Vitis™ AIを用いて、オープンソースのYOLOをKria™ KV260上で動かしてみた


-
皆さまこんにちは!TEPPE-AIです!
大変ご無沙汰しております。今回のタイトルはこちら!
「Vitis™ AIを用いて、オープンソースのYOLOをKria™ KV260上で動かしてみた」
本ブログはKria™ KV260 ビジョン AI スターター キット(以降、KV260)と呼ばれるAMD ザイリンクス社が新たに提供を開始したFPGA搭載SoCの評価ボードを活用した記事です。

KV260は、FPGA本来のメリット(長期供給,電力効率)を抑えつつ、開発を容易にする環境も用意しており、開発コストを大きく削減できるデバイスになります。
詳細は、弊社WEBサイトで紹介していますので、気になる方はこちらをクリック!
今回は、KV260上で、物体検出のAIモデルとして有名なYOLOを実装してみました。
AIモデルの変換やアプリケーションの作成など、開発にあたっての必要な工程をひと通り試してみましたので、是非皆さまの開発の一助となれたらと思います。
それでは参りましょう!
目次
作業概要
今回は、こちらからダウンロードできるTiny YOLOv3をKV260へ実装します。
主な流れとしては、以下の通りです。

用いる環境は、以下の通りです。
| Hardware | hostPC | CPU | Intel core i7 |
|---|---|---|---|
| GPU | NVIDIA GeForce GTX1080Ti ※今回は不要です | ||
| OS | Ubuntu18.04 | ||
| 評価ボード | Kria™ KV260 | ||
| OS | Linux(yocto) | ||
| Software | Vitis AI | 2.5 | |
| DPU | core | DPUCZDX8G_ISA1_B4096_MAX_BG2 ※MPSoC向けDPUで、コアarchはB4096になります |
|
| コア数 | 1 | ||
学習工程は含みません。
ダウンロードするTiny YOLOv3はcocoデータセットで学習済みになっているので、今回は実装までの流れを紹介することをメインとさせていただきます。
推論アプリ構築の説明部分で、どこに何を追加すれば機能を拡張できるのかについても解説していますので、本記事を参考に実現させたい処理を実装いただければと思います。
本記事を参考いただければ、v3以外のYOLO(v2,v4,X)も実装できるかと思いますので、是非最後まで見ていただければ幸いです。
- ※
- 執筆中の2023/1にVitis AI 3.0がリリースされ、YOLOv5,v6が対応となりました。
アップデートサマリは後日記事にしたいと思います。
使用機材
| hostPC | OS | Ubuntu18.04 | Linux環境が必須となりますのでご注意ください。 GPUは必須ではありません。 |
|
|---|---|---|---|---|
| 作業項目 | AIモデルダウンロード、AIモデル量子化/コンパイル | |||
| Kria™ KV260 ビジョン AI スターターキット | Linux(yocto) | 今回はリファレンスデザインを用いて検証を行います。 | ||
| 作業項目 | アプリケーション構築、アプリケーション実行 | |||
| KV260操作用PC | Windows10 | USB-UARTでKV260を操作しますので、操作用のソフト,ドライバのインストールをお願いします。 | ||
| 作業項目 | KV260操作 | |||
| microSDカード | Micron製 industrial micro SD card 32GB | リファレンスデザインはSD IMGのため、起動用として用意します。 PALTEKで取り扱っていますので、気になる方はこちらからクリックお願いします! |
||
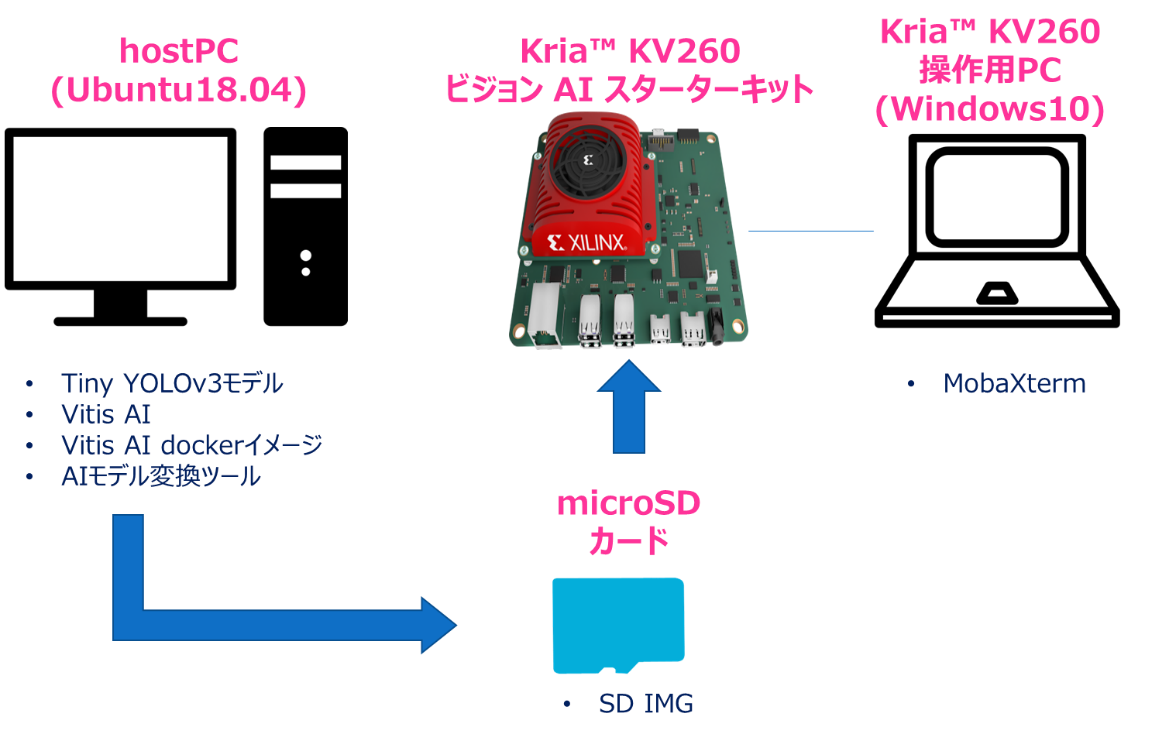
※接続イメージ
事前準備
hostPC
◆ Vitis AIダウンロード
以下コマンドでダウンロードします。
$ cd ~/Vitis/vitis_r2.5
$ git clone https://github.com/Xilinx/Vitis-AI
◆ Vitis AI dockerイメージ(CPU版)インストール
変換環境として、dockerを用います。
CPUとGPUで用意がありますが、本作業ではどちらでも大丈夫です。
今回はCPUを用います。
Docker hubにイメージがあるので、以下コマンドでダウンロードします。
$ docker pull xilinx/vitis-ai:2.5◆ AIモデル変換ツールインストール
以下2つをダウンロードします。
- ①
- darknet→keras重み変換ツール
- ②
- 量子化実行スクリプト(python)
作業時に分かりやすくするために、予め作業フォルダをつくっておきます。
こちらは任意で問題ありませんので、ご自由に作成してください。
$ cd ~/Vitis/vitis_r2.5/Vitis-AI/model_zoo
$ mkdir -p work/d2k
$ mkdir -p work/quant
① darknet→keras重み変換ツール
こちらのGithubをダウンロードします。
先ほど作成したd2kディレクトリを活用します。
$ cd work/d2k
$ git clone https://github.com/qqwweee/keras-yolo3
② 量子化実行スクリプト(python)
Vitis AIを用いて量子化するpythonスクリプトをダウンロードします。
こちらにあるVitis AI Model Zooをダウンロードします。
用いるスクリプトは、作業工程にて説明します。
$ cd ../quant
$ wget https://www.xilinx.com/bin/public/openDownload?filename=tf2_yolov3_coco_416_416_65.9G_2.5.zip -O tf2_yolov3_coco_416_416_65.9G_2.5.zip
$ unzip tf2_yolov3_coco_416_416_65.9G_2.5.zip
$ cd tf2_yolov3_coco_416_416_65.9G_2.5/code/test
$ mkdir float
作業終了後、workディレクトリが以下のようになっていればOKです!
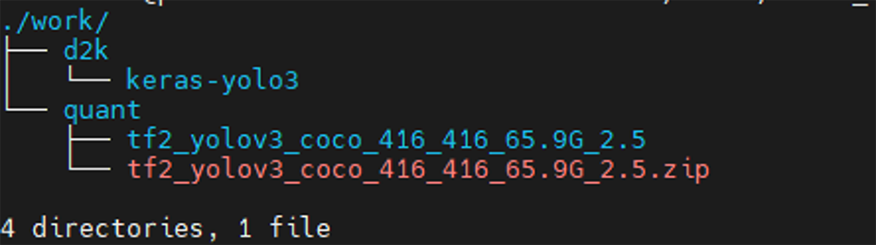
- ※
- d2kディレクトリ:AIモデル darknet→keras変換にて使用
- ※
- quantディレクトリ:AIモデル 量子化にて使用
評価ボード
◆ リファレンスデザイン SD IMG書き込み
GitHub上にあるリファレンスデザインをmicroSDに書き込みます。該当ページの以下のハイライト箇所をクリックすると、ダウンロードされます。
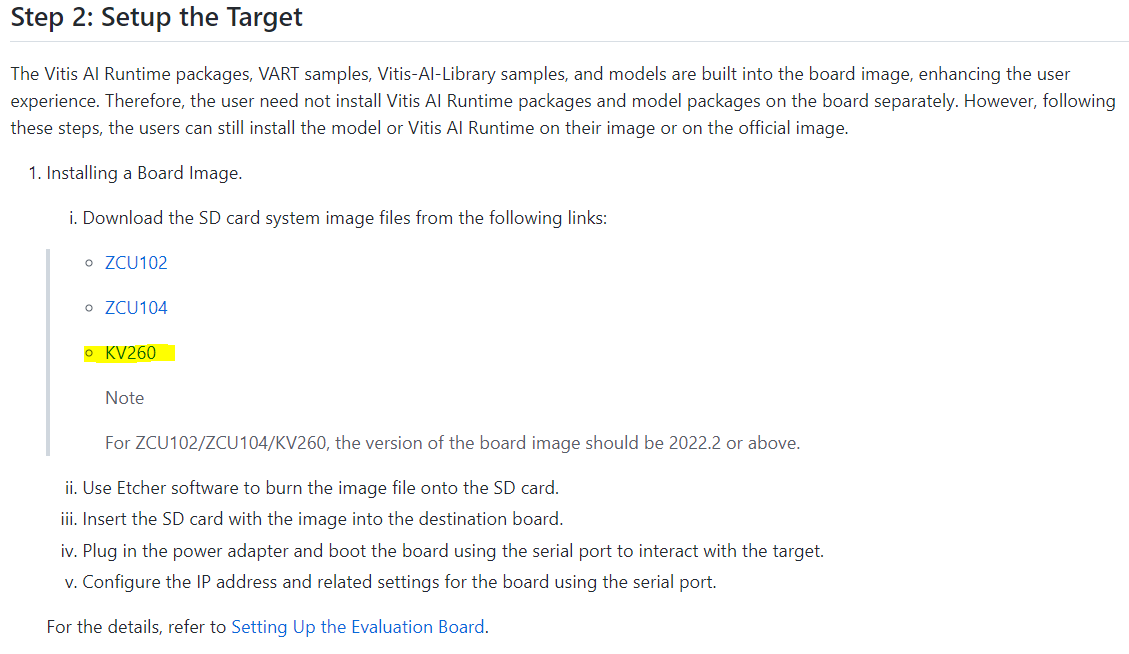
出典:https://github.com/Xilinx/Vitis-AI/tree/2.5/setup/mpsoc#step2-setup-the-target
作業(hostPC)
AIモデル ダウンロード
darknet版のTiny YOLOv3をダウンロードします。
$ cd ~/Vitis/vitis_r2.5/Vitis-AI/model_zoo/work/d2k/keras-yolov3
$ wget https://pjreddie.com/media/files/yolov3-tiny.weights
カレントディレクトリに「yolov3-tiny.weights」があればダウンロード完了です!

AIモデル darknet→keras変換
Vitis AIで量子化するために、先ほどダウンロードしたモデルをkeras形式(.h5)に変換します。
$ cd ~/Vitis/vitis_r2.5/Vitis-AI/model_zoo/work/d2k/keras-yolov3
$ python3 convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/yolov3-tiny.h5
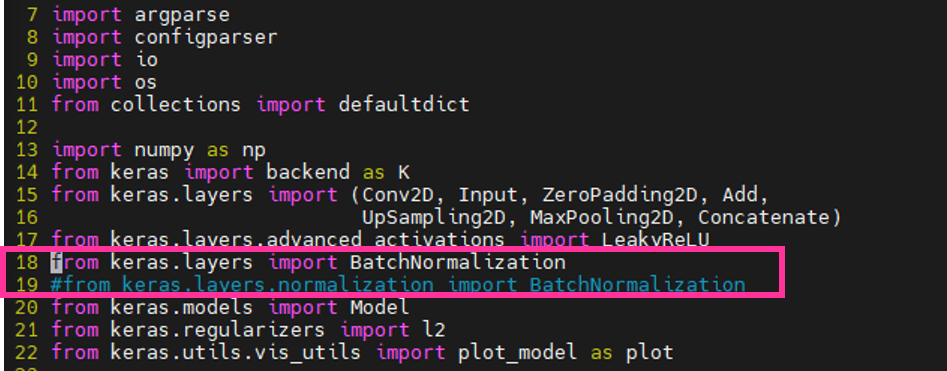
- ※
- 変換で1点ご注意です。
筆者環境では(python==3.6.9, keras==2.6.0)の場合、上記変換スクリプト(convert.py)を実行するとエラーになります。↓

回避策として、conver.pyの18行目を以下のように修正すると正常に変換されます!
(変換前) from keras.layers.normalization import BatchNormalization
(変換後) from keras.layers import BatchNormalization
変換が完了すると以下のようにAIモデルのサマリが出力され、model_dataディレクトリに変換済みのモデルが保存されています。
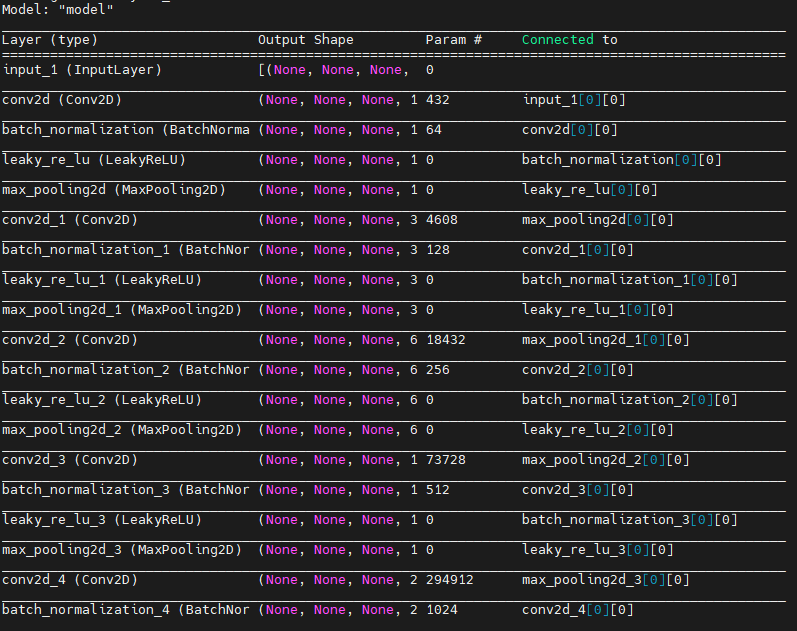
「yolov3-tiny.h5」が変換されたモデルになります。
最後に変換したモデルを量子化に備え、コピーします。
$ cp model_data/yolov3-tiny.h5 ../../quant/ tf2_yolov3_coco_416_416_65.9G_2.5/code/test/floatこれにて変換完了です!お疲れさまでした!
AIモデル 量子化
Vitis AIを用いて、先ほど変換したモデルを量子化します。
Vitis AIのdockerコンテナ上で実行しますが、実行前に以下作業を実施します。
- ①
- 量子化用データセット(coco2017)ダウンロード
- ②
- 量子化用スクリプト修正
① 量子化用データセット(coco2017)ダウンロード
Vitis AIでは量子化を実施するにあたり、ラベルなしの画像データが必要になります。
以下が、量子化のフローになります。
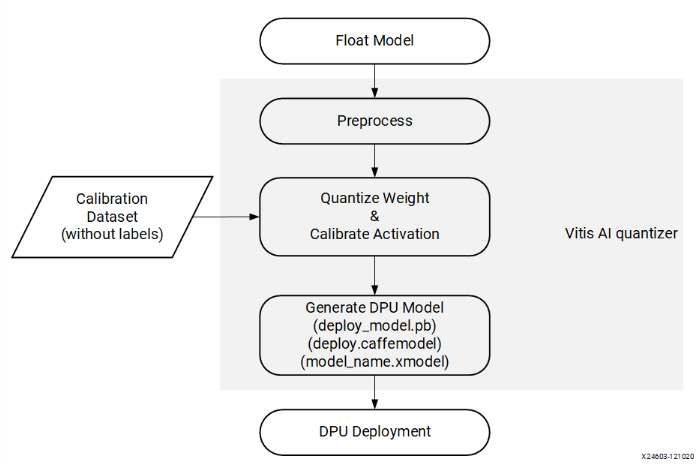
出典:Vitis AI ユーザー ガイド(UG1414)Vitis AI クオンタイザーのフロー
INT8に量子化されたモデルの精度を向上させるために必要となります。
詳細は、Vitis AIユーザーガイド(UG1414)をご参照ください。
こちらは、以下スクリプトを実行することで準備完了となります。
$ bash download_data.sh
$ bash convert_data.sh
- ※
- 実行前に、eval.pyのあるディレクトリにdataディレクトリの作成をお願いします。
② 量子化用スクリプト修正
run_eval.shとeval.pyが実行時に用いられます。

- ※
- run_eval.sh:実行用スクリプト。eval.pyで必要なパラメータ含め記載がある
- ※
- eval.py:量子化定義スクリプト。量子化だけでなく、モデルの評価なども実行可能
Run_eval.shは以下を修正します。
・17行目
(変更前) WEIGHTS=../../float/yolov3.h5
(変更後) WEIGHTS=float/yolov3-tiny.h5
・18行目
(変更前) ANNO_JSON=../../data/annotations/instances_val2017.json
(変更後) ANNO_JSON=data/annotations/instances_val2017.json
・19行目
(変更前) ANNO_FILE=../../data/val2017.txt
(変更後) ANNO_FILE=data/val2017.txt
・20行目
(変更前) ANCHOR=configs/yolo3_anchors.txt
(変更後) ANCHOR=configs/tiny_yolo3_anchors.txt
・25行目
(変更前) python eval.py … --save_result
(変更後) python eval.py … --save_result --quant
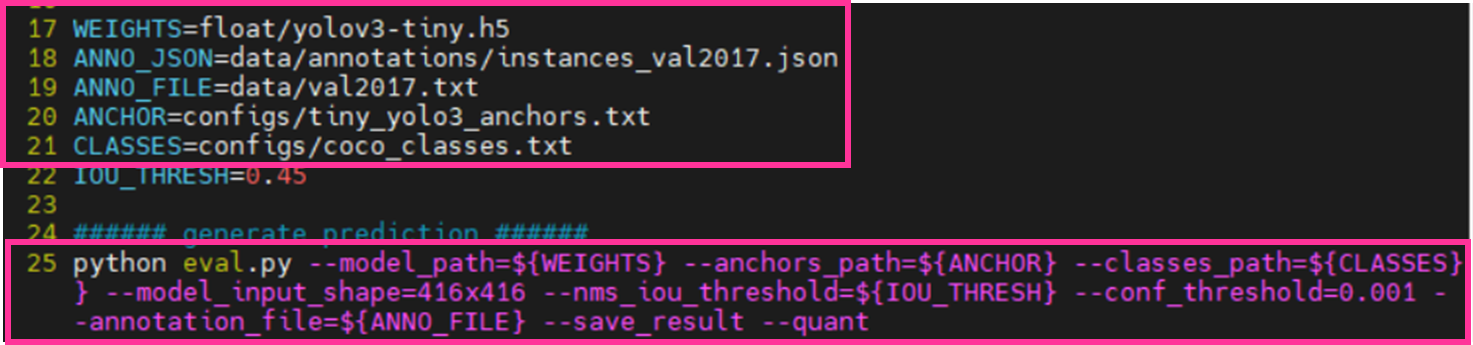
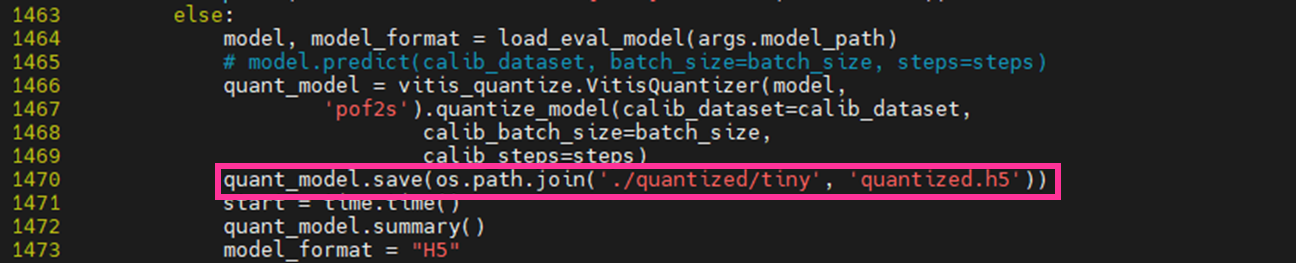
eval.pyは以下を修正します。
・1470行目 ※こちらは保存先を変更するのみなので、名前は任意で構いません。
(変更前) quant_model.save(os.path.join('./quantized', 'quantized.h5'))
(変更後) quant_model.save(os.path.join('./quantized/tiny', 'quantized.h5'))
さあ、ではこれにて準備完了となりましたので、早速量子化を実行していきます!
Vitis AIのdockerイメージを参照し、dockerコンテナを起動します。
$ cd ~/Vitis/vitis_r2.5/Vitis-AI
$ ./docker_run.sh Xilinx/vitis-ai:2.5
- ※
- 筆者環境では、dockerのグループに使用ユーザーを追加しているため、sudoは不要になります。
詳細はこちら!
以下画面が出力されればOKです。 ※少々時間がかかります
以下コマンドで、量子化環境を有効化します。
> conda activate vitis-ai-tensorflow2いよいよ量子化実行に移ります!以下コマンドで実行します。
> cd model_zoo/work/quant/tf2_yolov3_coco_416_416_65.9G_2.5/code/test
> bash ./run_eval.sh
- ※
- 途中、パッケージが足りないメッセージが出力されエラーが出ます。
筆者の場合、”imgaug”と”keras_applications”でした。
その際はpipなどで追加インストールしておきましょう。
正常に完了すると、量子化されたモデルのサマリが出力され、quantizedディレクトリに量子化済みモデル(quantized.h5)が保存されます。

これにて量子化は終了です!お疲れさまでした!
AIモデル コンパイル
量子化したAIモデルをコンパイルしていきます。
評価ボード上で動作させるには、AIモデルにデバイスやIPコアなどの動作環境をinputさせる必要があります。
コンパイルの工程で動作環境をAIモデルにinputさせることが可能です。
実行前に2つ準備します。
- ①
- コンパイル用スクリプトの作成
- ②
- DPU IP情報テキスト(arch.json)の作成
① コンパイル用スクリプトの作成
workディレクトリ直下に、以下を作成します。

- ※
- テキストコピー用として以下添付します。
#!/bin/bash
vai_c_tensorflow2 -m quant/tf2_yolov3_coco_416_416_65.9G_2.5/quantized/tiny/quantized.h5 \
-a arch.json \
-o output/output_B4096_tinyYOLOv3 \
-n tiny_yolov3_coco_416 \
--options "{'mode':'normal','save_kernel':'', 'input_shape':'1,416,416,3'}"
② DPU IP情報テキスト(arch.json)の作成
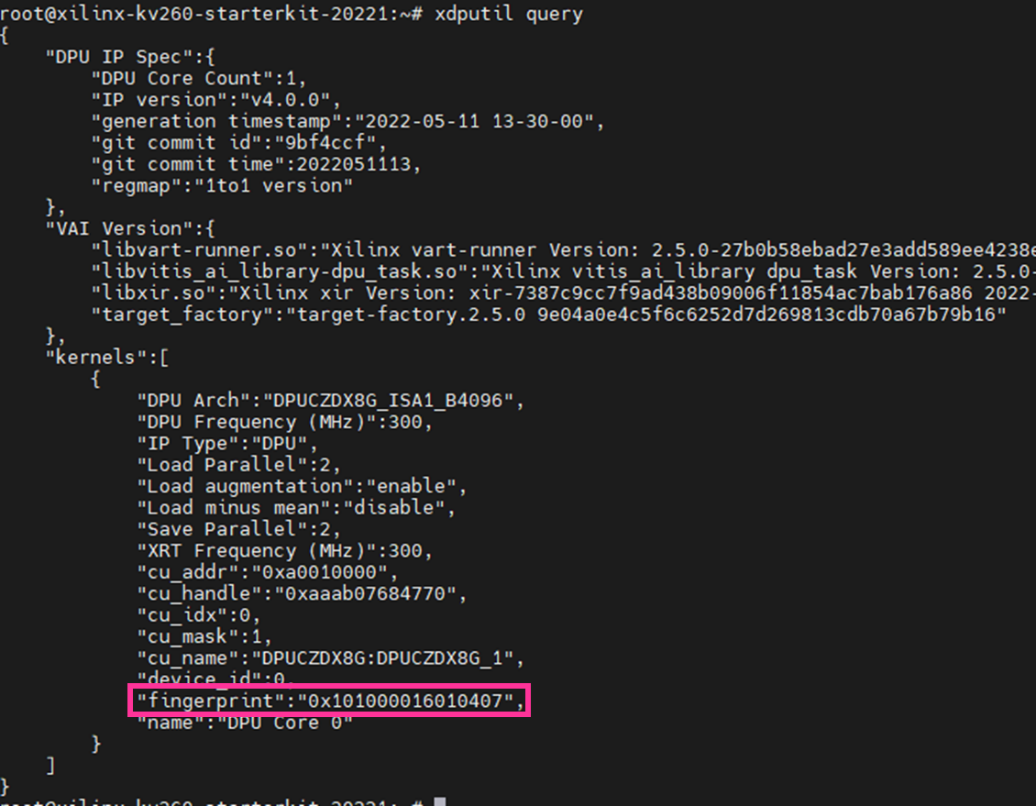
今回は、冒頭にある通り以下のDPUを用います。
コア:DPUCZDX8G_ISA1_B4096_MAX_BG2
コア数:1
こちらと一致している場合、かつ同じリファレンスデザインを用いる場合は、以下をコピーしていただき「arch.json」で保存してください。
{"fingerprint":"0x101000016010407"}異なる場合は、xdputil queryというコマンドを使い、fingerprintの値を確認することが可能です。是非参考にしてみてください。
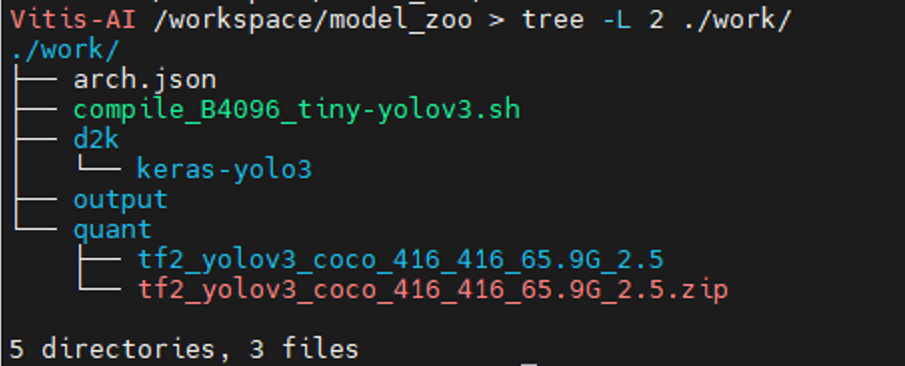
最後にoutputディレクトリを作成して、準備完了です!
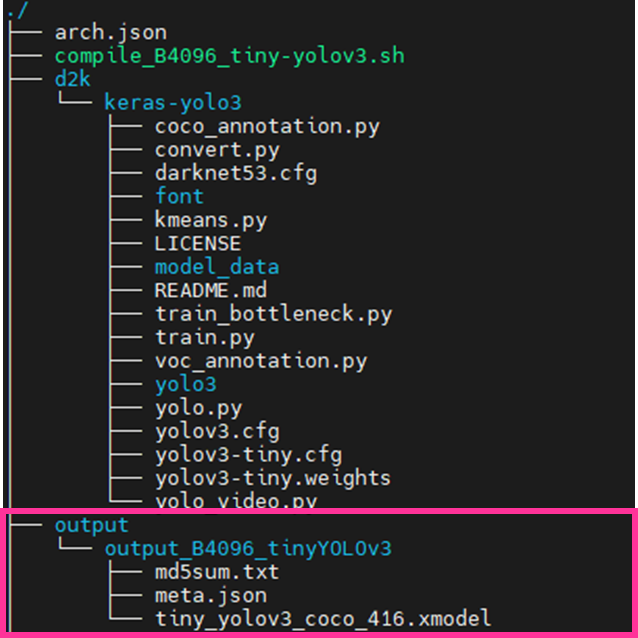
workディレクトリが以下のようになっていれば、OKです!
ではコンパイルを実施していきます!
量子化と同様、dockerを起動し、作業ディレクトリまで行き、コンパイル実行用スクリプトを実行して完了です!
> conda activate vitis-ai-tensorflow2
> cd model_zoo/work
> bash compile_B4096_tiny-yolov3.sh
すると、outputディレクトリにtiny_yolov3_coco_416.xmodelが保存されます。
こちらが量子化/コンパイル済みのTiny YOLOv3モデルになります。
最後に評価ボード上で必要なファイルを1つのフォルダにまとめておきます。
- ・量子化/コンパイル済みAIモデル
-
以下コマンドで実行完了です。
左右にスクロールしてご覧ください$ cd ~/Vitis/vitis_r2.5/Vitis-AI/model_zoo/work $ mkdir output_for_KV260 $ cp -r output/output_B4096_tinyYOLOv3/ output_for_KV260/ - ・Tiny YOLOv3実行用コンフィグレーションファイル
-
YOLOを実行するにあたり、いくつかのパラメータを記載したコンフィグレーションファイルが必要になります。
こちらは、Vitis AIのサンプルにあるものを活用します。左右にスクロールしてご覧ください$ wget https://www.xilinx.com/bin/public/openDownload?filename=yolov3_coco_416_tf2-zcu102_zcu104_kv260-r2.5.0.tar.gz -O yolov3_coco_416_tf2-zcu102_zcu104_kv260-r2.5.0.tar.gz $ tar -xvzf yolov3_coco_416_tf2-zcu102_zcu104_kv260-r2.5.0.tar.gz上記実行するとカレントディレクトリに「yolov3_coco_416_tf2」と「yolov3_coco_416_tf2_acc」が生成されます。
参照はどちらでも構いませんが、そのディレクトリ内に「yolov3_coco_416_tf2.prototxt」があるので、こちらをまとめディレクトリにコピーしておきましょう。
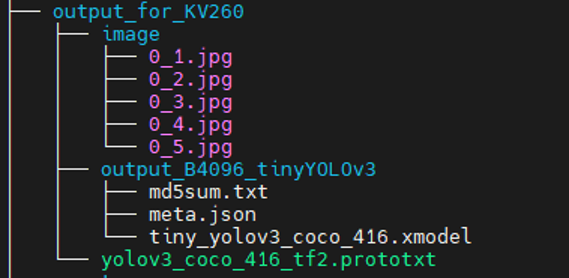
完了し、まとめディレクトリが以下のようになっていればOKです。
その他、推論する際の画像データもまとめて入れておきましょう。
これにてコンパイル終了です!お疲れさまでした!
作業(評価ボード)
KV260起動
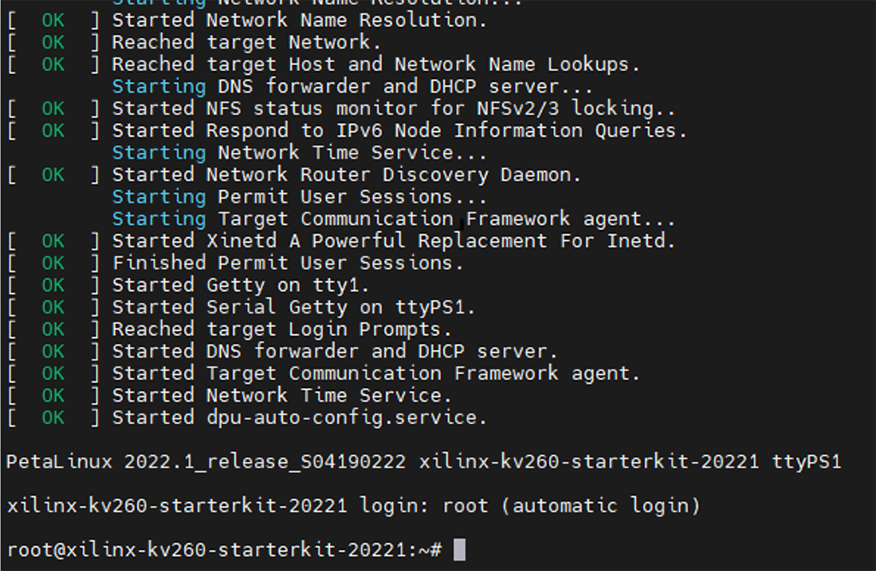
KV260には電源スイッチはなく、SDカードを差し込み電源をつなぐと起動します。
起動後、以下のようになれば正常に起動しています。
Linuxへのログインは自動で行われます。
実行用データ準備
実行にあたり以下を準備していきます。
- ①
- hostPC作業データ移行
- ②
- 推論アプリ作成準備
① hostPC作業データ移行
「AIモデル コンパイル」で整理したディレクトリをKV260上に移行します。
移行方法は様々あるため詳細は省略いたしますが、筆者は、hostPCとKV260を同じネットワークに接続し、scpコマンドを用いて移行しました。
移行の前に、KV260上で作業ディレクトリを作成しておきます。
今回は、Vitis AI Libraryのサンプルにあるyolov3ディレクトリを用います。
https://github.com/Xilinx/Vitis-AI/tree/2.5/examples/Vitis-AI-Library/samples/yolov3
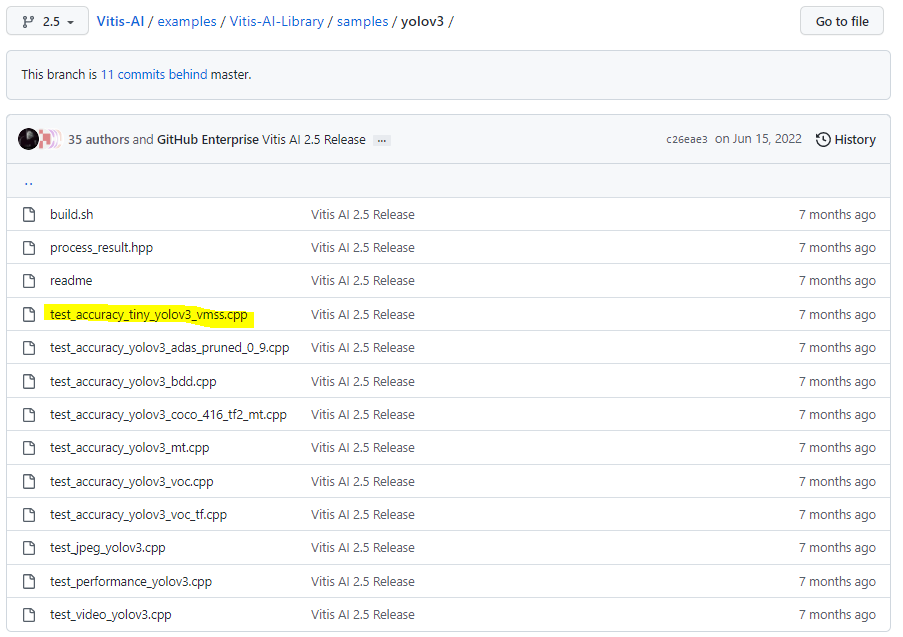
出典:https://github.com/Xilinx/Vitis-AI/tree/2.5/examples/Vitis-AI-Library/samples/yolov3
yolov3ディレクトリには、推論アプリ(cpp)とビルド用スクリプトがあります。
推論アプリについては、上記ハイライトしている”test_accuracy_tiny_yolov3_vmss.cpp”を編集して推論アプリを作成します。
作成については、次項の「②推論アプリ作成準備」でお話します。
作業用として、別名でディレクトリを作成していきましょう。名前は任意で構いません。
- ※
- ちなみにこのVitis Ai Libraryのサンプルはリファレンスデザインの場合、デフォルトで入っています。その他の場合、別途用意する必要があるのでご注意ください。
# cd Vitis-AI/examples/Vitis-AI-Library/samples/
# cp -r yolov3 techblog_yolov3
設定したディレクトリにoutput_for_KV260ディレクトリをコピーして作業完了です。
② 推論アプリ作成準備
推論アプリを作成する前に、不要なファイルなどを移動させます。
用いるファイルは以下の通りです。
・test_accuracy_tiny_yolov3_vmss.cpp
・build.sh
・process_result.hpp
こちら以外はすべて別ディレクトリを作成して一括移動させるなどをしておくことをおすすめします。
以下ファイルをそれぞれ別名で変更し、作業は完了です。
| 変更前 | 変更後 |
|---|---|
| test_accuracy_tiny_yolov3_vmss.cpp | test_tiny_yolov3_coco_416.cpp |
| yolov3_coco_416_tf2.prototxt | tiny_yolov3_coco_416.prototxt |
- ※
- prototxtは、YOLOを実行する際に必要なコンフィグレーションファイルです。
こちらは、output_for_KV260ディレクトリにあります。⇒「AIモデル コンパイル」
①、②を終え、作業ディレクトリが以下のようになれば作業完了です!
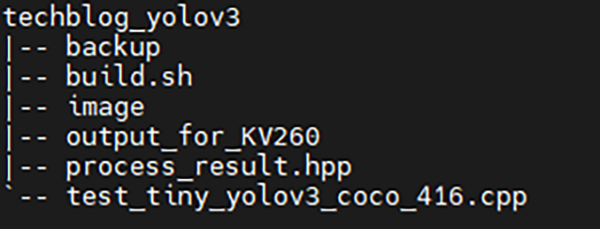
推論アプリ作成
推論アプリと実行に必要なコンフィグレーションファイルの作成を行っていきます。
- ①
- 推論アプリ:test_tiny_yolov3_coco_416.cpp
- ②
- コンフィグレーションファイル:tiny_yolov3_coco_416.prototxt
① 推論アプリ
はじめに、推論アプリの構成を開設します。
72行目からmain関数になりますが、各々の機能を分類すると以下の通りです。
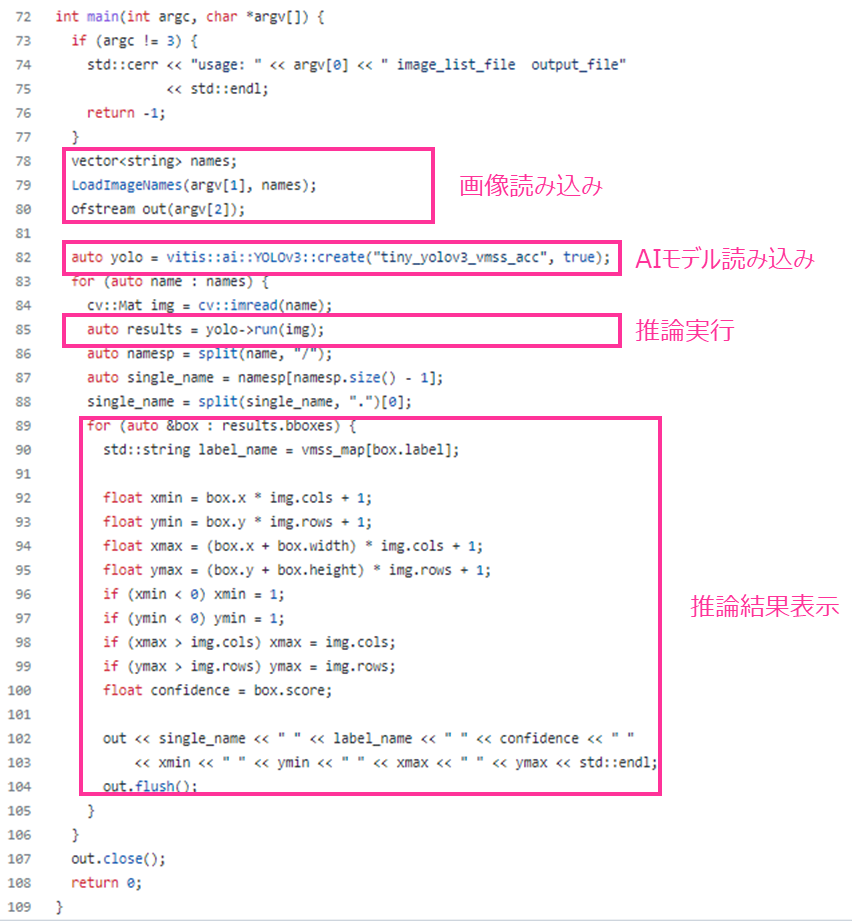
・画像読み込み
50行目に定義している”LoadImageNames”を活用しており、テキストファイルから画像を読み込む流れになっています。
84行目が、AIモデルにinputするための画像読み込み部分で、OpenCVを活用しています。
OpenCVを活用しているので、必要に応じてフィルタ処理など、用途に応じて前処理を追記することが可能です。
・AIモデル読み込み / 推論実行
こちらは、Vitis AIで用意している専用APIになります。
詳細は、ユーザーガイドUG1354に記載があります。

出典:Vitis AI ライブラリ ユーザー ガイド (UG1354)vitis::ai::YOLOv3
vitis::ai::YOLOv3::create()で量子化/コンパイルしたAIモデルを読み込むことが可能になります。
読み込んだのち、run関数で推論実行し、実行結果を得られる形になります。
・推論結果表示
推論結果が構造体として格納されており、推論ラベルと座標、信頼度スコアが結果として得られます。
こちらを活用して、画像にバウンディングボックスを描画したり、mAPを算出したりなど用途に応じて様々な実装が可能になっています。
前処理や後処理は任意で追加いただいて大丈夫ですが、今回の作業で必須で変更する箇所が2箇所あります。
・AIモデル読み込み名変更
今回はcocoデータセットを学習させたAIモデルになるので、以下を変更します。
(変更前) auto yolo = vitis::ai::YOLOv3::create("tiny_yolov3_vmss_acc", true);
(変更後) auto yolo = vitis::ai::YOLOv3::create("tiny_yolov3_coco_416", true);

・推論ラベルの追加
今回はcocoデータセットを学習させたAIモデルになりますので、推論ラベルを追加します。
vmss_mapはコメントアウトし、新たにcoco_80_labelを定義します。
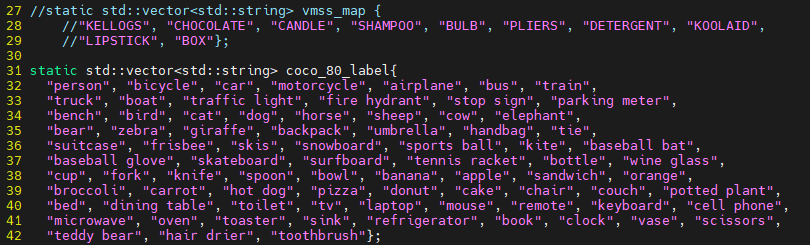
80クラスはとても多いので、以下にコピー用を用意します。是非ご活用ください。
static std::vector<std::string> coco_80_label{
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train",
"truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter",
"bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant",
"bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie",
"suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass",
"cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange",
"broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant",
"bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors",
"teddy bear", "hair drier", "toothbrush"};
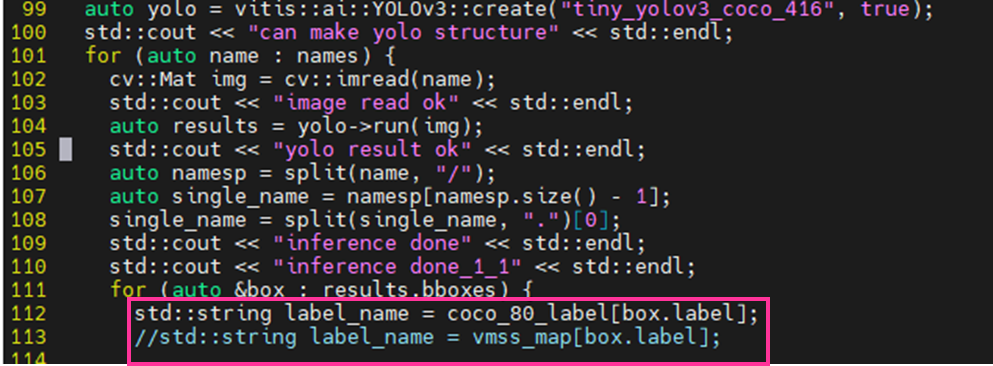
追加に伴い、以下の箇所も修正します。
(変更前) std::string label_name = vmss_map[box.label];
(変更後) std::string label_name = coco_80_label[box.label];
② コンフィグレーションファイル
コンフィグレーションファイルの構成/定義については、ユーザーガイドUG1354に記載があります。

出典:Vitis AI ライブラリ ユーザー ガイド (UG1354)表:YOLOv3 モデルのパラメーター
以下の箇所を変更し、作成完了です。
・name(2行目)
(変更前) tiny_yolov3_vmss
(変更後) tiny_yolov3_coco_416
・name(4行目)
(変更前) tiny_yolov3_vmss_0
(変更後) tiny_yolov3_coco_416
・num_classes
(変更前) 10
(変更後) 80
・layer_name
(変更前) 14, 21
(変更後) 9,12
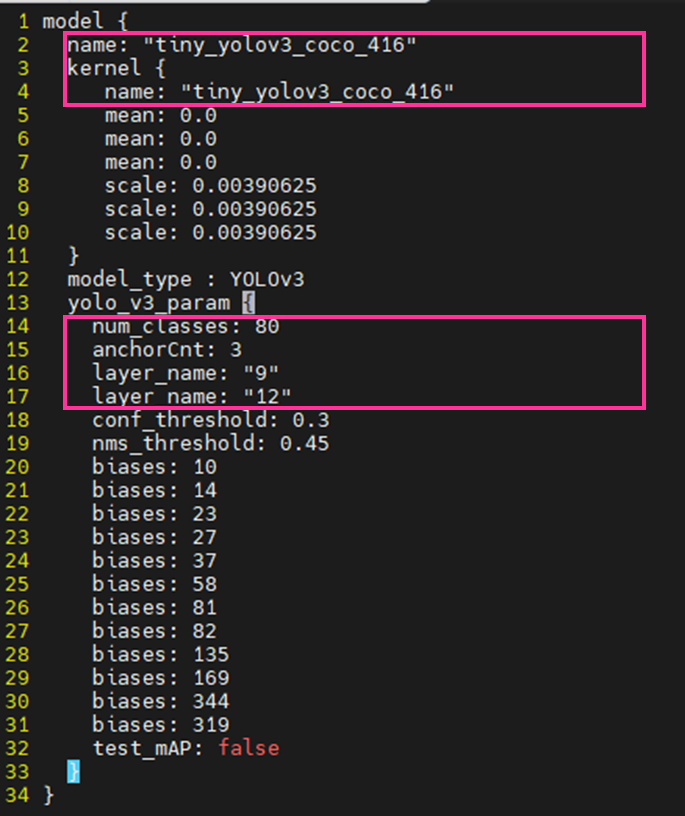
- ※layer_nameについて
-
こちらはnetronというAIモデルを可視化できるアプリを使って確認できます。
Tiny YOLOv3は出力が2つあり、それらをlayer_nameで定義しています。以下がnetronでみた量子化/コンパイルをしたTiny YOLOv3の一部になります。
「fix2float」が最終出力レイヤーになっています。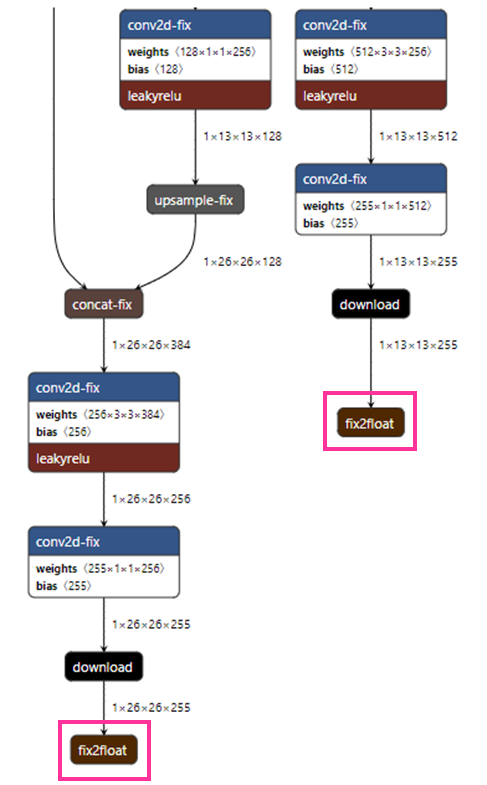
こちらをクリックすると、以下のようになります。
例で右側の「fix2float」をクリックしてみました。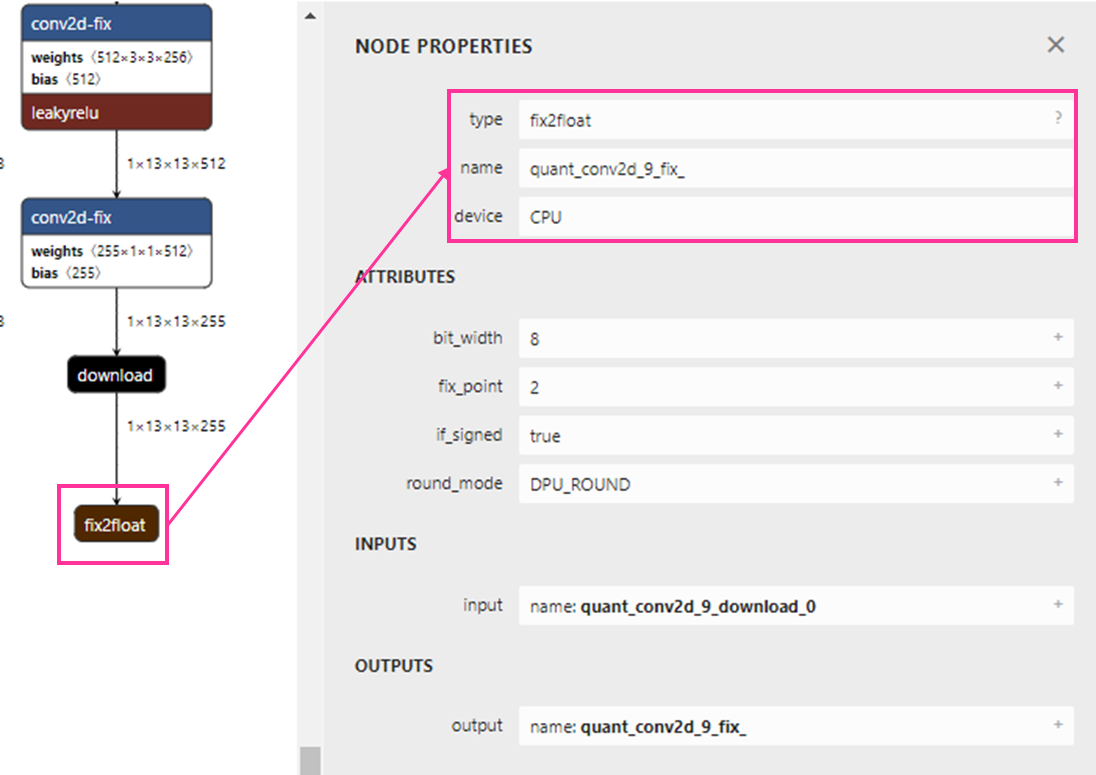
NODE PROPERTIESのnameに注目すると、quant_conv2d_9_fix_とあります。
この9がlayer_nameの数値になります。
※もう一つのfix2floatをクリックすると、12が表示されます。YOLO系でコンフィグレーションファイルを作る際は、netronを活用し、layer_nameを定義してみてください。
これにて作業完了です!
次がいよいよラストの実行になります。
推論実行
いよいよ実行です!
事前準備を3つこなして、実行していきます。
- ①
- 推論アプリビルド
- ②
- AIモデル移行
- ③
- 画像読み込みリスト作成
① 推論アプリビルド
こちらは簡単です。作業ディレクトリ内のbuild.shを実行すれば完了です。
# cd ~/Vitis-AI/examples/Vitis-AI-Library/samples/{作業ディレクトリ名}
# bash build.sh
② AIモデル移行
output_for_KV260にあるAIモデルとコンフィグレーションファイルを指定の位置に移行します。
- ※
- AIモデルが入っているディレクトリは必ず”tiny_yolov3_coco_416”に名前変更してください!
# cd ~/Vitis-AI/examples/Vitis-AI-Library/samples/{作業ディレクトリ名}/output_for_KV260/
# mv output_B4096_tinyYOLOv3 tiny_yolov3_coco_416
# cp -r tiny_yolov3_coco_416 /usr/share/vitis_ai_library/models
# cp tiny_yolov3_coco_416.prototxt /usr/share/vitis_ai_library/models/tiny_yolov3_coco_416
③ 画像読み込みリスト作成
今回の推論アプリは、読み込む画像をリスト化して実行する必要があります。
- ※
- 推論アプリを編集して、その機能をなくすことも可能です。
作業ディレクトリ上に作成すればOKです。
筆者環境では、image_list.txtとし、以下のように記述しました。
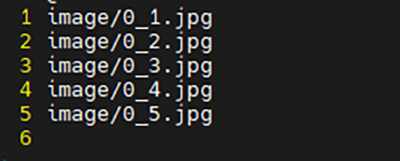
①、②、③を終え、作業ディレクトリがいかのようになればOKです!
さあいよいよ実行です!
ちなみに筆者が後処理にバウンディングボックスを重畳し、画像を保存する機能を追加しました。
# cd ~/Vitis-AI/examples/Vitis-AI-Library/samples/{作業ディレクトリ名}
# ./test_tiny_yolov3_coco_416 image_list.txt result.txt
実行してみると、resultディレクトリが生成され、人と認識しバウンディングボックスが囲まれていました。
色を分けていなかったのですが、下記画像では、人を2箇所、グローブを1箇所で認識しています。
色を分ける場合は、別途ラベルのように定義して、OpenCVの長方形を描画するAPIの引数に反映させると分けることが可能です。

予めcocoデータセットを学習させているので、精度も問題ないですね!
量子化してもこの精度を保てるのはとても特徴的だと思います。
FPSも算出してみました。提供しているツールの中で、シミュレーションで測定できるコマンドがあります。
以下を試すと算出できます!
# cd /usr/share/vitis_ai_library/models/tiny_yolov3_coco_416
# xdputil benchmark xdputil benchmark tiny_yolov3_coco_416.xmodel -i -1 5
試すと以下のように出てきます。
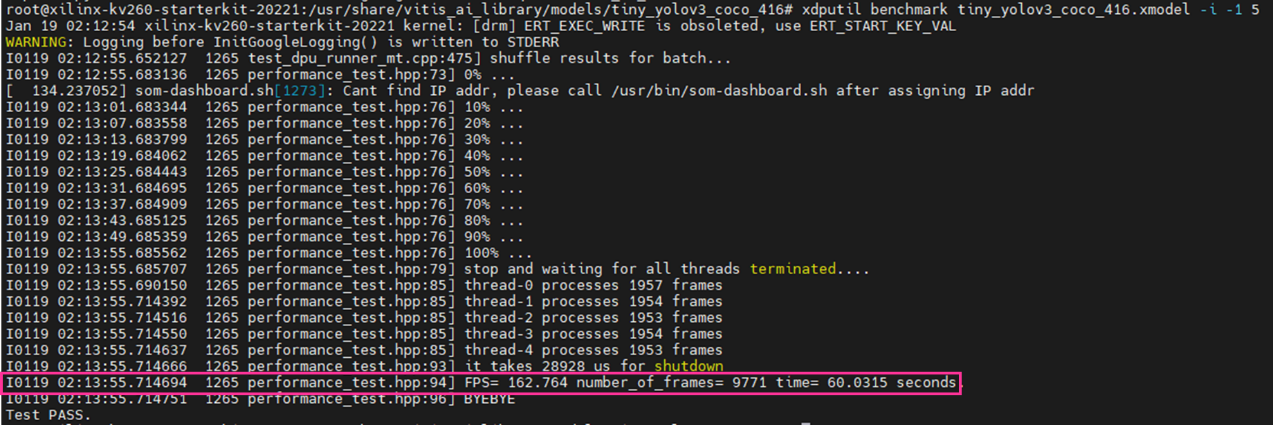
「FPS=162.764 number_of_frames=9771 time=60.0315 seconds」
こちらの時間は、一定時間DPU演算処理をさせた際のFPSが出力されます。
前処理や後処理などの時間は含まれない値になります。
- ※
- 厳密にいうと少し異なります。だとしても、160FPS以上出るのは驚きですね。。。
使用コマンドについては、こちらに詳細がありますので、ご確認ください。
AMD ザイリンクス社でも各AIモデルやデバイスごとにベンチマークを公開しています。
その他気になるAIモデルなどあれば、チェックしてみてください!
おわりに
最後まで閲覧いただきありがとうございました!
今回はオープンソースのTiny YOLOv3を変換、アプリ作成してKV260上で動作させてみました。
アプリ作成の場合、様々な専用APIもありますし、OpenCVといったライブラリも活用することが可能です。
必要に応じてライブラリを追加することも可能ですので、カスタマイズの幅が広がりそうです。
今回C++で試しましたが、Pythonでも動作します。
次回はPythonでもやってみようかなーとフワッと考えています。
それではまた!TEPPE-AIでした~



















