機能検証への機械学習適用についての考察(Design and Verification LANDSCAPE 2023-Vol3)

目次
はじめに
機械学習はさまざまな分野で活用されており、FPGAやASIC/SoC開発においても機械学習適用の研究が進み、事例が論文として多くの学会やカンファレンスで共有されている。機械学習の効果は学習するデータ量に左右されるが、もともとFPGAやASIC/SoC開発は、ツールが生成するデータ量は膨大であり、機械学習の適用による開発効率の向上が期待される分野である。特に開発プロジェクト期間の70%以上を占める機能検証における機械学習への期待は大きい。本稿では機械学習によって、機能検証フローに含まれるどのようなタスクが適していて、どのような利点や自動化が期待されるのか、また適用に際して考慮すべき課題や問題点なども含めて考察する。
機能検証フローにおける膨大なデータ
機能検証フローでは、さまざまな種類の膨大なデータが存在する。データには人がマニュアル作成するものもあれば、過去のプロジェクトから流用するもの、ツールが生成するデータや中間データなどがある。またデータフォーマットとしてもテキストデータ以外にグラフデータ、テーブルデータ、リレーショナルデータなどさまざまな種類が存在する。参考までに表1.にシミュレーション、フォーマル検証、デバッグに関連するデータを列挙する。もちろん、開発プロジェクトによってはこれ以外にエミュレータやFPGAプロトタイピング、CDC/RDC検証、低消費電力設計の検証、セキュリティ保全の検証や機能安全標準への準拠、ソフトウェアとの協調検証などが必要になる場合もあり、さらにより多くのデータを要する、データを出力するプロセスが存在することになる。
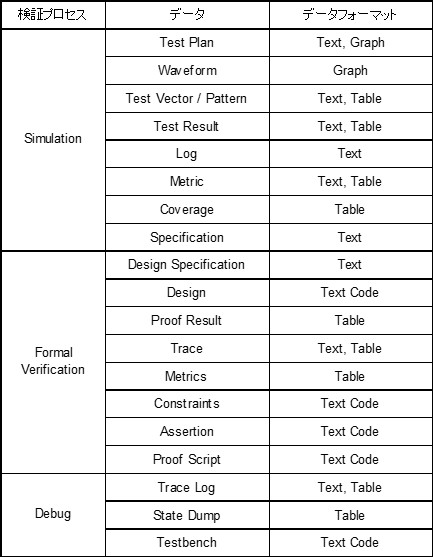
表1. 機能検証プロセスで扱われるデータとデータフォーマット
それぞれのデータには版数、作成者のアカウント名、最終編集や最終使用のタイムスタンプ、データサイズなども併せて存在する。
機械学習適用対象としての機能検証
ここで機能検証プロセスが機械学習の対象として適切かどうかについて検討する。機械学習を適用する際に重要な要素は以下の3つの点である。
問題の定式化の可否
解決すべき問題に対して入力と出力が明確に定義されていること
基本解の存在
何らかの手法、例えばマニュアル作業やルールベースなどによって基本的な解へと導くことができること
データの可用性
ワークフローにおいて作成するデータや生成されるデータへのアクセスが可能なこと
上記3点について考察する。1.の問題の定式化については、機能検証において解決すべき問題が何かは非常に明確である。バグを特定し修正すること、修正したバグが他に影響していないことの確認、カバレッジを上げ目標を達成することなどが挙げられる。2.として機能検証には基本的な解が存在している。UVM環境においてテストスティミュラスを生成しカバレッジを取得する、仕様書に従って記述した機能カバレッジを収集する、Pythonスクリプトによってプロセスを自動化するなどして、すでに機能検証を実現している。機械学習を活用し利点を示すためには、対比するベースラインが必要であるが、それはすでに存在していることになる。3.に示すデータの可用性については前出のとおり、機能検証においては膨大なデータを得ることができる。ただし機能検証プロセスでは、ほとんどのデータはその場で廃棄されてしまうことが多い。
例えばリグレッションテストにおいて長時間のシミュレーションを並列に30本実行していたとしても、注目するべきは新たなアサーションフェイルが発生していないこと、スコアボードで問題なく期待値照合ができていること、収集した30本分のカバレッジデータをマージし、トータルカバレッジを知ること、カバレッジ収集におけるテストランキングを取得することのみが興味対象であり、すべてのシミュレーションのログやUVMメッセージ、アサーションの含意演算子の左辺のヒット数やアサーションパスの回数などは捨てられてしまう。機械学習をどのように適用するかによっては、従来は捨てられていたデータに伏在する価値についても目を向ける必要がある。
ここまで議論してきたように、総じて上記3つの重要な要素はクリアしており、このことから機能検証は機械学習を適用する価値が充分に高い分野であると言える。
機械学習適用が議論されている検証タスク
DVCon、ICCAD、DACなど、機能検証が深く議論されるカンファレンスでは、多くの論文が投稿、発表されており、特に近年の論文には機能検証への機械学習適用を扱ったものも多く、機能検証フローの隅々に至るまで網羅されていると言っても過言ではない。世界中の多くの人があらゆる可能性について検討、挑戦していることが伺える。その中でも非常に多く議論されているのが、以下の6つのタスクである。
上記6つのタスクについて、どのように機械学習が活用され得るのか、あるいは活用が期待されているのかについて、以下に順番に解説する。
1. Requirement Engineering
最初はRequirement Engineeringである。基本的には自然言語で表現された要件を受け、そこからツールが解釈できるコードへと翻訳する際のエンジニアリングである。
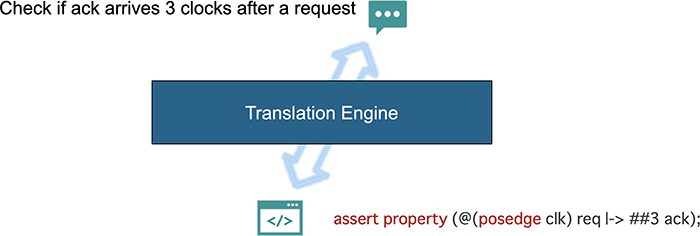
図1. 要件のエンジニアリング
ここにあるように「Check if ack arrives 3 clocks after a request」という英語 – つまり自然言語による要件を受けて、翻訳エンジンがシミュレーションやフォーマル検証のツールが解釈できるアサーションに翻訳するというタスクである。このようなタスクはすでに多くの人が活用しているものの、注意すべき点は、自然言語とは言ってもかなり制約のある自然言語で表現しなくてはならないということである。基本的には自然言語のサブセットに限定することで機械翻訳の負荷を低減する。その反面、サブセットとなる限定された語彙を人々が学ばなくてはいけないというペナルティもある。多くの論文で示されているのはトレーニングに使われた数百のプレミアムデータに限定されている。幸い、生成系AIのように膨大な言語モデルを活用することで、この語彙の限定をはずし、より一般的な自然言語をも翻訳できる可能性が見えている。それでもなお、翻訳の結果の正当性を、誰かが確認する必要性は残されている。
2. Static Analysis
2つ目はStatic Analysisで、基本的には機械学習を用いた静的コード解析である。ベストプラクティスに従わずに適切ではないコードを書いてしまうことがあり、場合によってはそれが反復されてしまう。そこで機械学習を使ってコードスメルを行う。コードスメルは、もともとソフトウェア開発で使われる言葉で、ソースコード中に深刻な問題が存在することを示す、何かしらの兆候を検出しようとすることである。深刻な問題は、それまでの行程に関するものであるかも知れないし、その後の行程に関する場合もある。もちろんハードウェア開発におけるコードスメルの対象はRTL記述やテストシナリオである。
図2.にあるように、機械学習を用いたコードスメルの結果を、機械学習のリファクタリング・エンジンによってコードをリファクタリングし、長いコードをモジュール化することで管理しやすいものに置き換えることができる。リファクタリングの目的は、管理容易化によって検証の質を向上させることである。大規模な言語モデルを構築することで、この作業を自動化できる可能性があり、コーディング上のアシスト的な機能実現が期待される。
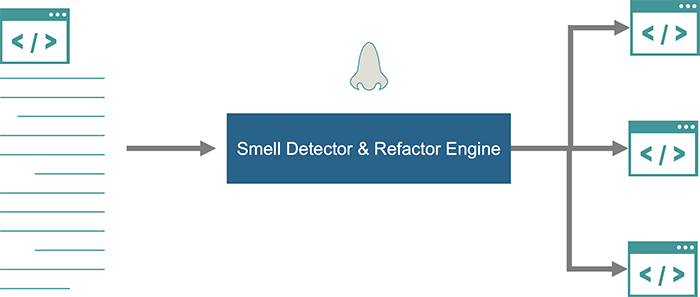
図2. コードスメルとコードリファクタリング
静的コード解析に関する興味深いタスクとして、図3.に示すようなコード要約、コード生成、セマンティクス検索を可能にする研究が進んでいる。
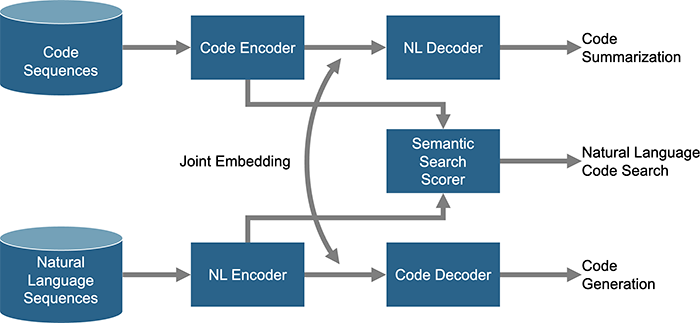
図3. コード要約/コード生成/セマンティックス検索
基本的な考え方は、コードと自然言語の間にあるベクトル空間への相互埋め込み – Joint Embeddingを行い、最終的には個別にデコードする。コードシーケンスに対してデコードすると、コードのサマライズを生成することができる。誰かが作成したコードを受け継いだり検討する際に、コードを読む代わりにコードの要約を見ることで概要が把握できたり、ドキュメント作成への応用も期待できる。PythonやJAVAなどの言語ではすでに成果が出ている例もある。ただしハードウェア設計の分野では、並列性やテンポラルな記述があるため、他のソフトウェア言語では経験したことのない課題が存在することも確かである。コード生成についても研究が進んでおり、機械学習でコードを生成し、設計者の生産性向上に役立てることが期待できる。さらにセマンティクス検索では単にコード内のラベルやタスク名、モジュール名などで検索するのではなく、よりセマンティクスに近い検索が可能になる。例えば、転送モード時にメモリにアクセスしているリソースを見つけたい、といった検索が期待できる。
3. Simulation Acceleration
3つ目はSimulation Accelerationで、文字通りシミュレーションの高速化を目的として機械学習を適用しようとするものであり、多くの研究がなされている。非常に複雑な設計において、多くの演算を順番に実行しなければならないような場合に、機械学習を用いてICチップの挙動を近似的に再現させようという適用方法である。計算実行ユニットを増やすことで機械学習も高速化することが可能である。
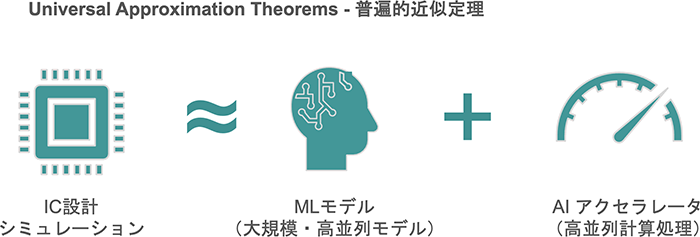
図4. 近似モデルと高並列計算によるシミュレーションの加速
研究ではFeed Forward ANNと呼ばれるネットワークで、どのような連続関数であっても機械学習によって任意の精度で近似化することが可能とされている。完璧な精度を求めるのであれば、高い並列性をもった計算機資源が必要になるが、ICシミュレーションと許容される適切な精度の機械学習モデルをうまく組合せられる可能性もあり、機能検証における機械学習適用では本丸的な分野と言える。
4. Coverage Closure
4つ目はCoverage Closureに関する適用である。シシミュレーションではディレクテッドテストに加え、ランダムテスト生成やグラフベースの自動化などの手法が用いられるが、カバレッジ・クロージャはそもそも膨大な時間を要するプロセスであり、わずかな効率改善でも全体のタスクに要する時間を大幅に短縮できる可能性がある。
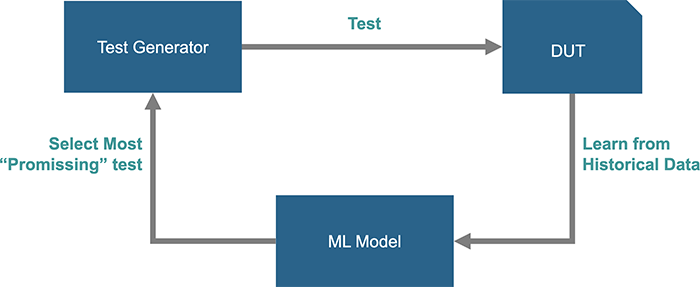
図5. 機械学習によるテスト生成とカバレッジクロージャ
多くの研究ではブラックボックスモデルのアプローチが採用されており、DUTは入力から制御可能性があり、出力での観測可能性ができるという仮定に基づいている。研究によってはいくつかのテストポイントを観測する手法もとられている。他にもcoverpointごとに学習モデルを定義する、あるいは破棄するテストと学習用テストに分類するなど、さまざまなアプローチが研究されている。基本的にはDUTの挙動を理解しようとはしていない。そして過去データから学び将来のテストを作成するよりも、過去から学び不要なテストを減らすことに焦点が当てられている。また研究によってはDUTの挙動は理解しないものの、DUTに対して大規模な言語モデルを用いて設計コードを探索し、コードをリファクタリングして大きな制御グラフとデータフローのグラフによるネットワークを作成することで制御性や観測性を高めるアプローチを併用することも行われている。
5. Bug Detection / Debug
5つ目はBug Detection / Debugであり、非常に重要なトピックである。というのは、検証に費やされる時間の半分近くがデバッグに費やされることが分かっているからである。そこでデバッグの効率を高め、バグの特定を自動化するための手法が多く研究されている。
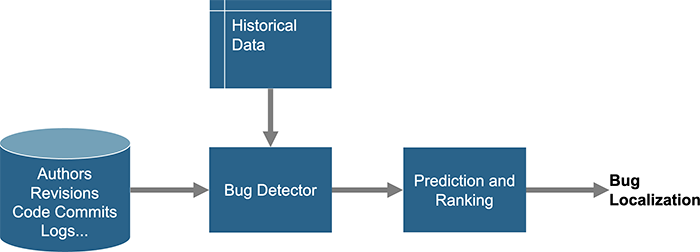
図6. バグ特定
図6.にあるようにコード・リポジトリにはシミュレーション結果やログファイルのみならず、誰がコードを書いたか、どの地域で何時ごろに記述されたものかなど、プロジェクトに関するデータも含まれている。ここから重要なデータを取得し、それを用いてバグディテクタの学習エンジンをトレーニングする。研究では新規コードに対しても、バグの根本的な原因を、特定モジュールの特定ファンクションというレベルまで絞り込むことに成功している。また別の研究では、バグの90%において高精度でローカライズすることができた例も報告されている。ただし使用しているデータが限定的だったという指摘もある。
また静的解析後のレポートの中から機械学習によって擬似エラーを排除し、着目すべきエラー項目やエラーのパス名を特定する機能等はすでに確立しており、商用EDAツールでも活用することが可能である。
6. Formal Verification
最後の例はFormal Verificationであり、フォーマル・エンジンのオーケストレーションに関するものである。エンジンとはプロパティを解釈し、デザイン構造に対して解を見出すソルバである。フォーマル検証ツールにはさまざまなタイプのデザイン構造やプロパティに対応した多くのソルバーが用意されており、ソルブ能力の向き、不向きを考慮した適用が検証効率を左右する。
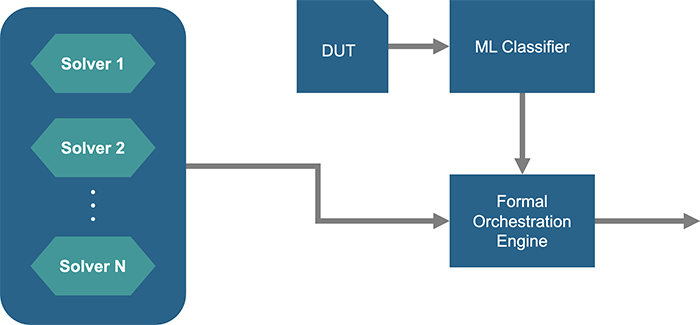
図7. フォーマルエンジンのオーケストレーション
基本的な考え方は、機械学習モデルをトレーニングし、そのモデルがさまざまなプロパティやデザイン構造に対して、どのソルバが適しているかを予測して適用するというものである。例えばある特定のデザインや特定のプロパティでは、ソルバ3がより適していて、それによってより速く証明を行うことができるといった予測を行う。またeventuallyのノーテーションを含むプロパティのソルブには、ソルバ2が適しているといった予測を行う。フォーマル検証ではシミュレーションとは異なり、プロパティと、プロパティが関与するロジックコーンを1つのローカライズされた単位で並列処理することが可能であり、ソルバのオーケストレーションは極めて有効である。この機械学習適用の技術は一部の商用フォーマル検証ツールでは実用化され実プロジェクトにおいて成果を上げている。
機械学習の研究上の課題
機能検証に機械学習を適用するさまざまな研究に共通するいくつかの課題が存在する。ここではその課題についても概説する。
クリーンデータの入手
設計や検証以外のコミュニティ、例えばデータサイエンスのコミュニティで発表される機械学習の論文では、著者らはデータやモデル、コードなどを共有して研究している。しかしながら機能検証における機械学習の研究では、高品質でクリーンなデータがなかなか見つからないという現状があり、大きな制約となっている。研究を進めるためには、自分たちでデータをクリーンな状態にする必要があり、一般的にはデータの準備段階そのものに全体の7割の時間を費やすとも言われている。これは同時に研究結果の再現性が低いという問題にもつながる。ある論文において、機械学習の効果として95%の再現性が得られたとする研究結果があっても、それを論文の読者が再現できるかというと、オリジナルのデザインを持っていないため再現はかなり難しい。そして共通のデータにアクセスできないという問題点は、データ量の問題にもつながる。機械学習モデルをトレーニングするためのデータが限られるため、強力で高度なモデルの作成が困難となる状況がある。
この課題に対する1つの解が、オープンソースのプロジェクトである。図8にGitHub、RISC-V、OpenCoresなどから入手可能なプロジェクト数と、機械学習適用までの処理を示す。

図8. オープンソースのプロジェクト数と機械学習適用までの処理
この図にあるように、データ量としては数多くのデザインやテストベンチが存在するものの、機械学習のためのデータとして活用するには、多くの準備作業に時間を費やさなくてはならない。基本的に機能検証を機械学習の対象とするため、実際に検証してはログファイルを残したり、他のフォーマットに変換したり、あるいはコードにラベル付けをしたりといった準備作業は、かなり膨大になる。コミュニティとしてこの膨大な作業を負担することができれば、共有可能なクリーンなデータを容易に入手することができ、機械学習適用の研究の加速が期待できる。ただしアカデミアではなく商用で使う場合には、必ずしもすべてのライセンスが許可されているわけではないという点にも注意を払う必要はある。
モデルの汎用性とコスト
機械学習のモデルの評価には汎用性という指標が重要である。モデルは大雑把に "Rote Modeling" – 丸暗記型モデルと、"Generalizable Model" – 生成可能型モデルとに分けられる。生成可能型モデルは汎用性が高く、トレーニングデータによって学習したモデルを、これまで経験したこともない課題に対しても、容易に適用することができる。逆に丸暗記型モデルではトレーニングにおいて特定タイプのデザイン、コーディングスタイル、特定のプロジェクト、または特異性があるデータを使ってしまうため、それ以外のタイプのデザインやコーディングスタイルでは再現性が低くなってしまう。汎用性が低い研究結果は、産業界においては価値が限定されてしまう。
生成可能型モデルをトレーニングする際に重要な要素は、精緻化レベルである。言語モデルではchat GPTが多く参照されるが、GPT3のレベルであってもインターネットから5045テラバイトのデータを使っている。さらに精緻化のレベルによって、必要なデータ量が変わってくるため、トレーニングに要する予算も左右される。同じくGPT3のトレーニングに約500万ドルを要している。すべての研究チームにそのような予算と時間があるわけではなく、モデルの精緻化が必要な場合には、大規模な研究チームとの連携も選択肢として視野に入れておく必要があるかも知れない。
まとめ
機械学習は機能検証のさまざまな側面で適用することが可能であり、機能検証の質と生産性を高める上でブレイクスルーとなる可能性を秘めている。機能検証では多くのデータが生成されることから機能検証は機械学習適用に適しているものの、これまでのさまざまな研究にはクリーンなデータの入手、モデリングの精緻化とコストのトレードオフなど、解決すべき課題は多い。機能検証に機械学習を適用する上で、業界が共通のインフラストラクチャを整備していくことは極めて重要であると言える。
参考文献
[1] Dan Yu, et al. "A Survey of Machine Learning Applications in Functional Verification." Proceedings of the Design and Verification Conference (DVCon US) 2023
[2] Gogri, Saumil, et al. "Machine Learning-Guided Stimulus Generation for Functional Verification." Proceedings of the Design and Verification Conference (DVCON US) 2020
-
「Design and Verification Landscape」技術情報メールニュース
-
PALTEKでは本ブログ「Design and Verification Landscape」シリーズの技術情報をメールで年に3-4回発信しています。
ご登録いただいた方には、最新の情報をメールニュースとしてお届けします。
ご希望の方はこちらのフォームよりご登録ください。※競合製品取り扱い企業様の申込については、お断りする場合がありますので予めご了承ください。
このブログのシリーズ一覧は下記になります。是非あわせてお読みください。




















