FPGAコンピューティング プラットフォーム「M-KUBOS」のアプリケーション例

目次
多種リアルタイム・アプリケーションを実現するハードウェア構成
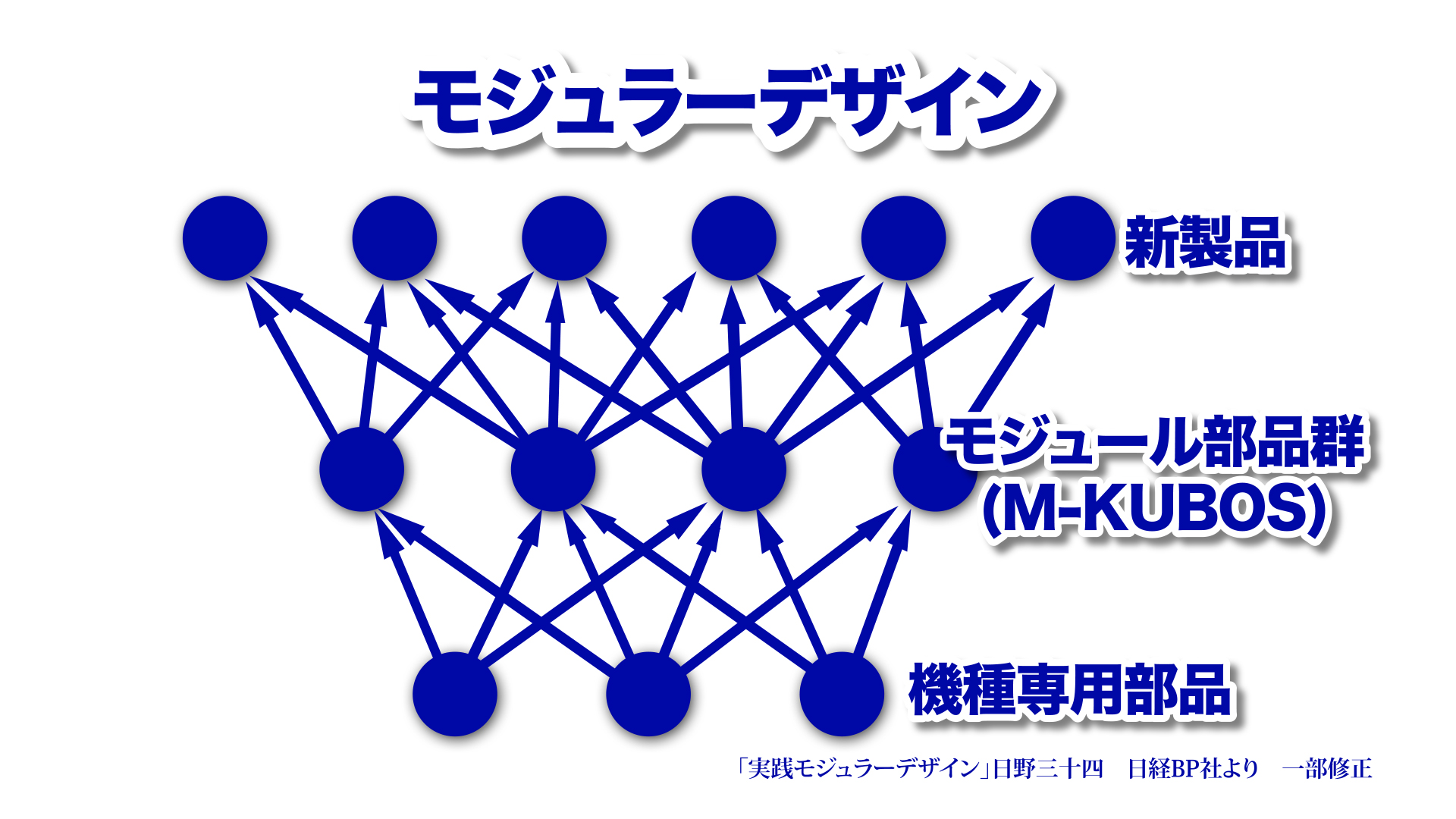
第2回でモジュラーデザインについて説明しましたが、PALTEKではすでに「共通部品」を数多く用意しており、これらやお客様固有のインターフェースを組み合わせることにより迅速なPoC(Proof of Concept)やマス・カスタマイゼーションが可能になります。
こちらがPALTEKで開発した3つの基板の仕様です。
DATABRICKはPCI-Expressカードエッジ型のFPGA基板で、搭載デバイスは Virtex® UltraScale+™ のXCVU3Pです。 PCI-Expressは3rd Generation×16をサポートしており、拡張コネクタとしてFMCコネクタを2個、FireFly™コネクタを4個実装しています。 FireFly™コネクタには最大25Gbps通信の高速トランシーバーGTYが8レーン×2 合計16レーン接続されています。
( DATABRICKの詳細はWEBサイトにてご確認ください。)
Image CUBE2 は4K/8K映像処理を可能とするよう設計されたFPGA基板で、搭載デバイスはKintex® UltraScale™のXCKU115です。
搭載メモリは6Gbyteで8K 60fpsの映像をメモリに保存して高速処理することができます。8K映像を入出力するための12G-SDIサブ基板は既に開発済みです。
拡張コネクタとしてFireFly™コネクタを10個実装しています。
FireFly™コネクタには最大16Gbps通信の高速トランシーバーGTHが12レーン×3と8レーン×2の合計52レーン接続されています。(Image CUBE2の詳細はWEBサイトにてご確認ください。)
※Image CUBE 2 は現在取扱いを終了しています。
M-KUBOSはこれまで紹介してきた通り、MPSoC搭載基板です。
搭載デバイスはZynq® UltraScale+™ XCZU19EGです。ARMコアA-53とR-5が内蔵されておりUSB3.0、ギガビットイーサポート、U-ART、CANポート、DiplayPort1.2等の汎用コネクタが実装されています。また、QSFP28の光モジュールを実装することも可能です。
拡張コネクタとしてFMCコネクタ2個、FireFly™コネクタ12個、あらたにPmodコネクタが追加されています。
FireFly™コネクタに接続される高速トランシーバーは最大25Gbps通信のGTYが4レーン×4の16レーン、最大16Gbps通信のGTHが8レーン×4の32レーンです。
PALTEKのFPGA/SoCボードは全てFireFly™コネクタで繋げることができます。
基板間は100Gbps以上の速度で通信を行うことができ、さらにボード複数枚を数珠繋ぎすることで大規模でリアルタイム性を求められるアプリケーションに対応することが可能です。
ザイリンクス社が提供しているAlveo™アクセラレータカードとの接続
Xilinx製Alveoアクセラレータカード
ザイリンクス社製Alveo™ アクセラレータ カードにはFPGAが内蔵されています。 GPUよりも低消費電力でFPGAの特徴である機能の書き換えにより、必要に応じた処理システムを構築できます。
またPCI-Express Gen3×16 Gen4×8をサポート、QSFP28による100Gbps光通信が可能です。
DDR4メモリの約10倍高速なメモリHBM2を搭載している製品もあり、そのメモリ帯域幅を活かしたM-KUBOSとの高速連携を利用することも可能になります。
リファレンスデザインとして、M-KUBOSに画像系やネットワーク系の外部インターフェースとの接続、x86系サーバーとの接続、M-KUBOSとAlveo™ U50の接続を可能にするものを用意しています。
Alveo™ U50には、新型のDRAM「HBM2」が実装されており、公称帯域幅は201GByte/secで、DDR4-2133の10倍の能力があります。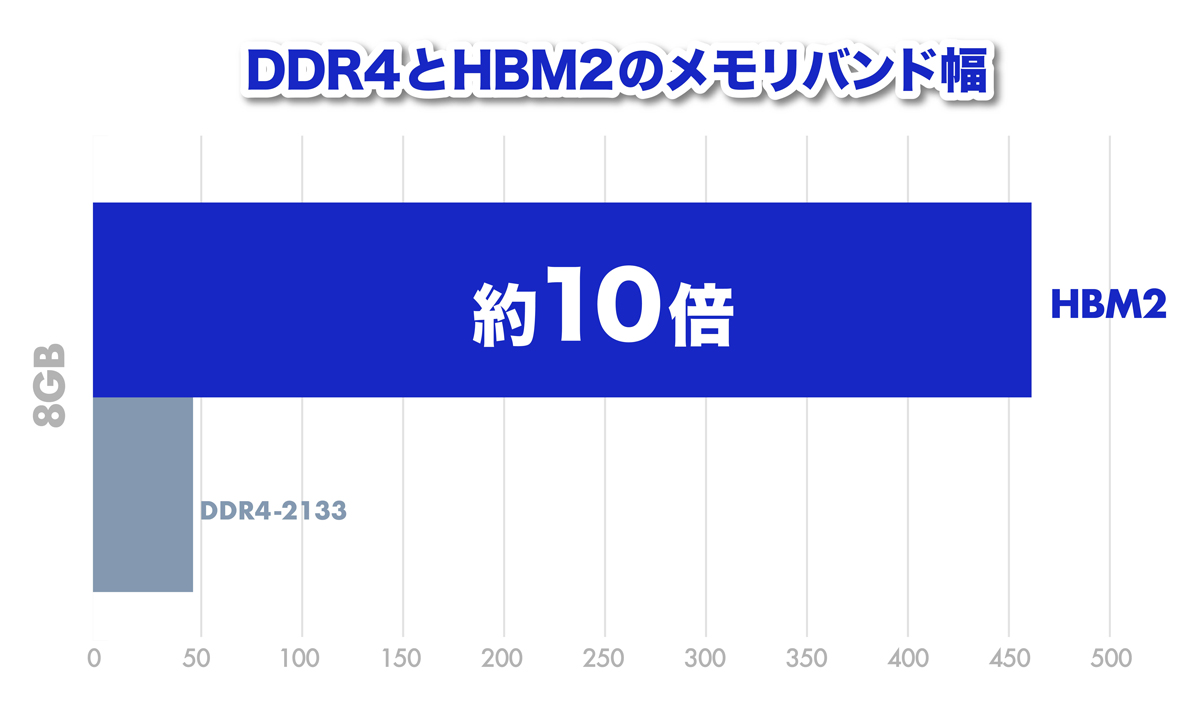
このAlveo™ U50を4機接続することにより、演算に利用可能な圧倒的なメモリバンド幅を確保できます。「HBM2」は内部の内部構造は「多ポートDRAM」の構造をしており、画像処理や並列演算を実現するために最適な構造となっています。
Alveo™ U50内部の「HBM2」を共有メモリとした並列演算器としての構造は、CPU、GPUでは実現困難な「超低レイテンシ」を可能とします。Alveo™ U50を4並列することでDDR4の40倍のメモリバンド幅が実現でき、今まで不可能だったアプリケーションへの実装が可能となります。
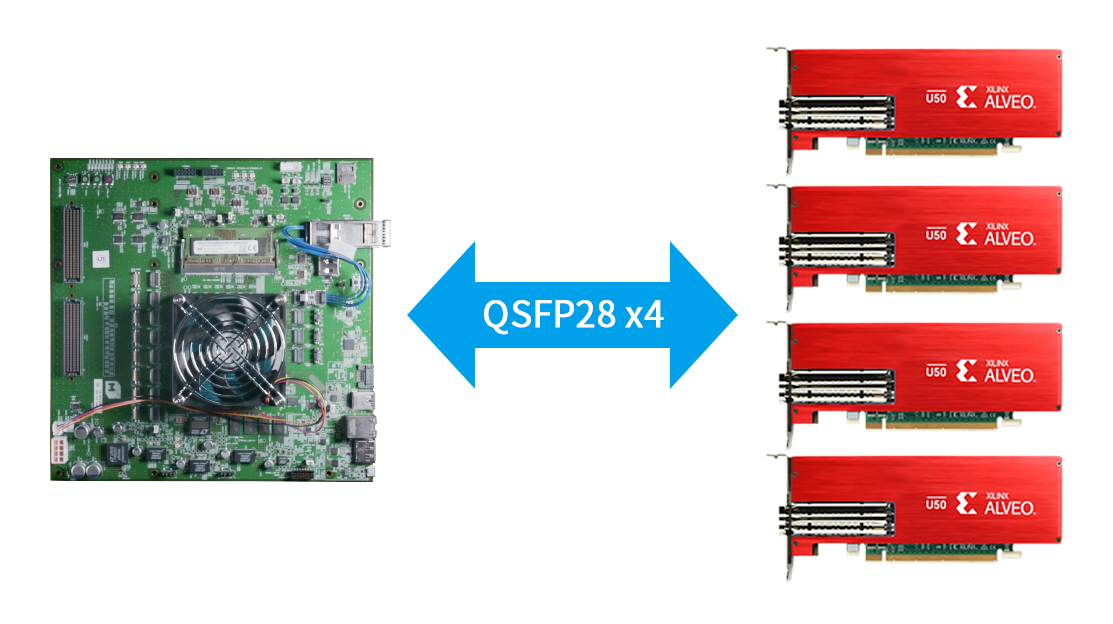
写真3:M-KUBOSとAlveo™ U50の接続

写真4:M-KUBOSとAlveo™ U50の光ケーブル接続例
開発に関しては、主にデータセンター向けに作られたVitis™統合ソフトウェア プラットフォームでの高位合成フローと、従来通りのVivado® Design Suite HLx Editionでの開発の二通りがあります。 今回は最高性能を実現するためにVivado® Design Suite HLx Editionにおいて、 M-KUBOSとAlveo™ U50の28Gbps光モジュールを使用したリファレンスデザインを用意しています。
前回説明したとおり( TECHブログ:FPGAコンピューティングプラットフォーム「M-KUBOS」基本セットとPYNQ™)、M-KUBOSでは12G/6G-SDI、DP1.4、QSFP28の各種規格に対応しております。これらをAlveo™ アクセラレータ カードと組み合わせることにより、さまざまなコンピューティング環境を実現することができます。
以上のように、多種かつ大量の画像インターフェースを、M-KUBOSとAlveo™の組み合わせで実現可能になります。

写真5:M-KUBOSとAlveo™ U50を使った画像処理システムのイメージ
画像処理アプリケーションにおけるリファレンスデザインの実用性
画像処理アプリケーションは、毎フレーム処理が求められる「リアルタイム処理」が基本です。
毎フレームの処理を実現するためには、4Kの場合では、
1秒間の画像データ = 3,840画素 x 2,160画素 x 2Byte(4:2:2) x 60Hz
= 8,294,400画素 x 2Byte x 60Hz
= 16,588,800画素 x 60Hz
= 995,328,000Byte /Sec
≒ 1GByte/Sec
で処理する必要があります。
4Kの画像を受け取るために、1GByte/Secが必要になり、同様に映像出力にも1GByte/Secが必要です。実際の映像データにはブランキング期間がありますが、メモリには格納しませんので上記の計算には含めていません。また、60Hzの映像コンテツはほとんどなく、実際は59.94Hzです。ここでは計算の簡略化のために60Hzのままで進めます。
対するDDR4は、64Bit幅、2133Mbps、効率90%換算で計算すると、次のようなバンド幅性能があります。
DDR4-2133 = 2,133Mbps x 64Bit幅 x 0.9
= 136,512Mbps x 0.9
= 17,064MByte/Sec x 0.9
= 15,357.6MByte/Sec
≒ 15GByte/Sec
つまり、4K画像15回分の入出力性能があることが分かります。
最近のカメラ映像は4K30Hz(6G-SDI相当)が多いので、カメラ映像を直接処理する場合は、倍の余裕があると考えられますが、ここでは60Hzで計算しました。
処理を遂行するために、15回分の帯域から既に入出力で2回分が差し引かれ、残りは13回分になります。
なにかしらのラスター方式の画像処理を行うと、2回分ずつ差し引かれ、フレーム間の差分をとるなどの処理では、3回分差し引かれます。レンズ補間処理は、ほぼすべてのメモリバンド幅を使い切ります。また、複数の映像入力をDRAMに格納すれば、倍々でメモリバンド幅を使います。
画像処理アプリケーション開発の最大の悩みは「検証」です。
1画面分のシミュレーションを実行することもありますが、60Hzならば16ms、30Hzならば33msもの時間をシミュレーションしなければなりません。回路規模にもよりますが、一晩かかることも当たり前の状況です。もちろん、論理合成時間も数時間単位で必要です。
そのような問題を抱えている画像処理アプリケーションの開発について、M-KUBOSで開発する場合にSDI入出力を例に説明します。
図1:SDI入出力を持つデザインの典型例
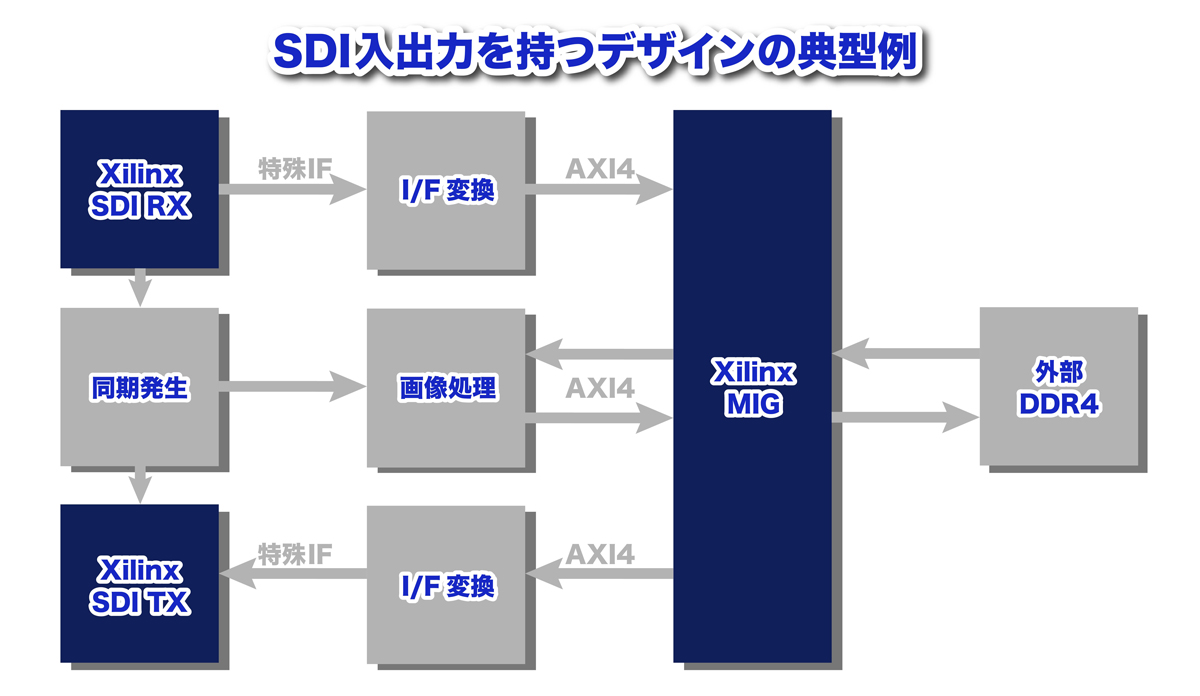
図1で「Xilinx」と書かれているのは、ザイリンクス社が提供しているIPです。 SDIやMIGについては、Vivado® Design Suite HLx Editionの契約をしているユーザーでしたらどなたでも無償で使用可能ですが、その他の部分については新規作成をするか、購入する必要があります。
また、ザイリンクス社のSDIのインターフェースは独特の構造をしており、その意味などを理解する時間を考えると工数が追加されます。
また外部のDDR4へのWrite/Read動作はAXI4でのアクセスとなり、インターフェース変換が必須で、さらに工数が増えます。
多くの有用なザイリンクス社のIPが利用できますが、ベンダーから提供されているリファレンスデザインは汎用的ではありますが、目的とする開発物にあと一歩及ばないことが多々あります。
そこで、画像処理開発にすぐに着手できるように、M-KUBOSでは基本セットとは別に専用のリファレンスデザインを用意しています。
図2:M-KUBOSでSDIを含むリファレンスデザイン
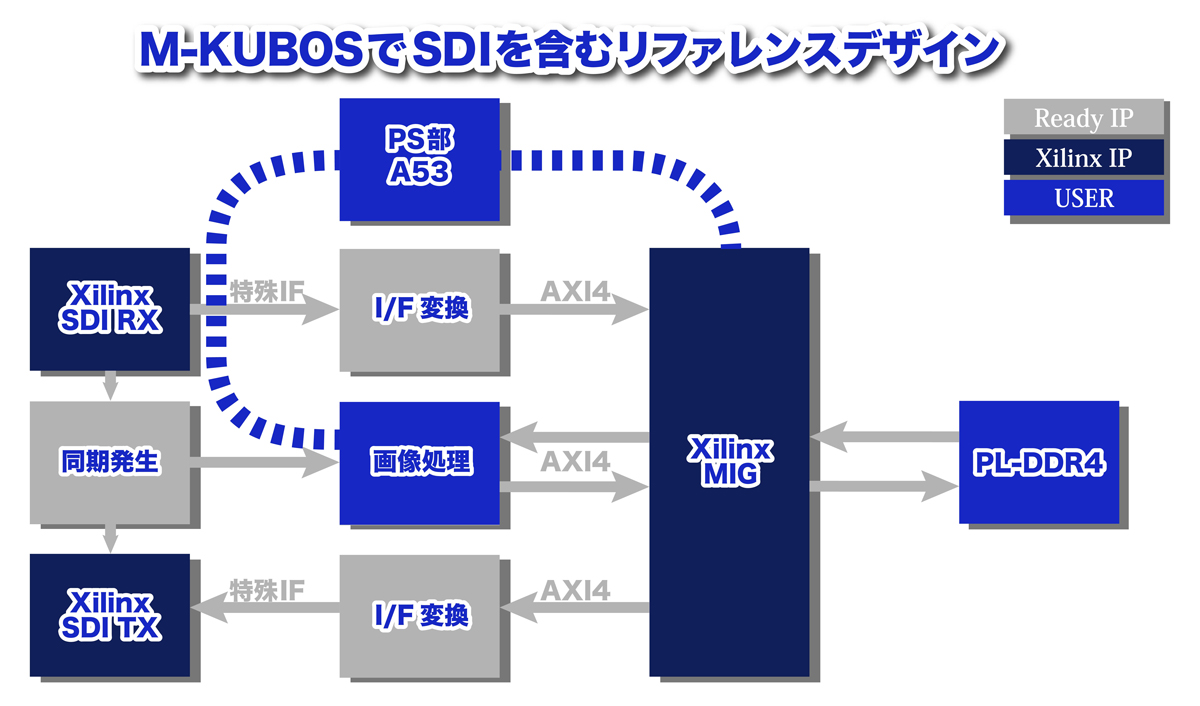
このリファレンスデザインは、画像処理、Arm A53等による制御を除く部分になります。
SDIの映像ストリーム(図中では特殊IF)をAXI4に変換するのは、腕に自身のあるユーザーであれば特に問題はありませんが、やはり工数が必要で技量とセンスが問われる部分です。
同期発生も長い検証時間が必要ですが、映像の入出力が検証済みであれば、処理が間違っていても処理途中の映像がDRAMから出力され、状況が一目で分かります。
またひと工夫すれば、PL-DDR4からPS-DDR4へ転送して、別の角度での映像データ確認もできます。
そして、シミュレーション作業も、新規開発部分だけを行えば工数も大幅に削減することができます。もちろん、要件をお伝えいただければ、デザインの変更も承ります。
まとめ
いかがでしでしょうか?
このようにハードウェアならびにリファレンスデザインを組み合わせて8K映像処理装置を組み立てることも可能です。8K映像のリアルタイム画像処理や8K映像のAI処理など想像が膨らみますね。
次回はいよいよ最終回 、 M-KUBOSでの試作と量産についてです。
M-KUBOSについて、ご興味のある方はぜひともお問い合わせください。
また、今回の記事に関する説明動画をご用意していますので、ぜひともご覧ください。




