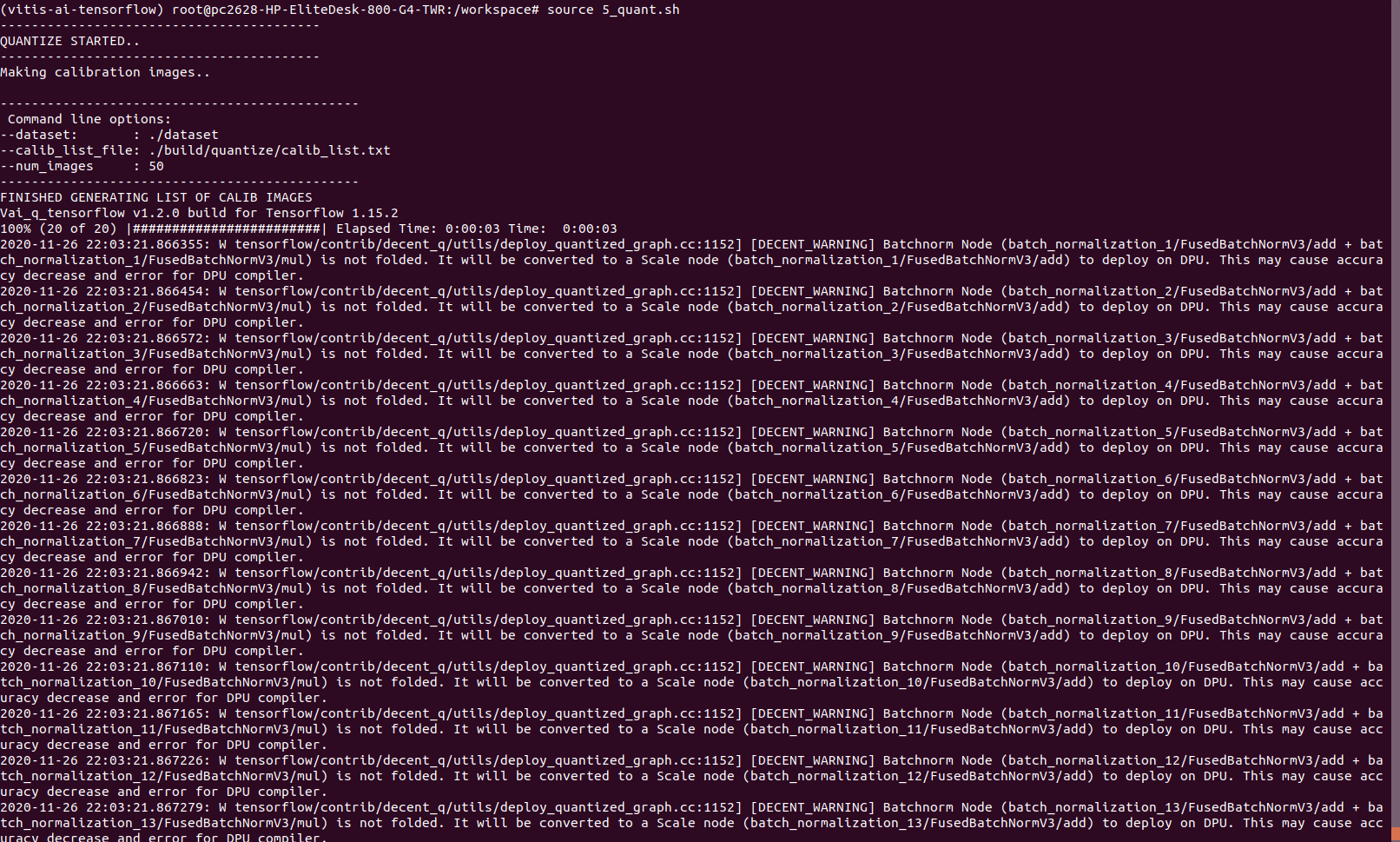
- [DECENT_WARNING] Batchnorm Node
(batch_normalization_1/FusedBatchNormV3/add +
batch_normalization_1/FusedBatchNormV3/mul) is not folded. It will be converted to a Scale node (batch_normalization_1/FusedBatchNormV3/add) to deploy on DPU. This may cause accuracy decrease and error for DPU compiler
以下が実際の出力画面です。おびただしい警告ですね。。
そのままコンパイルを実行すると。。。
以下のエラーが出てしまい、コンパイルができませんでした。
- [VAI_C-BACKEND][Check Failed: shift_cut >= 0][/home/xbuild/conda-bld/dnnc_1592904456005/work/submodules/asicv2com/src/SlNode/SlNodeDptConv.cpp:55][DATA_OUTRANGE][Data value is out of range!]
これが、実際のエラー画面です。

こちらも引き続き調査とさせていただきます!
作業を振り返って
最後までお付き合いいただきありがとうございました~!
今回、ザイリンクス社が用意したサンプルではなく、オープンソースのモデルを動かせた収穫はとても大きかったと思います!
まだまだ制限はありますが、今後情報公開されるのが楽しみです!
分類だけでなく、検出や領域分割などにも試していきたいですね~
より実運用に向けた実装ができて嬉しかったですが、これに満足せず色々なモデルを試していきたいと思います!
それではまた!TEPPE-AIでした~



















